'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M14.8889%2014.5288L17.1111%2016.751M37.1111%2014.5288L34.8889%2016.751M37.1111%2036.751L34.8889%2034.5288M14.8889%2036.751L17.1111%2034.5288M14.8889%2030.0844H16.5556M21.5556%2014.5288V16.1955M37.1111%2021.1955H35.4445M30.4445%2036.751V35.0844M32.6667%2030.0844H36.5556M30.4445%2014.5288V18.9733M14.8889%2021.1955H19.3334M21.5556%2036.751V32.3066M25.3715%2020.7129L21.073%2025.0114C20.853%2025.2314%2020.743%2025.3414%2020.7018%2025.4682C20.6655%2025.5798%2020.6655%2025.7%2020.7018%2025.8116C20.743%2025.9384%2020.853%2026.0485%2021.073%2026.2685L25.3715%2030.5669C25.5915%2030.7869%2025.7015%2030.897%2025.8284%2030.9382C25.9399%2030.9744%2026.0601%2030.9744%2026.1717%2030.9382C26.2986%2030.897%2026.4086%2030.7869%2026.6286%2030.5669L30.927%2026.2685C31.1471%2026.0485%2031.2571%2025.9384%2031.2983%2025.8116C31.3345%2025.7%2031.3345%2025.5798%2031.2983%2025.4682C31.2571%2025.3414%2031.1471%2025.2314%2030.927%2025.0114L26.6286%2020.7129C26.4086%2020.4929%2026.2986%2020.3829%2026.1717%2020.3417C26.0601%2020.3054%2025.9399%2020.3054%2025.8284%2020.3417C25.7015%2020.3829%2025.5915%2020.4929%2025.3715%2020.7129Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1138_16885'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1138_16885'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1138_16885'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1138_16885'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Schematron 3B
Schematron-3B is a state-of-the-art large language model designed for reasoning and complex problem-solving tasks, with a focus on accuracy and efficiency in various domains, offering advanced capabilities for structured output generation and complex reasoning.


Schematron 3B has been replaced by Schematron V2 Turbo
All requests sent to inference-net/schematron-3b are now automatically routed to inference-net/schematron-v2-turbo. V2 pricing applies — see the V2 model page for current rates. Update your code to call the V2 identifier directly so your dashboards reflect the model you intend to use.
Scrape millions of webpages on a budget
Deliver frontier-model accuracy at prices that make sense for production workloads

Meet with our research team
Schedule a call with our research team to learn more about how Specialized Language Models can cut costs and improve performance.

Documentation · Serverless API · Announcement blog
Model Overview
Welcome to the Schematron series, Inference.net's long‑context extraction models specialized in converting noisy HTML into clean, typed JSON that conforms to your custom schema. The Schematron series was purpose‑trained for web scraping, data ingestion, and transforming arbitrary pages into structured records.
We're releasing these models in two different sizes:
- Schematron‑8B — marginal quality lift on harder/longer pages
- Schematron‑3B — recommended default; near‑parity quality at ~50% cost of Schematron-8B
NOTE
This model card is dedicated to the smaller Schematron-3B model. Check out Schematron-8B for the larger model.
I/O at a glance
- Input: Cleaned HTML + JSON Schema (can be extracted from typed model like Pydantic/Zod)
- Output: Strictly valid JSON conforming to the provided schema (no narration)
NOTE
The JSON Schema passed as input needs to conform to the schema.org schema.
