'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Feb 19, 2026
Llama vs ChatGPT: Can Open Source Match GPT-5? (2026)
Inference Research
Open-Source AI Has Reached a Turning Point
In April 2025, Meta's Llama 4 Maverick crossed 1,400 ELO on LMArena — the world's most widely used AI evaluation leaderboard — outperforming GPT-4o on human preference benchmarks. For developers asking where the llama vs chatgpt comparison stands today, that result was a wake-up call. The gap between open-source and proprietary AI has genuinely narrowed.
But narrowed is not the same as closed. GPT-5.2, released in December 2025, hit 93.2% on GPQA Diamond — doctoral-level science reasoning questions — compared to Maverick's 69.8%. On the hardest frontier tasks, OpenAI still holds the lead.
This article gives you a current-state comparison: not Llama 3 vs GPT-4, but Llama 4 Maverick vs GPT-5 and GPT-5.2, using official benchmark data from early 2026. You'll get a precise cost breakdown, a clear privacy and compliance analysis, and a concrete framework for deciding which model fits your use case.
The short version: Llama 4 already matches or exceeds ChatGPT for most production workloads. GPT-5.2 earns its premium on frontier reasoning. The optimal play for most engineering teams is to use both — strategically.
Read time: 18 minutes
---
Llama vs ChatGPT — The Quick Verdict
Llama and ChatGPT differ in one fundamental way: control. Llama is Meta's open-weight model family, freely downloadable and self-hostable, while ChatGPT is OpenAI's proprietary product powered by GPT-5. The key differences are data ownership, cost, and customizability — Llama gives you control of the model; ChatGPT gives you a managed, always-updated API.
Neither model is universally better. Here's the honest assessment by category:
Llama 4 Maverick wins on:
- Cost — $0.50/M input tokens vs GPT-5's $1.25/M via managed API; up to 220× cheaper than GPT-5.2 Pro on outputs
- Privacy — self-hosted deployment means zero data egress; no third-party data processing
- Customization — open weights enable full fine-tuning on proprietary datasets
- Long-context — Scout's 10M token context window is unmatched by any competitor
GPT-5.2 wins on:
- Frontier reasoning — 93.2% on GPQA Diamond vs Maverick's 69.8%; the gap is real on doctoral-level tasks
- Zero-infrastructure ease — API call and go, no cluster management
- Multimodal breadth — 84.2% on MMMU vs Maverick's 73.4%
- Complex software engineering — GPT-5.3-Codex leads SWE-bench at 74.9%
Here's how the models compare across the dimensions that matter most for production decisions:
| Category | Llama 4 Maverick | GPT-5 / GPT-5.2 |
|---|---|---|
| Everyday task performance | ✅ Competitive with GPT-5; beats GPT-4o on GPQA Diamond | ✅ Strong across all task types |
| Frontier reasoning | 69.8% GPQA Diamond — strong, not the ceiling | ✅ 93.2% GPQA Diamond (GPT-5.2) |
| Cost at scale | ✅ $0.50/M input, $0.77/M output (Groq) | $1.25–$21/M input, $10–$168/M output |
| Data privacy | ✅ Self-hosted = zero data egress | Data transits OpenAI servers |
| Customization | ✅ Full fine-tuning on open weights (LoRA/QLoRA) | Limited: Custom GPTs or restricted fine-tune API |
| Time to first query | Minutes (managed API) / Hours (self-host setup) | ✅ Minutes — API key and go |
| Multimodal support | 73.4% MMMU — native text + image | ✅ 84.2% MMMU — text, image, audio |
| Long-context window | ✅ Scout: 10M tokens — unmatched | 400K tokens (GPT-5) |
| Infrastructure burden | None (managed API); High (self-hosted) | ✅ None — fully managed |
| Model reproducibility | ✅ Fixed weights — pinned, auditable | Model drift — silent updates possible |
For most teams, the choice isn't either/or. Cost-optimized model routing — Llama 4 for high-volume standard tasks, GPT-5.2 for frontier reasoning — is fast becoming the production standard. The When to Use Llama vs ChatGPT section breaks this down by specific use case.
---
What Is Llama? Meta's Open-Weight AI Family
Llama isn't a product. It's an open-weight model family — the weights are public, which means anyone can download, run, fine-tune, or serve these models without paying per token. That distinction shapes everything about how you use it: performance characteristics, deployment flexibility, cost structure, and your ability to customize the model for your domain.
When developers evaluate Llama as an open-source ChatGPT alternative, the answer starts here: it's a fundamentally different kind of artifact.
