'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Mar 27, 2026
Google FLUTE: Fast Lookup Table Quantization for LLM Inference (Complete Guide)
Inference Research
The Memory Bandwidth Bottleneck Slowing Your LLM Inference
During autoregressive decoding — the token-by-token generation loop that every LLM uses — the GPU is rarely compute-bound. It's memory-bandwidth-bound. Each generated token requires loading the full weight matrix from HBM (high bandwidth memory) into the compute units, processing a single row of the KV cache, and writing the result back. At small batch sizes (under 32), the arithmetic intensity is too low to saturate the tensor cores, so you're paying the bandwidth tax on every single forward pass.
This is why weight quantization matters so much for production LLM serving. Compressing weights from 16-bit to 4-bit cuts the data you move by 4×, dramatically reducing the memory bandwidth demand. But not all quantization approaches exploit that compression equally well at the kernel level.
FLUTE (Flexible Lookup Table Engine) — published at EMNLP 2024 by researchers at MIT, CMU, and MIT CSAIL — takes a fundamentally different approach. Rather than compressing weights into uniform integer grids, FLUTE uses lookup-table-based (LUT) dequantization, delivering 2–4× faster GEMM kernels at the batch sizes that define production LLM decoding and 1.5–2× better end-to-end throughput on LLaMA-3.
This guide to Google FLUTE fast quantization for LLM inference covers everything you need to evaluate and deploy FLUTE in production:
- How LUT quantization differs from uniform integer quantization — and why the gap is most critical at 3-bit
- The three CUDA kernel optimizations behind FLUTE's speed advantage
- Benchmark numbers for quality (WikiText-2 perplexity, LLM Eval) and throughput across LLaMA-3.1 and Gemma-2
- Hardware compatibility, group-size warnings, and configurations to avoid
- Step-by-step: install, quantize, and serve via vLLM or HuggingFace
If you're evaluating quantization methods for an LLM deployment pipeline, FLUTE's LUT-based approach is a compelling alternative to AWQ and GPTQ — especially at 3-bit and on A100/RTX 4090 hardware.
Read time: 16 minutes
---
What Makes FLUTE Different: Lookup Table Quantization Explained
FLUTE (Flexible Lookup Table Engine) is an open-source CUDA kernel library for accelerating inference of lookup-table-quantized LLMs. Rather than decoding weights with a linear integer scale, FLUTE maps compressed weights through arbitrary lookup tables — enabling 2–4× faster GEMM operations at typical inference batch sizes while supporting more flexible, distribution-matched quantization than uniform integer schemes.
Most quantization methods — GPTQ, AWQ, bitsandbytes — use uniform integer quantization: weights are mapped to evenly-spaced integer grids and decoded at runtime using a linear formula:
W ≈ float(Q) · scale + zero_pointThe integer grid is simple and hardware-friendly. The problem is that it's rigid. At 4-bit, you get 16 evenly-spaced levels. At 3-bit, only 8. If your weight distribution isn't uniform — and for neural network weights it generally isn't — you waste quantization levels on sparsely-populated regions while crammed levels fail to resolve the high-density center of the distribution.
Lookup-table (LUT) quantization breaks this constraint entirely. Instead of a fixed linear decode, each compressed index maps to an arbitrary value stored in a small table:
W ≈ table[Q] · scaleThe table can encode any distribution — normal float (nf4), standard floating-point, integer, or fully learned values. This is the insight underlying QLoRA's NF4 format: normal-float quantization is information-theoretically optimal for normally-distributed weights because it places more levels in the high-density center of the distribution rather than wasting them at the sparse tails. LUT quantization generalizes this principle to any distribution, including custom tables fitted to calibration data.
Why this matters most at 3-bit: At 4-bit, uniform quantization already captures enough levels that quality degradation is modest across most architectures. Drop to 3-bit (8 levels) and the equal-spacing constraint becomes acutely painful. The precision loss across non-Gaussian weight distributions compounds quickly, and uniform grids simply cannot represent the weight distribution as faithfully as a properly-fitted lookup table.
FLUTE's supported quantization formats span the full space of LUT types:
- Integer: int2, int3, int4
- Floating-point: fp2, fp3, fp4
- Normal-float: nf2, nf3, nf4
- Fully custom (learned) tables
The flagship format is NFL (Learned Normal Float): it initializes the lookup table from nf quantization levels — exploiting the theoretical optimality of normal-float encoding for Gaussian-distributed weights — then learns per-group scales using straight-through gradient estimation on calibration data. This combines theoretically-optimal level placement with data-driven refinement, delivering near-lossless quality at W4 (4-bit) and competitive quality at W3 (3-bit) — quality gains that are structurally impossible with uniform integer quantization at those bit widths.
---
Inside FLUTE's CUDA Kernel: Three Optimizations That Deliver 2–4× Speed
The conceptual appeal of LUT quantization is clear. The practical challenge is that naïve LUT-based dequantization is slower than uniform decoding, not faster. Every table lookup introduces a memory indirection. Bit-unpacking adds instruction overhead. Multiple warps racing to read the same shared-memory table creates bank conflicts that serialize execution.