Highlights
- Schema-first extraction: 100% schema‑conformant JSON outputs
- Long context: Robust to lengthy, noisy HTML (up to 128K tokens)
- Variants: 3B (default, most cost‑efficient) · 8B (marginal quality lift at ~2× cost)
Model Details
- Family: Schematron (3B and 8B)
- Context window: Up to 128K tokens
- Input: Cleaned or raw HTML and a JSON Schema
- Output: Strict JSON that conforms to the provided schema
Benchmarks
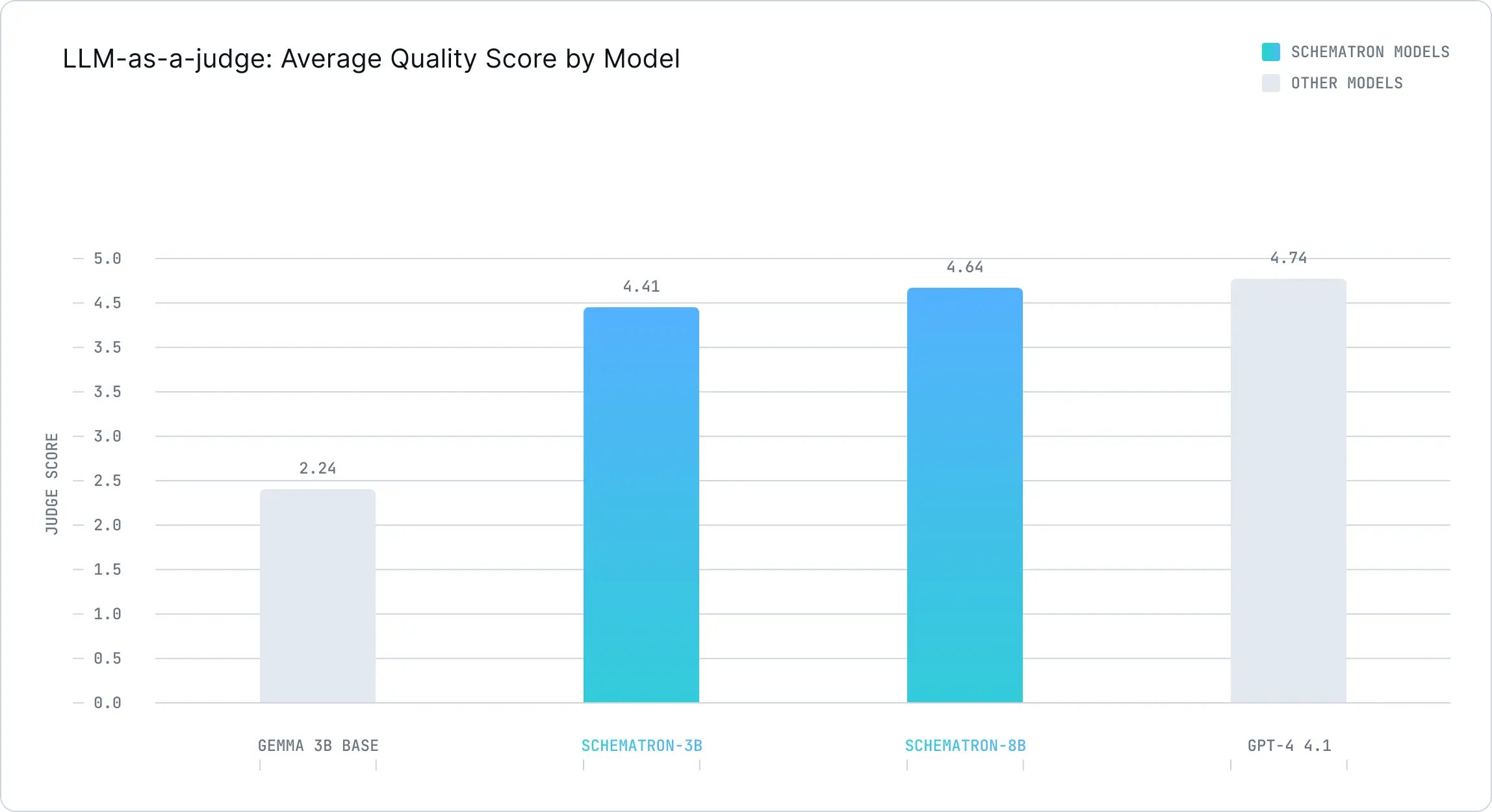
HTML-to-JSON Extraction Quality
We evaluated extraction quality using Gemini 2.5 Pro as a judge, scoring extractions from 1-5 where 5 represents perfect extraction.
| Model | LLM-as-Judge Score |
|---|---|
| GPT-4.1 | 4.74 |
| Schematron-8B | 4.64 |
| Schematron-3B | 4.41 |
| Gemini-3B-Base | 2.24 |
Web-Augmented Factuality on SimpleQA
We evaluated Schematron's real-world impact on LLM factuality using SimpleQA.