The Llama 4 Model Family
Meta released three Llama 4 models in April 2025, each targeting a different position on the performance-efficiency spectrum.
Llama 4 Scout is the efficiency champion. It runs 17 billion active parameters across 16 experts (109B total parameters) and fits on a single NVIDIA H100. Its standout feature is context: Scout supports a 10 million token context window — the largest available from any model family as of early 2026. For long-document analysis, legal review across hundreds of contracts, or codebase-level reasoning, Scout is in a class of its own.
Llama 4 Maverick is the production workhorse. It uses the same 17B active parameter count as Scout but routes tokens through 128 experts (400B total parameters), giving it substantially more expressive capacity per forward pass. Maverick currently powers Meta AI inside Facebook, WhatsApp, and Instagram — arguably the largest LLM deployment in history by user volume. It crossed 1,400 ELO on LMArena, outperforming GPT-4o on human-preference benchmarks.
Llama 4 Behemoth is Meta's frontier research model, announced alongside Scout and Maverick in April 2025 but still in limited rollout as of early 2026. With 288 billion active parameters and approximately 2 trillion total parameters, it targets GPT-5.2-level reasoning. Expect broader availability later in 2026.
Why MoE Architecture Matters
Both Scout and Maverick use Mixture of Experts (MoE) architecture. Instead of activating every parameter on every forward pass, MoE routes each token through a small subset of specialized "expert" sub-networks. The result: Maverick achieves 400B-parameter-class performance while only computing through 17B parameters per inference. This is the key insight behind its efficiency — and why managed inference costs are as competitive as they are.
Native Multimodal and Multilingual Support
Llama 4 models accept text and image inputs natively via an early fusion architecture — not as bolt-on vision modules. This enables document understanding, image-grounded reasoning, and visual question answering. Twelve languages are supported natively, making Llama 4 a practical choice for multilingual enterprise applications at no additional licensing cost.
The Open-Weight Nuance
Meta's license makes Llama weights freely available, but it's technically "open-weight" rather than fully open source: commercial use has some restrictions for companies exceeding 700 million monthly active users. For virtually every developer and enterprise, this distinction is academic. You can download, deploy, fine-tune, and serve Llama commercially without restrictions.
---
What Is ChatGPT? OpenAI's GPT-5 Ecosystem
ChatGPT is a consumer product at chat.openai.com. The GPT-5 API is what developers actually integrate. If you're evaluating an open-source ChatGPT alternative for your application, the relevant comparison is Llama's inference API against the GPT-5 API — not the consumer chat interface. Most comparison articles conflate the two; this one doesn't.
The Current GPT-5 Family
GPT-5 launched in August 2025 as OpenAI's flagship general-purpose model. It includes a unified routing system that dynamically selects between fast and deep-thinking modes depending on task complexity. Input pricing starts at $1.25/M tokens, output at $10.00/M. Context window: 400K tokens. Strong across coding, math, writing, and visual perception.
GPT-5.2 followed in December 2025, advancing professional knowledge work and complex multi-step agentic workflows. On GPQA Diamond — the gold standard benchmark for doctoral-level scientific reasoning — GPT-5.2 scored 93.2%. GPT-5.2 Pro pricing: $21/M input, $168/M output. This is where OpenAI earns its frontier premium.
GPT-5.3-Codex arrived in February 2026, optimized for agentic software engineering workflows. It runs 25% faster than GPT-5.2-Codex and is the first OpenAI model rated "High capability" in cybersecurity evaluations. On SWE-bench — the real-world software engineering benchmark — GPT-5.3-Codex scores 74.9%, leading all models.
What GPT-5 Actually Does Best
The genuine advantage of the GPT-5 stack isn't only raw benchmark performance. Zero infrastructure management is the real draw for many teams: you make an API call, the model runs, and OpenAI handles reliability, scaling, and model updates. GPT-5 also ships with integrated capabilities — web search, code interpreter, image generation — that would each require custom integration on the Llama side.
The Real Limitations
Data sent to the GPT-5 API transits OpenAI's servers. Their terms state that API inputs are not used for training by default, but your prompts and outputs still pass through third-party infrastructure. For regulated industries and many enterprise legal teams, that's a compliance blocker regardless of contractual protections.
Model drift is the other underappreciated operational risk. OpenAI updates underlying GPT models periodically, sometimes changing behavior in ways that affect production systems without advance notice. With self-hosted Llama, the model weights are pinned — outputs are reproducible because the model is fixed.