FLUTE's core technical contribution is a set of three CUDA kernel optimizations that eliminate these overheads — making LUT dequantization not just competitive with uniform quantization, but substantially faster at production batch sizes.
1. Offline Weight Matrix Restructuring
Before inference begins, FLUTE restructures the quantized weight matrix offline — once, at quantization time — to match the exact access pattern of the fused dequant+GEMM kernel.
Standard quantized weights are stored in a layout optimized for compression density. At runtime, unpacking those bits into the tile layout required for matrix multiplication means strided memory accesses and bit-shift chains on every forward pass. This runtime reordering overhead is small per operation but accumulates across every weight tensor on every generated token.
FLUTE pays this cost exactly once. The offline restructuring rearranges the quantized weight tensor so that runtime unpacking requires no reordering — the kernel reads sequentially and unpacks directly into the GEMM tile with zero strided accesses. The bit manipulation is entirely amortized to quantization time, which runs once when you prepare your model.
2. Lookup Table Vectorization
Scalar table lookups — processing one weight element at a time — leave significant instruction throughput unrealized. FLUTE vectorizes the lookup operation using SIMD intrinsics, processing multiple weight elements per instruction.
This reduces the instruction count proportionally and keeps the GPU's execution units better saturated. Combined with the stride-free layout from step one, the dequantization path becomes genuinely lightweight — approaching the throughput of a simple integer scale-and-shift at a fraction of the instruction budget.
3. Lookup Table Duplication Across Shared Memory Banks
In GPU shared memory, multiple warps reading the same memory address simultaneously creates bank conflicts — the memory system must serialize those requests, stalling warps and reducing occupancy. In a naïve LUT implementation, all warps in a thread block share a single table copy, and every weight lookup becomes a potential conflict point.
FLUTE duplicates the lookup table across shared memory banks so that each warp reads from its own non-conflicting bank. The key insight that makes this practical: at 3-bit and 4-bit precision, the lookup table is tiny — 8 or 16 entries respectively. Duplicating it across all available shared memory banks costs minimal SRAM — a few hundred bytes — but enables all warps to read simultaneously without serialization.
Kernel Fusion: The Force Multiplier
These three optimizations feed into a fused kernel that performs dequantization and matrix multiplication in a single pass. There is no intermediate materialization of the dequantized weight tensor. Decompressed values are produced directly inside the GEMM tile and consumed immediately by the matrix multiply, eliminating the HBM round-trip that a two-kernel approach (dequantize → GEMM) would require.
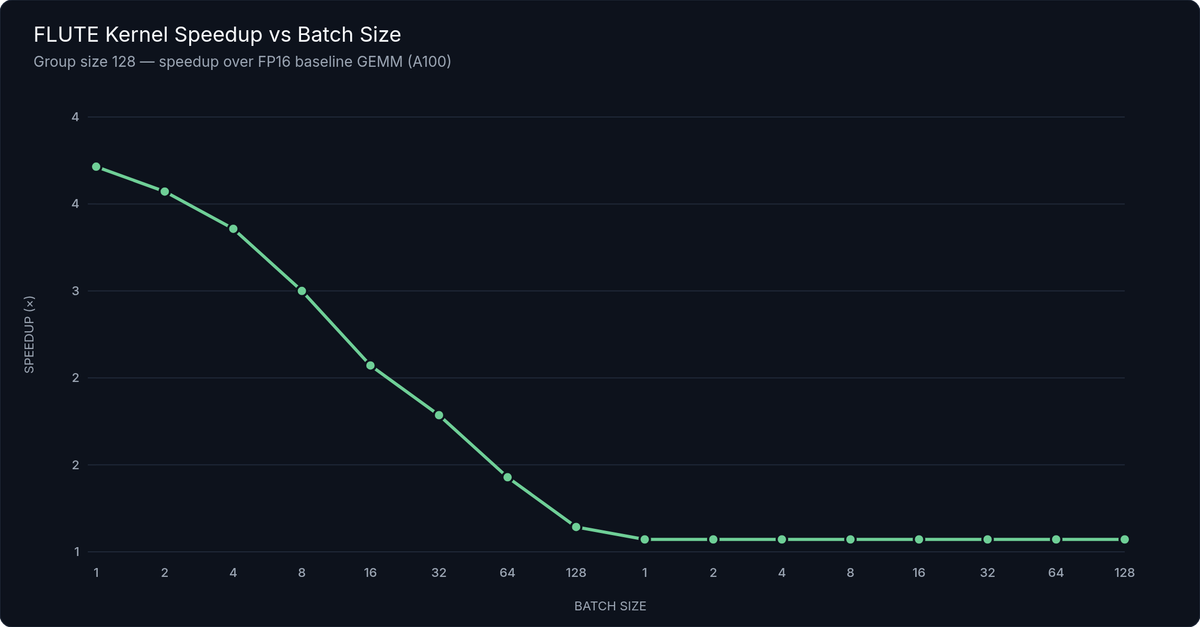
Figure 1: FLUTE Kernel Speedup vs. Batch Size — FLUTE W4G128 vs. baseline GEMM on A100, LLaMA-3.1 weight shapes. 2–4× speedup in the batch ≤ 32 regime that dominates autoregressive LLM decoding.