Test Pipeline:
- Query Generation: Primary LLM (GPT-5 Nano or GPT-4.1) generates search queries and defines extraction schema
- Web Search: Search provider (SERP or Exa) retrieves relevant pages
- Structured Extraction: Schematron extracts JSON data from retrieved pages using the schema
- Answer Synthesis: Primary LLM produces final answer from structured data

Key findings:
- Web search paired with JSON extraction improves factuality: Adding Schematron with web retrieval improves GPT-5 Nano's accuracy from 8.54% to 82.87%—nearly a 10x improvement
- Search provider matters: Exa (82.9%) significantly outperforms SERP (64.2%) for factual retrieval, while also being more cost-effective
- Structured extraction beats raw HTML: Processing raw HTML would require 100k+ tokens for 10 searches; Schematron's JSON extraction reduces this by orders of magnitude
- Small specialized models win: Schematron-8B (82.87%) outperforms the much larger Gemini 2.5 Flash (80.61%) on this task, showing that fine-tuning for well-defined tasks beats general purpose models
- Performance scales with model quality: When paired with GPT-4.1, Schematron achieves 85.58% accuracy, showing the approach benefits from stronger base models
Minimal Quickstart
Use these local snippets to prepare HTML and compose a schema‑guided prompt. The model returns strictly valid JSON; validate it against your schema downstream.
from lxml.html.clean import Cleaner
import lxml.html as LH
HTML_CLEANER = Cleaner(
scripts=True,
javascript=True,
style=True,
inline_style=True,
safe_attrs_only=False,
)
def strip_noise(html: str) -> str:
"""Remove scripts, styles, and JavaScript from HTML using lxml.
"""
if not html or not html.strip():
return ""
try:
doc = LH.fromstring(html)
cleaned = HTML_CLEANER.clean_html(doc)
return LH.tostring(cleaned, encoding="unicode")
except Exception:
return ""
Compose messages with your schema and cleaned HTML:
def construct_messages(schema: str, html: str):
"""Construct messages for a schema‑guided extraction request."""
response_prompt = {
"prompt_part_one": (
"You are going to be given a JSON schema following the standardized JSON "
"Schema format. You are going to be given a HTML page and you are going "
"to apply the schema to the HTML page however you see it as applicable "
"and return the results in a JSON object. The schema is as follows:"
),
"prompt_part_two": "Here is the HTML page:",
"prompt_part_three": "MAKE SURE ITS VALID JSON.",
}
user_prompt = (
response_prompt['prompt_part_one']
+ "\n\n" + schema + "\n\n"
+ response_prompt['prompt_part_two']
+ "\n\n" + html + "\n\n"
+ response_prompt['prompt_part_three']
)
return [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": user_prompt},
]
NOTE
In the serverless API there's no need to pass anything but the HTML. We handle the prompt formatting for you.
Recommendations
- Temperature 0 and JSON mode for deterministic, parseable output
- Validate responses against your schema (e.g., Pydantic or Zod)
- Pre‑clean HTML (remove scripts/styles) when possible; avoid over‑aggressive removal
- Using lxml to clean the HTML is not required, but is recommended as it matches the training data.
Limitations
- Static HTML only; render client‑side content upstream
- Very large pages may require truncation
- Ambiguous fields depend on schema clarity; be explicit in field descriptions
Safety and Responsible Use
- Extracted data may include personal or sensitive information present in the page—handle and store responsibly
- Respect site terms, robots.txt, and applicable laws
- Use downstream validation and guardrails for compliance
License
See license in the metadata above.
