'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Introduction
There's a quiet revolution happening inside the fastest-growing AI-native companies right now.
Not long ago, companies like Cursor, Harvey, Decagon, and Cal AI were dismissed as "GPT-wrappers," products that relied so heavily on models from frontier labs like OpenAI that many thought they would never become viable businesses of their own. To some extent, this makes sense: if the models provide the capabilities these products couldn't exist without, doesn't it stand to reason that most of the value generated would flow back to the frontier labs in one way or another?
This mindset underestimated how quickly these companies would understand that the real asset wasn't the model, but the data their users were generating. Today, all of the companies above have removed their dependence on frontier labs, trained their own language models, and are using them to power core functionality inside their products. They are investing in in-house teams and systems to improve model capabilities well into the future.
This is the future we see at Inference.net. In 2026 and beyond, more companies will realize that small, customized LLMs can match frontier quality for a fraction of the cost. The days of renting capabilities are numbered. Companies that want long-term defensibility will own their models and data flywheels that power them.
Big Token
Models like Opus 4.5, GPT-5.2, and Gemini 3 offer incredible capabilities that span a wide range of tasks. These behemoths can write code, solve decades-old math problems, and wax poetically about the nature of human consciousness. They're undoubtedly changing the world in new and interesting ways, and the leverage these models provide feels nearly unlimited, save for one small constraint: access is gated by the paywalls and policies of 'Big Token'—Anthropic, OpenAI, and Google.
You can use them, for a fee, for now. As long as you behave in the eyes of their creator, they will gladly rent you metered access to these wonderful capabilities.
Being a customer of these companies is a precarious position. If you build a product on their APIs, you are at the mercy of some of the most aggressive and growth-hungry organizations in the world. There is no limit to their aspirations, no telling when model performance would degrade without warning, and nowhere to run except into the clutches of their competitors.
The trap is threefold:
- Performance. Models change silently. You debug for days before realizing the problem isn't your code. There's no telling when model performance will degrade without warning.
- Price. Your unit economics are hostage to their pricing decisions. Some significant percentage of your revenue will be carried out the front door of your house every week.
- Policy. Terms of service change without warning. On-prem deployments cost tens of millions and are only available to the largest companies in the world.
You are feeding their flywheel. Every request you send through OpenAI or Anthropic is valuable data you're handing over for free. They'll use it to improve their models. Your competitors, also using those APIs, get the benefit.
This data doesn't just let them grow their model. It lets them specialize in your domain. They see which verticals are generating the most value, which use cases are sticky, and which markets are worth entering.
This is the world Big Token wants you to live in: Rent access to their models forever, pay by the token, and pray that they don't take a liking to your market.
The Heresy That Was DeepSeek
This changed in December 2024.
Open-source LLMs, such as DeepSeek V3 and later DeepSeek R1, put massive downward pressure on the prices Big Token could reasonably charge its customers. By offering the first viable alternative to closed-source frontier models, DeepSeek gave ambitious companies a realistic path to fine-grained control over the models powering their products in production.
Startups could swap their OpenAI usage to open-source models with a two-line code change. Larger companies began renting their own GPUs directly and deploying these models on vLLM or SGLang, expanding control over their AI infrastructure.
DeepSeek gave developers a small taste of what freedom felt like.
But it introduced new problems. By spring 2025, Big Token had produced models that were noticeably more capable. DeepSeek was more affordable, but still expensive at scale. And serverless inference providers started pushing hard to lock teams into year-long contracts in order just to access the rate limits required to run a production application.
Choose: pay a premium for the very best models, or use a cheaper model, take the quality hit, and hope your customers don't leave for a competitor who chose option one. Pay the piper, or have your product designated B-tier.
Or realize quality lies not in the underlying model, but in the underlying data. Your data.
Building Your Model Moat
2026 will be the year of the small, specialized, frontier-quality LLM. You will build it in the same way software has been built for decades: through observing from your users and iterating relentlessly.
This is what we call the flywheel. The core loop works like this:
- You start with a generalist model powering your product.
- Users interact with it.
- Those interactions generate data.
- You use that data to train a specialized model.
- The specialized model performs better.
- Better performance attracts and retains users.
- More users, more data. The cycle accelerates.