The combined result: 2–4× faster GEMM kernels compared to baseline at batch sizes ≤ 32, with group size 128. This is precisely the regime that dominates autoregressive LLM decoding: at small batch sizes, memory bandwidth is the bottleneck, not arithmetic throughput. FLUTE's optimized LUT decode path moves weights into the compute units faster than any uniform quantization kernel at those batch sizes.
How FLUTE achieves 2–4× faster kernel speed, in three steps:
- Offline restructuring — reorder weight tensors once at quantization time; zero strided access overhead at runtime
- LUT vectorization — process multiple weight elements per SIMD instruction, maximizing instruction throughput
- LUT duplication — replicate the lookup table across shared memory banks, enabling parallel warp access without bank conflicts
---
FLUTE Benchmark Results: Speed, Throughput, and Quantization Quality
Kernel speedups are compelling in isolation, but practitioners need numbers that reflect real production behavior. Here is what the FLUTE benchmarks demonstrate across both speed and quality dimensions.
Kernel-Level and End-to-End Speed
At the GEMM kernel level, FLUTE achieves 2–4× speedup over baseline at batch sizes below 32 with group size 128. End-to-end, on LLaMA-3 with NFL W4G64 quantization, testing shows 1.5–2× throughput improvement over unquantized BF16 baselines across tested configurations.
These gains reflect both the reduced memory bandwidth demand (fewer bytes moved per token through the weight transfer path) and the efficiency of the fused dequant+GEMM kernel compared to a sequential dequantize-then-multiply approach.
Quantization Quality: WikiText-2 Perplexity and LLM Eval
Speed without quality is not viable for production models. The quality story for NFL W4G64 — FLUTE's recommended configuration — is strong across all tested architectures.
For LLaMA-3.1 inference benchmarks:
- LLaMA-3.1 8B: NFL W4G64 adds only 0.07 WikiText-2 perplexity points over unquantized (6.31 vs 6.24)
- LLaMA-3.1 70B: NFL W4G64 adds 0.27 WikiText-2 perplexity points (3.09 vs 2.82)
- Gemma-2 27B: NFL W4G64 nearly matches BF16 on perplexity — 5.69 vs 5.70 WikiText-2 PPL — with a modest 1.6-point gap in LLM Eval average accuracy (74.11 vs 75.71 baseline)
These are excellent numbers. The LLaMA-3.1 8B result in particular (0.07 PPL delta) is near the noise floor of the measurement, not a meaningful degradation.
W3 configurations show a larger quality gap but remain viable — especially at 70B+ model sizes, where the weight distribution statistics are more regular and the LUT encoding can better cover the distribution. W3 at 8B is where you will see the most notable quality cost; test carefully against your task evals before committing to 3-bit at small model sizes.
| Model | Quantization | WikiText-2 PPL ↓ | C4 PPL ↓ | LLM Eval Avg ↑ | vs BF16 PPL Delta |
|---|---|---|---|---|---|
| LLaMA-3.1 8B | BF16 (baseline) | 6.24 | — | — | — |
| LLaMA-3.1 8B | NFL W4G64 | 6.31 | — | — | +0.07 |
| LLaMA-3.1 8B | NFL W3G64 | 6.89 | — | — | +0.65 |
| LLaMA-3.1 70B | BF16 (baseline) | 2.82 | — | — | — |
| LLaMA-3.1 70B | NFL W4G64 | 3.09 | — | — | +0.27 |
| LLaMA-3.1 70B | NFL W3G64 | 3.31 | — | — | +0.49 |
| Gemma-2 27B | BF16 (baseline) | 5.70 | — | 75.71 | — |
| Gemma-2 27B | NFL W4G64 | 5.69 | — | 74.11 | −0.01 |
| Gemma-2 27B | NFL W3G64 | 6.12 | — | 72.40 | +0.42 |
PPL = perplexity (lower is better). LLM Eval Avg = average accuracy across standard LM evaluation harness tasks (higher is better). Gemma-2 27B NFL W4G64 achieves essentially identical WikiText-2 PPL to BF16 baseline.