---
Benchmark Performance — Llama 4 vs GPT-5 Head-to-Head
Benchmarks are directional, not definitive. They measure specific capabilities under controlled conditions; real-world performance varies by task type, prompt engineering, and inference configuration. With that framing established, here is what the official data shows when comparing llama 4 vs gpt-5:
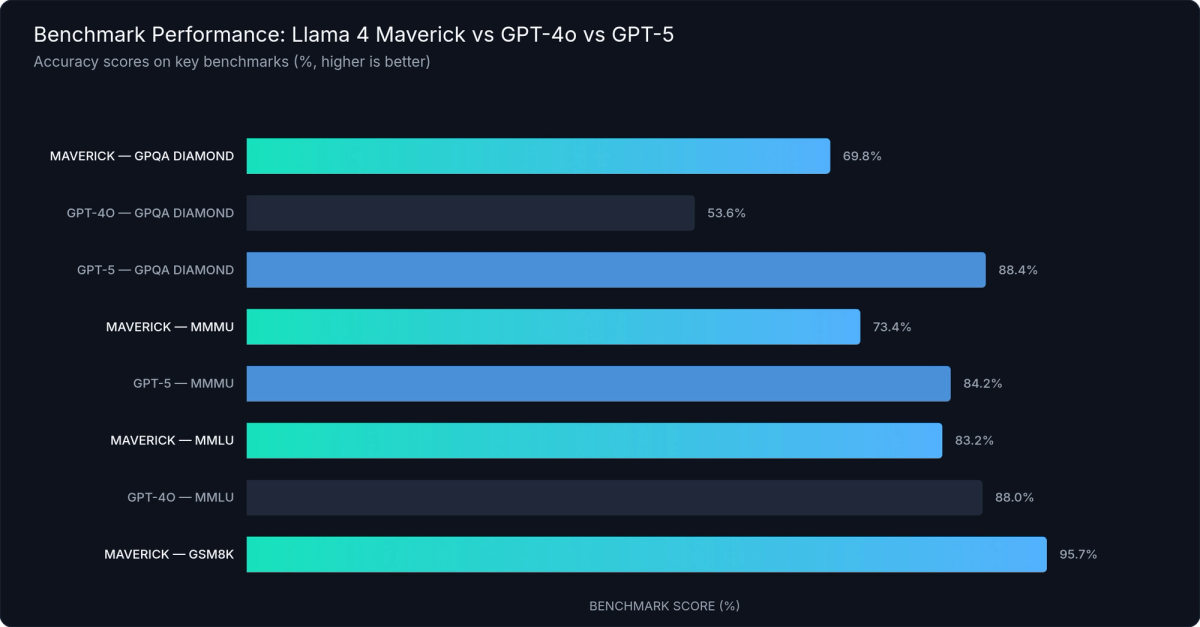
Figure 1: Llama 4 Maverick vs GPT-5 — Benchmark Performance — Official benchmark scores across GPQA Diamond, MMLU, HumanEval, MMMU, and GSM8K, February 2026
Breaking Down the Numbers
MMLU (general knowledge and reasoning): Maverick scores 83.2% versus GPT-4o's 88.0% — a 5-point gap. For most business applications, both represent strong, production-ready performance. The difference is meaningful in research contexts but rarely decisive for customer-facing applications handling standard knowledge tasks.
GPQA Diamond (doctoral-level science reasoning): This benchmark produces the most surprising results in the llama 4 vs gpt-5 comparison. Maverick scores 69.8%, which beats GPT-4o's 53.6% — open-source has surpassed a frontier proprietary model on hard reasoning. But GPT-5 scores 88.4%, an 18-point lead over Maverick. For applications requiring multi-step scientific reasoning at the doctoral level, that gap is consequential.
HumanEval (code generation): Maverick scores 86.4%, competitive with GPT-4-class models on standard coding tasks. GPT-5.3-Codex pulls ahead on SWE-bench (74.9%) — a benchmark that simulates real engineering workflows across large codebases with complex dependencies. For straightforward code generation, both models perform well; for frontier software engineering agent tasks, GPT-5.3-Codex leads.
MMMU (multimodal understanding): Maverick at 73.4% versus GPT-5 at 84.2%. GPT-5 holds a 10+ point lead on tasks combining complex image understanding with reasoning — relevant for applications doing document intelligence, diagram analysis, or visual question answering at high complexity.
GSM8K (grade-school math): Maverick scores 95.7%, effectively tied with GPT-5-class models. Both are near-ceiling on standard arithmetic and math reasoning.
LMArena ELO: Maverick crossed 1,400, outperforming GPT-4o on this human-preference leaderboard. This is a real-world signal from human raters comparing model outputs side-by-side — not just capability measurement. GPT-5 leads in direct comparisons at the top of the leaderboard, but Maverick's position above GPT-4o is significant.