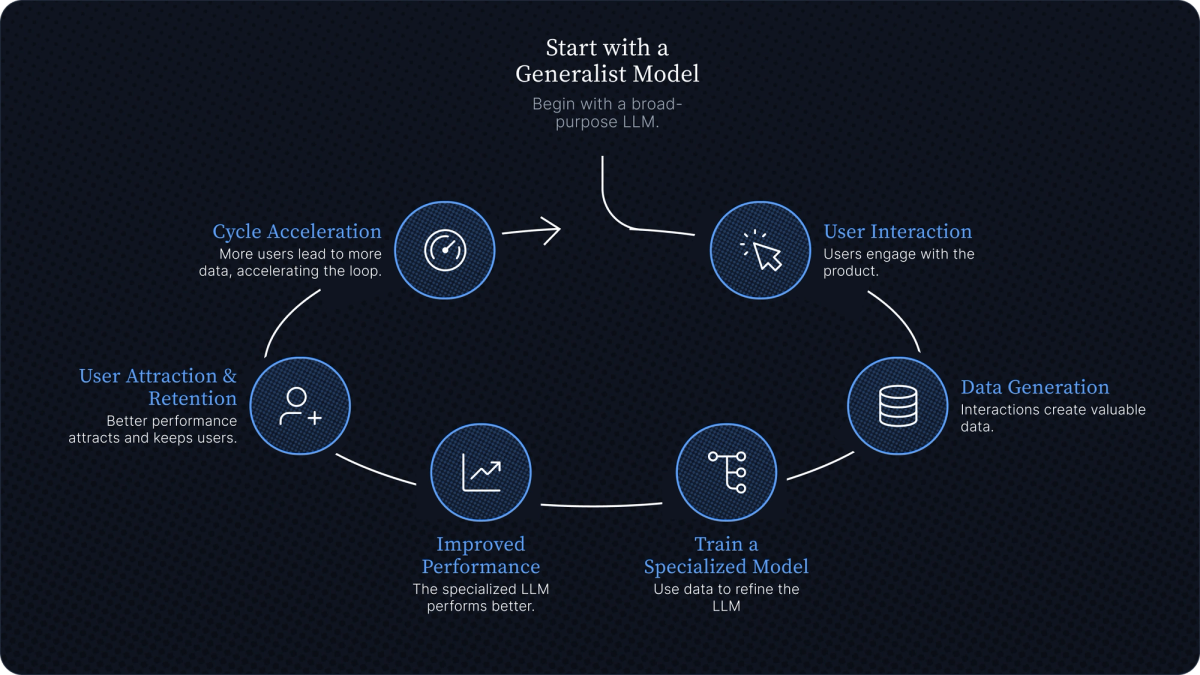
This is a moat. Not a moat made of brand recognition or network effects or regulatory capture. A moat made of data that literally cannot be recreated without your application and your users.
A competitor could start with the same base model tomorrow. They could raise more money than you. But they can't conjure the dataset you've built through months of production traffic and user feedback. And if you're improving faster than they can catch up, the gap only widens.
Here's what most teams miss: if you have users, you're already generating this data. This is the easy part. The more difficult part is using that data to build an effective flywheel that compounds value back into your company over time.
The Flywheel as Product Philosophy
More than just a technical decision, building a flywheel is an entire product philosophy. Two questions should guide every decision:
- How can you design features that generate high-quality data as a natural byproduct of usage?
- How can you incentivize high-value users to provide high-quality feedback?
Every interaction becomes an opportunity to learn:
| Product Type | Signal Captured | How It Works |
|---|---|---|
| Calorie tracking app | Labeled correction examples | Users correct AI estimates, creating ground truth data for retraining |
| Coding assistant | Acceptance/rejection patterns | Tracks which suggestions get accepted, modified, or rejected by developers |
| Support bot | Resolution metrics | Measures which responses resolve issues vs. trigger escalation to humans |
Every code suggestion that gets accepted or rejected. Every support ticket that resolves or escalates. Every calorie estimate that gets corrected. It's all signal. For you.
Not all user feedback is equally valuable. A registered dietitian correcting calorie estimates is worth more than a casual user guessing. A senior engineer's code edits offer more signal than someone who just started coding.
Part of your job is figuring out who your high-value users are and designing feedback mechanisms that capture their input without being annoying. The calorie correction flow should feel like a feature, not a survey. The code acceptance signal should be implicit, not a popup asking "was this helpful?"
Your product is the flywheel. Every design decision either generates valuable data or doesn't. The next question is what you do with that data once you have it.
Post-Training Is All You Need
For years, the frontier labs have successfully pushed the narrative that training models is impossibly hard. You need a team of PhDs, months or years of iteration, and millions in GPU compute.
Convenient story. Increasingly untrue.
What Post-Training Actually Means
The term "post-training" refers to a set of techniques for enhancing the capabilities of an existing model. You take an existing open-source base model, such as DeepSeek, Nemotron, or Gemma, and teach it new tricks. The two most popular techniques are supervised fine-tuning (SFT), where you show the model examples of what you want, and reinforcement learning (RLFT), where you reward it for good outputs. Often it's both.
The most common pattern: start by distilling knowledge from a frontier generalist model like GPT-5 into a small model like Nemotron 9B using SFT. GPT-5 knows how to do your task pretty well. You generate thousands of examples using GPT-5, then train Nemotron to mimic those outputs. A 9B parameter model trained with SFT on high-quality distilled data can match the quality of GPT-5 for a specific task.