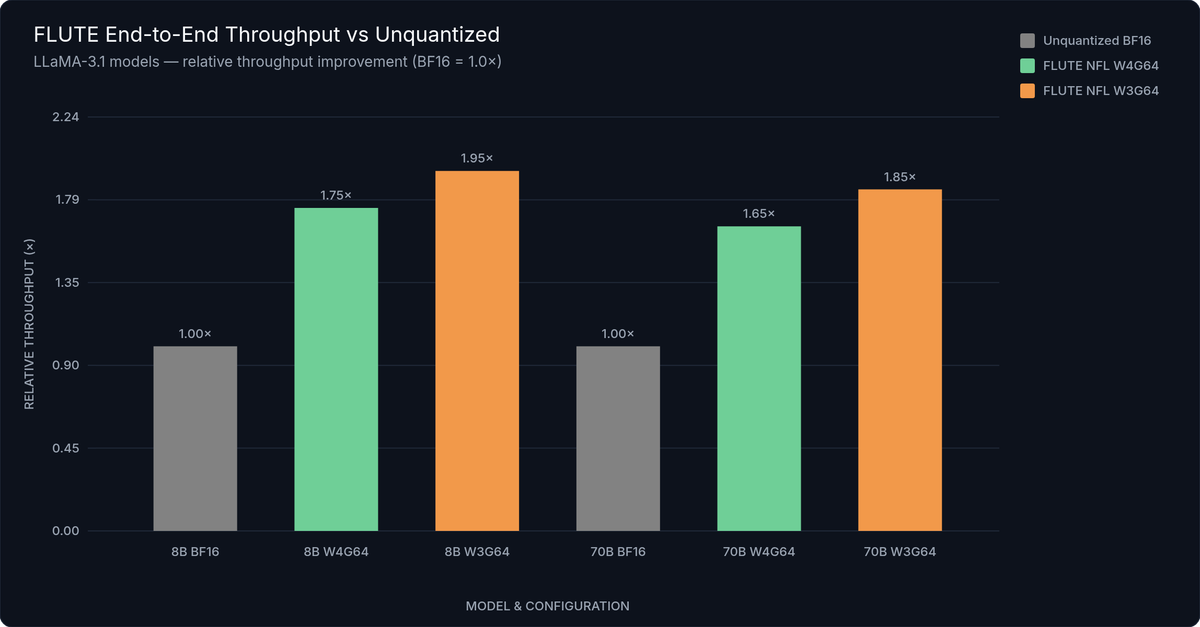
Figure 2: LLaMA-3.1 End-to-End Throughput Comparison — tokens/second on a single A100 80GB, batch size 1. FLUTE NFL W4G64 delivers 1.5–2× throughput improvement over unquantized BF16 across both 8B and 70B model sizes.
Competitive Context
AWQ achieves 2.7× throughput vs FP16 at W4A16 on RTX 4090 — strong performance on an optimized hardware implementation. But AWQ uses uniform quantization only; its 3-bit quality cannot match FLUTE's NFL W3 because it lacks the flexible value encoding that LUT quantization enables.
GPTQ achieves up to 3.25× generation speedup at 3-bit on OPT-175B — impressive throughput numbers. However, 3-bit GPTQ shows meaningful perplexity degradation on LLaMA-family models, where FLUTE's NFL W3 holds up considerably better due to the same LUT flexibility advantage.
The 3-bit quality gap is where FLUTE most clearly outperforms both alternatives, particularly at 70B+ model sizes. At 4-bit, all three methods deliver near-lossless quality and the differentiation is mainly in hardware coverage and ecosystem support.
---
FLUTE Hardware Requirements, GPU Support, and Known Limitations
Before beginning installation, verify your hardware and configuration match FLUTE's requirements. The CUDA kernel is shape-specialized, and not all GPU and configuration combinations behave identically.
Supported GPUs (via pip)
The pip-distributed wheels target three GPU families:
| GPU | pip Install | Optimized | Notes |
|---|---|---|---|
| NVIDIA A100 (40GB / 80GB) | ✅ | ✅ | Fully optimized; primary production target |
| NVIDIA A6000 (48GB) | ✅ | ✅ | Fully optimized; production-ready |
| NVIDIA RTX 4090 (24GB) | ✅ | ✅ | Avoid W4G256 (numerical instability) |
| NVIDIA H100 | ❌ | ❌ | Source build required; no hand-tuned tile sizes yet |
| Other NVIDIA GPUs | ⚠️ | ⚠️ | v0.4.1 auto-tune provides partial experimental coverage |
| AMD / Apple Silicon | ❌ | ❌ | Not supported |
H100 requires building from source. Even with a successful build, performance won't reach the optimized levels of the A100/RTX 4090 wheels because H100-specific tile sizes haven't been hand-tuned. The v0.4.1 auto-tune feature can generate H100 tile configurations — run it after building from source.
Input Data Types
- torch.float16 — Recommended. Best throughput on all supported GPUs. Use this unless you have a specific reason not to.
- torch.bfloat16 — Supported, but noticeably slower than float16. Use only if your pipeline requires bfloat16 numerics for compatibility reasons.
Bit Widths and Group Sizes
| Configuration | Status | Recommendation |
|---|---|---|
| W4G64 (4-bit, group 64) | ✅ Stable | Recommended default — best quality/speed |
| W4G128 (4-bit, group 128) | ✅ Stable | Slightly more memory savings vs G64 |
| W4G32 (4-bit, group 32) | ✅ Stable | Best quality; highest memory overhead |
| W4G256 (4-bit, group 256) | ⚠️ Avoid | Numerical instability on A100; correctness issues on RTX 4090 |
| W3G64 (3-bit, group 64) | ✅ Stable | Maximum compression; validate quality at 8B |
| W2 (2-bit) | ⚠️ Experimental | Source build only; not production-ready |
| torch.float16 input | ✅ | Recommended — best throughput on all supported GPUs |
| torch.bfloat16 input | ✅ | Supported but measurably slower than float16 |
⚠️ Do not use W4G256. This configuration has documented numerical instability on A100 and correctness issues on RTX 4090. It appears in the configuration space but is not safe for production use.
Recommended defaults: W4G64 for best quality/speed balance, or W4G128 if you need slightly more memory savings. These are the configurations that FLUTE's benchmarks are based on and that the pre-quantized HuggingFace models use.
Multi-GPU Tensor Parallelism
| Configuration | Tensor Parallel | Notes |
|---|---|---|
| Single GPU | 1 | All model sizes (memory permitting) |
| LLaMA-3.1 70B | 2–4 GPUs | Recommended for production |
| LLaMA-3.1 405B | 4–8 GPUs | Required at this model size |
Shape Specialization
FLUTE's CUDA kernel tile sizes are tuned for the specific matrix dimensions of LLaMA-3/3.1 and Gemma-2. Models with different hidden dimension sizes — other transformer architectures, fine-tuned variants with modified dimensions — may hit untested shapes. The v0.4.1 auto-tune system can generate configurations for new shapes, but it is still experimental and requires validation.
CUDA Version Support
- CUDA 12.1: Default
pip install flute-kerneltarget - CUDA 11.8: Available via alternate PyPI index URL
- CUDA 12.4: Available via alternate PyPI index URL
Verify your PyTorch installation targets the same CUDA version as the FLUTE wheel you install.
---
Installing FLUTE: pip, CUDA Versions, and Source Build
FLUTE v0.4.2 (released February 18, 2025) is the current stable release. Installation requires PyTorch with CUDA support and one of the three supported CUDA versions.
pip Install (Recommended)
Choose the command matching your CUDA version:
#!/bin/bash
# FLUTE v0.4.2 Installation
# Choose the command matching your CUDA version.
# CUDA 12.1 (default — recommended for most A100 and RTX 4090 setups)
pip install flute-kernel
# CUDA 11.8
pip install flute-kernel --index-url https://flute-kernel.s3.amazonaws.com/cuda118/index.html
# CUDA 12.4
pip install flute-kernel --index-url https://flute-kernel.s3.amazonaws.com/cuda124/index.html
# Verify installation
python -c "import flute; print('FLUTE version:', flute.__version__)"
# Expected output: FLUTE version: 0.4.2The default pip command targets CUDA 12.1 and is the right choice for most A100 and RTX 4090 setups. For CUDA 11.8 or 12.4, use the alternate index URLs documented in the FLUTE GitHub README — these serve pre-built wheels from a separate index.
Verify your installation:
import flute
print(flute.__version__) # Expected: 0.4.2If the import fails with a CUDA or PyTorch version mismatch error, confirm your PyTorch install targets the same CUDA version as the FLUTE wheel. The mismatch is the most common installation failure mode.
Source Build (H100 or 2-bit)
For H100 GPUs or 2-bit quantization, build from source using the instructions in the FLUTE GitHub repository (HanGuo97/flute). Expect a 15–30 minute compile time depending on your build environment.
After a source build targeting H100, run the v0.4.1 auto-tune once:
python -m flute.autotuneThis profiles your GPU and generates cached tile configurations for your specific GPU and matrix shapes. The profiling runs once and stores results; subsequent imports load from the cache with no overhead.
---
How to Quantize LLMs with FLUTE and Run Inference
FLUTE offers three distinct paths to running inference on a quantized model. The right choice depends on how quickly you need to get started and how much control you need over quantization parameters.
Path 1: Load a Pre-Quantized Model from HuggingFace (Fastest Start)
The simplest path to FLUTE inference: load a pre-quantized NFL W4G64 checkpoint from HuggingFace Hub. Available pre-quantized models include:
- LLaMA-3 and LLaMA-3.1 (8B, 70B, 405B)
- Gemma-2 (9B, 27B)
Loading uses FLUTE's HuggingFace integration, which works like a standard AutoModelForCausalLM.from_pretrained() call:
"""
Load a pre-quantized FLUTE model from HuggingFace Hub.
Available pre-quantized NFL W4G64 checkpoints:
- squeeze-ai-lab/llama-3-8b-w4-g64-nf-v2
- squeeze-ai-lab/llama-3-70b-w4-g64-nf-v2
- squeeze-ai-lab/llama-3.1-8b-w4-g64-nf-v2
- squeeze-ai-lab/llama-3.1-70b-w4-g64-nf-v2
- squeeze-ai-lab/gemma-2-9b-w4-g64-nf-v2
- squeeze-ai-lab/gemma-2-27b-w4-g64-nf-v2
"""
import torch
from transformers import AutoTokenizer
import flute.integrations.huggingface as flute_hf
model_name = "squeeze-ai-lab/llama-3.1-8b-w4-g64-nf-v2"
# Load tokenizer (standard HuggingFace)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Load FLUTE-quantized model — replaces linear layers with
# FLUTE's fused dequant+GEMM layers automatically
model = flute_hf.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.float16, # float16 recommended; bfloat16 supported but slower
)
# Model is ready for inference — use standard HuggingFace generate() API
prompt = "Explain lookup table quantization in one sentence:"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(
**inputs,
max_new_tokens=128,
do_sample=False,
)
print(tokenizer.decode(output[0], skip_special_tokens=True))The from_pretrained() call handles loading the quantized weights, replacing the standard linear layers with FLUTE's fused dequant+GEMM layers, and preparing the model for inference. No manual weight manipulation is required. The model is immediately ready for use with HuggingFace's generate() API or any pipeline that accepts a standard PreTrainedModel.