The result is a specialized model. Not a general-purpose assistant that can write poetry, debug code, and plan your vacation. Just a model that does one thing very well. Maybe it extracts structured data from invoices. Maybe it captions medical images. Maybe it scores leads based on email conversations.
Next, you can use RLFT – this is the most viable path to training a model to go beyond the capabilities of frontier models. With SFT, you're fundamentally capped by the quality of your training examples. The student can only be as good as the teacher. But with RLFT, you're rewarding outcomes instead of mimicking demonstrations. The model learns to optimize directly for what you actually care about, rather than learning to sound like something that optimizes for what you care about.
The Economics
You can train a specialized model in about an hour for a few hundred dollars. That includes the cost of data generation, compute, and evaluation. That's all you need to own the core capabilities that power your product.
Own, as in:
- The weights live on your infrastructure
- You can modify them however you want
- You're not subject to anyone's terms of service
- The model is your asset, owned by you.
Why Now?
This has been possible for a few years, but only recently has the barrier to entry been low enough for most teams to adopt. A few things were missing.
Evaluation. LLM evaluation is genuinely hard. How do you know if your custom model is actually good? For decades, this was a problem only researchers worried about. It took time for the tooling and best practices to catch up. Today, most teams use some combination of LLM-as-judge, where a frontier model grades your model's outputs, and golden datasets, hand-curated collections of examples you know are correct. The first approach scales. The second provides ground truth. You need both.
Data generation. A big part of training a specialized model is creating training data from frontier models. Running hundreds of thousands of inference calls meant setting up GPUs, managing inference batches, building or integrating with inference APIs, and formatting data for training. And even after all that work, how do you know your synthetic data actually represents the task you're training for? Recent improvements to GPT-5, Claude, Kimi K2 and other models have given us a reliable method to generate training data for a wide variety of tasks. The teachers got better, so the students can too.
Mental model. Teams treated models as static assets. Train once, deploy, move on. But products evolve. Users change. Features get added. The distribution of requests your model sees in month six looks nothing like month one. The model slowly degrades, and nobody notices until customers start complaining.
The new mental model is continuous improvement. You monitor production traffic. You compare what your model is seeing against what it was trained on. When the distribution drifts, you generate new data and retrain. The model becomes a living part of your system rather than a frozen artifact.
Building Your Model Flywheel
You want to capture your data flywheel rather than donate it to Big Token. How do you actually do it?
The core requirement is that your training pipeline needs access to production data. Inference and training don't need to live in the same system, but it helps. When production logs flow directly into training infrastructure, you eliminate the friction of moving data around, reformatting it, and keeping everything in sync. The tighter the loop, the faster you iterate.
You need subsystems that monitor and analyze production traffic automatically:
- Distribution drift, when the requests your model sees start looking different from what it was trained on
- Outliers worth investigating
- High-value corrections from users
These systems should flag issues and surface opportunities without requiring someone to manually review every data point. Some human oversight is fine. But if the loop requires constant babysitting, it won't survive contact with reality.
Retraining cadence depends on your application and data volume. Could be daily, weekly, monthly. The point is that it's a process, not an event. You're not training a model. You're operating one.
Are You Ready For Your Own Model?
If you're building an AI-native product and you're not thinking about model ownership, you're leaving value on the table.
The best teams building the fastest-growing companies are already training specialized models to power their core workflows. This doesn't mean abandoning frontier models entirely. Most companies will run specialized models alongside generalis. Specialized models handle constrained, high-volume tasks where success can be clearly defined. Generalist models handle orchestration, edge cases, and anything requiring broad world knowledge.
The bootstrapping path is straightforward. Start with generalists. Validate your product idea. Generate initial training data. Once you're spending $1,000 a month on API calls, you have enough volume to consider your first specialized model.
You don't need to boil the ocean. Pick your highest-volume, most constrained task and start there. This is where you build your own moat.
What We've Learned
We didn't arrive at these beliefs abstractly. We've spent the past year training specialized models for companies like Profound and Cal AI, learning what works and what doesn't. The patterns described above are distilled from operating real production systems processing trillions of tokens per month.
We've seen a calorie-tracking app cut inference costs by 80% while improving accuracy by 15% because user corrections were fed directly into model improvements. We've watched a coding assistant go from "occasionally useful" to "accepted 70% of the time" after three retraining cycles. The flywheel is real. The economics are real.
We've taken those learnings and built Inference Catalyst — a platform for training, inference, and monitoring designed to make flywheels possible at any scale. The platform will be available publicly in mid-February.
If any of this resonates, get in touch. We'd love to hear about what you're building.
Meet with our research team
Schedule a call with our research team to learn more Specialized Language Models can cut costs and improve performance.