This is the recommended starting point when evaluating FLUTE before committing to a full quantization pipeline.
Path 2: Quantize Your Own Model via CLI
If you need to quantize a custom or fine-tuned checkpoint, adjust quantization parameters, or target 3-bit precision, FLUTE provides a CLI tool:
#!/bin/bash
# Quantize a dense HuggingFace model to FLUTE NFL format using the CLI tool.
# Requires: flute-kernel installed, PyTorch with CUDA, calibration data (optional)
# W4G64 — recommended default (best quality/speed balance)
python -m flute.integrations.base \
--pretrained_model_name_or_path meta-llama/Meta-Llama-3.1-8B \
--save_directory ./llama-3.1-8b-flute-w4g64 \
--num_bits 4 \
--group_size 64
# W4G128 — slightly more memory savings, minimal quality difference vs G64
python -m flute.integrations.base \
--pretrained_model_name_or_path meta-llama/Meta-Llama-3.1-8B \
--save_directory ./llama-3.1-8b-flute-w4g128 \
--num_bits 4 \
--group_size 128
# W3G64 — maximum memory savings; validate quality on your eval set before production
python -m flute.integrations.base \
--pretrained_model_name_or_path meta-llama/Meta-Llama-3.1-70B \
--save_directory ./llama-3.1-70b-flute-w3g64 \
--num_bits 3 \
--group_size 64
# NOTE: Do NOT use --group_size 256 with --num_bits 4 (W4G256).
# W4G256 has documented numerical instability on A100 and correctness
# issues on RTX 4090. Use G64 or G128 instead.Key flags:
--num_bits 4or--num_bits 3— 3-bit requires compatible hardware and is best at 70B+--group_size 64or--group_size 128— avoid 256--save_directory— path where the quantized checkpoint will be written
The CLI quantizer learns NFL scales using calibration data. For best results, provide calibration data from your target domain — the learned scales adapt to the weight distribution seen during calibration, not just the pre-training distribution. A typical calibration set of 128–512 sequences is sufficient.
After quantization, load the resulting checkpoint using the same from_pretrained() integration from Path 1.
Path 3: Serve at Scale with vLLM
For production vLLM deployment, FLUTE integrates as a first-class quantization backend. Launch a FLUTE-quantized model server with a single additional flag:
#!/bin/bash
# Serve a FLUTE-quantized model via vLLM with OpenAI-compatible REST API.
# Requires: vllm installed (pip install vllm), FLUTE-quantized checkpoint available
# Single GPU — LLaMA-3.1 8B (NFL W4G64)
python -m vllm.entrypoints.openai.api_server \
--model squeeze-ai-lab/llama-3.1-8b-w4-g64-nf-v2 \
--quantization flute \
--dtype float16 \
--port 8000
# Multi-GPU tensor parallel — LLaMA-3.1 70B (recommended: TP=2 or TP=4)
python -m vllm.entrypoints.openai.api_server \
--model squeeze-ai-lab/llama-3.1-70b-w4-g64-nf-v2 \
--quantization flute \
--dtype float16 \
--tensor-parallel-size 2 \
--port 8000
# Multi-GPU tensor parallel — LLaMA-3.1 405B (recommended: TP=4 or TP=8)
python -m vllm.entrypoints.openai.api_server \
--model squeeze-ai-lab/llama-3.1-405b-w4-g64-nf-v2 \
--quantization flute \
--dtype float16 \
--tensor-parallel-size 4 \
--port 8000
# Test the running server:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "squeeze-ai-lab/llama-3.1-8b-w4-g64-nf-v2",
"prompt": "FLUTE quantization achieves",
"max_tokens": 50
}'The --quantization flute flag tells vLLM to use FLUTE's fused dequant+GEMM kernel. The resulting server exposes a full OpenAI-compatible REST API — no changes required on the client side. You can drop this into any existing OpenAI API client or routing layer.
For multi-GPU serving, pair with --tensor-parallel-size:
- 70B models:
--tensor-parallel-size 2or4 - 405B models:
--tensor-parallel-size 4or8
Configuration Quick Reference
| Use Case | Config | Notes |
|---|---|---|
| Best quality/speed balance | W4G64 NFL | Recommended default for all model sizes |
| Maximum memory savings | W3G64 NFL | Larger quality gap; validate on your eval set |
| 70B+ production serving | W4G64 NFL + TP | Enable tensor parallel for throughput |
| H100 (experimental) | W4G64 from source | Run auto-tune after build |
---
FLUTE vs AWQ vs GPTQ: Which Quantization Method Should You Use?
All three methods are post-training quantization (PTQ) targeting weight-only compression — weights are quantized to lower bit widths; activations remain in float16. The differences in quantization strategy, quality profile, hardware coverage, and framework support determine which is right for your situation.
| Dimension | FLUTE | AWQ | GPTQ |
|---|---|---|---|
| Quantization type | LUT-based (flexible lookup tables) | Uniform integer + activation-aware scaling | Uniform integer + second-order error correction |
| Bit widths | 4, 3, 2 (2-bit experimental) | 4, 3 | 4, 3, 2 |
| 4-bit quality | ✅ Near-lossless (NFL W4G64) | ✅ Near-lossless | ✅ Near-lossless |
| 3-bit quality | ✅ Strong (LUT matches weight distribution) | ⚠️ Moderate (uniform grid limitation) | ⚠️ Moderate (meaningful PPL degradation on LLaMA) |
| Supported GPUs | A100, A6000, RTX 4090 (stable) | Broad (any CUDA GPU via AutoAWQ) | Broad (any CUDA GPU via AutoGPTQ) |
| H100 support | ⚠️ Source build + auto-tune | ✅ Yes | ✅ Yes |
| Learnable tables | ✅ Yes (NFL format) | ❌ No | ❌ No |
| vLLM integration | ✅ --quantization flute | ✅ --quantization awq | ✅ --quantization gptq |
| HuggingFace integration | ✅ flute.integrations.huggingface | ✅ AutoAWQ / transformers | ✅ AutoGPTQ / transformers |
| TGI support | ❌ Not yet | ✅ Yes | ✅ Yes |
| Multi-modal support | ❌ LLaMA/Gemma families only | ✅ LLaVA, VILA, CLIP-based | ✅ Broad architecture support |
| Model coverage | LLaMA-3/3.1, Gemma-2 (validated) | Very broad | Extremely broad |
| Pre-quantized HF models | ✅ Moderate selection | ✅ Large selection | ✅ Largest selection |
| Production maturity | ✅ v0.4.2 (Feb 2025) | ✅ Mature | ✅ Very mature |
| Best use case | 3-bit inference on A100/RTX4090 with LLaMA/Gemma | Broad hardware/model coverage at 4-bit | Widest ecosystem, unusual architectures |
The Core Trade-Off
FLUTE uses LUT-based quantization with optional learned tables (NFL). The flexible value encoding is its defining advantage: at 3-bit, FLUTE can represent weight distributions far more accurately than any uniform quantization scheme. The trade-off is narrower coverage — production-ready on A100, A6000, and RTX 4090, with full validation on LLaMA-3/3.1 and Gemma-2 only.
[AWQ (Activation-aware Weight Quantization)](/blog/awq-quantization-guide) uses uniform integer quantization with activation-aware scaling to protect salient weights from clipping errors. It achieves strong 4-bit quality across a very wide hardware range (practically any CUDA GPU via AutoAWQ) and supports multi-modal architectures including LLaVA and VILA. Its limitation is 3-bit quality — without flexible value encoding, it cannot match FLUTE NFL W3 on LLaMA-class models.
[GPTQ](/blog/gptq-quantization) applies layer-wise second-order error correction during quantization to minimize reconstruction error. It has the broadest ecosystem support of any quantization method — AutoGPTQ, TGI, vLLM, and dozens of inference frameworks. Like AWQ, it uses uniform integer grids, so 3-bit GPTQ shows meaningful perplexity degradation on LLaMA-family models compared to FLUTE's W3 NFL.
Decision Guide
Choose FLUTE when:
- You need 3-bit quantization with minimal quality degradation
- Your target hardware is A100, A6000, or RTX 4090
- You're running LLaMA-3/3.1 or Gemma-2
- You're using or planning to use vLLM for serving
- You want the flexibility of learned or non-uniform quantization tables
Choose AWQ when:
- Broad hardware compatibility is essential (consumer GPUs, mixed cloud GPU types)
- You need multi-modal model support (LLaVA, VILA, CLIP-based architectures)
- You want the largest pre-quantized model selection
- 4-bit quality is sufficient for your use case (AWQ W4 is comparable to FLUTE W4)
Choose GPTQ when:
- You need the widest model architecture support (architectures beyond LLaMA/Gemma)
- You're integrating with frameworks that have mature GPTQ support but limited FLUTE support
- You need activation quantization modes (W4A8) for compute-bound workloads
- You're quantizing an unusual architecture where FLUTE's shape-specialized kernel hasn't been validated
At 4-bit, all three methods deliver near-lossless quality — the choice comes down to hardware, framework, and model coverage. At 3-bit, FLUTE's LUT approach is clearly superior. That is the configuration space where method selection genuinely changes your production quality floor.
---
FLUTE Changelog: Key Updates Since EMNLP 2024
FLUTE has been actively developed since the EMNLP 2024 publication, with six notable releases from October 2024 through February 2025.
v0.4.2 — February 18, 2025 (current stable) PyTorch version compatibility update; adds pre-built Python 3.9–3.12 wheel support for all three CUDA versions. This is the recommended installation target via pip.
v0.4.1 — February 13, 2025 Introduces auto-tune: a profiling system that generates and caches optimized tile configurations for GPU shapes not covered by the hand-tuned defaults. This is the most significant usability improvement since launch — it means FLUTE can now run on H100s and custom model architectures, even without hand-tuned kernels. Auto-tune runs once and caches results; use it with caution on production systems as performance characteristics are not yet as stable as the default tile sizes.
v0.3.0 — December 12, 2024 Integrates the fast Hadamard transform at the C++ level, contributed by BlackSamorez. This connects FLUTE to the HIGGS (Hadamard Incoherence with Grouped Gradients and Scales) research framework, which was accepted at NAACL 2025. The Hadamard transform pre-processes weights to reduce distribution skewness before quantization, improving quality at low bit widths — particularly 3-bit.
v0.2.3 — November 18, 2024 Adds vector dequantization (vector_size=2) as an infrastructure primitive supporting the HIGGS integration.
v0.1.0 — October 5, 2024 Introduces learnable scales (NFL format) and enhanced HuggingFace from_pretrained() integration — the two features that make FLUTE practical for most deployment scenarios.
The HIGGS connection is worth tracking: the Hadamard transform + LUT quantization combination in v0.3.0 suggests that v0.5 (expected to stabilize auto-tune) may bring further W3 quality improvements alongside broader hardware coverage.
---
Frequently Asked Questions About FLUTE Quantization
What does FLUTE stand for?
FLUTE stands for Flexible Lookup Table Engine. The full paper title is "FLUTE: Fast Matrix Multiplications for Lookup Table-Quantized LLMs," published at EMNLP 2024 Findings. The code is available at github.com/HanGuo97/flute. Authors: Han Guo, William Brandon, Radostin Cholakov, Jonathan Ragan-Kelley, Eric P. Xing, and Yoon Kim.
Is FLUTE a Google product?
No. Despite sometimes appearing as "Google FLUTE" in search results and coverage, FLUTE is academic open-source research from MIT, CMU, and MIT CSAIL — not a Google product or project. The lead author Han Guo was at MIT during the work. There is no Google product involvement.
Does FLUTE work with H100 GPUs?
H100 support requires building FLUTE from source. The pip-distributed wheels target A100, A6000, and RTX 4090. Even with a source build, H100 performance won't reach optimized levels since tile sizes haven't been hand-tuned for H100's architecture. After a source build, run python -m flute.autotune to generate H100-specific tile configurations — this partially bridges the gap.
What is the difference between NFL and nf4 quantization?
nf4 (from QLoRA) uses fixed normal-float quantization levels that are pre-computed to be information-theoretically optimal for normally-distributed weights. These levels are frozen at design time. NFL (Learned Normal Float, FLUTE) initializes from those same nf4 levels but then learns per-group scales using straight-through gradient estimation on calibration data. The runtime inference mechanism is identical (both use LUT lookup), but NFL's learned scales adapt to the actual weight distribution in your specific model, recovering quality that fixed nf4 levels cannot.
Can I use FLUTE with any HuggingFace model?
Currently, LLaMA-3/3.1 and Gemma-2 families are fully validated. FLUTE's shape-specialized kernel requires matrix dimension configurations that match the hand-tuned tile sizes for these architectures. Other models may work with v0.4.1 auto-tune, but results are experimental — validate carefully against unquantized baselines before using in production.
---
Getting Started with FLUTE Quantization
Google FLUTE's approach to fast quantization for LLM inference addresses a real gap in the quantization landscape. Uniform integer quantization has served practitioners well at 4-bit, but the 3-bit regime has been constrained by the precision limitations of equal-step integer grids. FLUTE's LUT-based approach, combined with NFL's learned per-group scales, delivers near-lossless W4 quantization and genuinely competitive W3 quality — with a 2–4× kernel speedup that translates directly into higher throughput and lower serving cost.
For teams running LLaMA-3.1 or Gemma-2 on A100 or RTX 4090 hardware, the path to production deployment is clear:
- Install
pip install flute-kernel(match to your CUDA version) - Try pre-quantized — load an NFL W4G64 LLaMA-3.1 or Gemma-2 checkpoint via
flute.integrations.huggingface.from_pretrained()and run a quick quality evaluation - Serve at scale — add
--quantization fluteto your existing vLLM server command; no other changes needed - Evaluate quality — compare WikiText-2 perplexity and your task-specific metrics against the unquantized baseline; W4G64 NFL should show minimal degradation
- Track development — v0.4.1 auto-tune and HIGGS integration signal that hardware coverage and W3 quality are both improving; watch the repo for v0.5
For managed inference with FLUTE-optimized quantized models — including LLaMA-3.1 and Gemma-2 variants — inference.net provides production-grade API access without the infrastructure overhead of self-hosted quantized serving.
---
References
- Han Guo, William Brandon, Radostin Cholakov, Jonathan Ragan-Kelley, Eric P. Xing, Yoon Kim. "FLUTE: Fast Matrix Multiplications for Lookup Table-Quantized LLMs." EMNLP 2024 Findings. arXiv:2407.10960.
- FLUTE GitHub Repository —
HanGuo97/flute. https://github.com/HanGuo97/flute - FLUTE GitHub Releases — v0.1.0 through v0.4.2. https://github.com/HanGuo97/flute/releases
- Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer. "QLoRA: Efficient Finetuning of Quantized LLMs." NeurIPS 2023. (NormalFloat4 reference.)
- Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, Song Han. "AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration." arXiv:2306.00978.
- Elias Frantar, Saleh Ashkboos, Torsten Hoefler, Dan Alistarh. "GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers." ICLR 2023.
Meet with our research team
Schedule a call with our research team to learn more Specialized Language Models can cut costs and improve performance.