The Honest Assessment
For everyday production tasks — summarization, question answering, customer service, retrieval-augmented generation, classification, and standard code assistance — Llama 4 Maverick is genuinely competitive with GPT-5. Not just GPT-4o.
For frontier reasoning — doctoral-level analysis, complex multi-step agentic workflows, and SWE-level software engineering — GPT-5/5.2 maintains a meaningful lead. If your application depends on GPQA Diamond-class reasoning, the 18-point gap between Maverick (69.8%) and GPT-5 (88.4%) is real and operationally significant.
One important caveat: Meta faced scrutiny after its LMSYS leaderboard submission used an experimental Maverick variant that differed from the publicly released weights. Production Maverick performance may vary from peak leaderboard results. For any mission-critical deployment, benchmark your specific workload on production weights before committing.
---
The Real Cost of Llama vs ChatGPT
Cost is where the llama vs chatgpt comparison becomes most concrete — and most asymmetric. The gap at scale isn't marginal; for high-volume applications, it can represent millions of dollars per year in operational savings.
Three Ways to Run Llama
GPT-5 has exactly one deployment path: the OpenAI API (or Azure OpenAI). You pay OpenAI's rates with no alternative.
Llama 4 gives you three options: (1) managed inference API — pay per token, no infrastructure; (2) self-hosted on your own GPU hardware; (3) cloud ML platforms such as AWS SageMaker, Azure AI, or Google Cloud's model serving infrastructure.
Token Pricing at a Glance
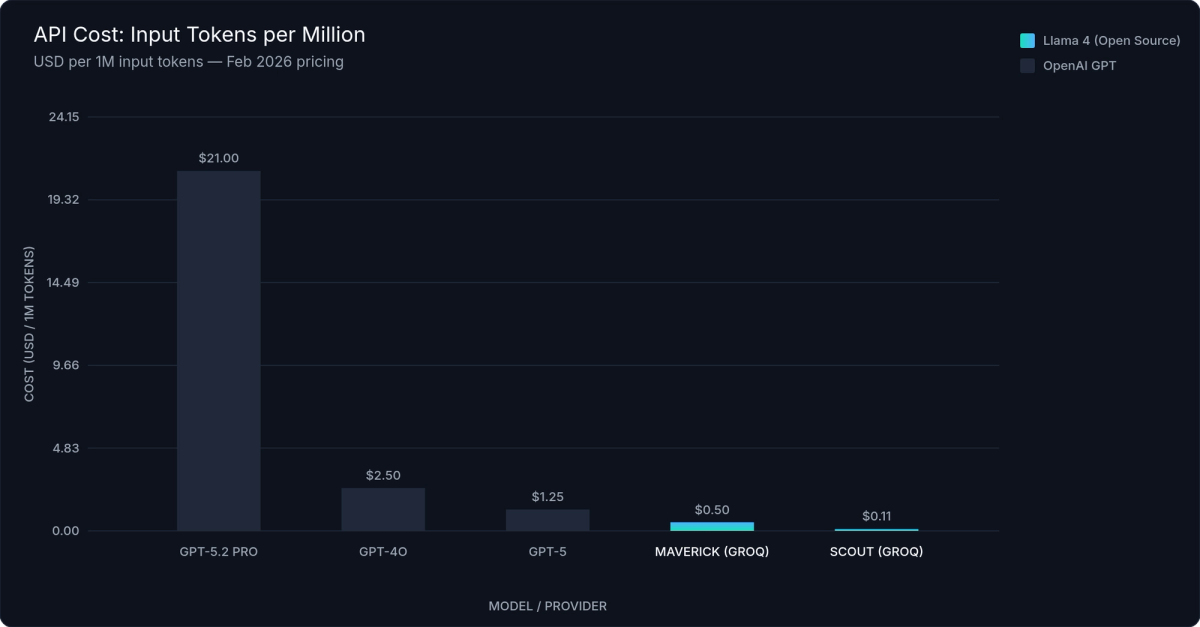
Figure 2: LLM API Cost per Million Output Tokens — February 2026 pricing; output tokens drive the majority of inference costs at scale
Current pricing per million tokens as of February 2026:
| Model | Input ($/M tokens) | Output ($/M tokens) |
|---|---|---|
| GPT-5 | $1.25 | $10.00 |
| GPT-5.2 Pro | $21.00 | $168.00 |
| GPT-4o (reference) | $2.50 | $10.00 |
| Llama 4 Scout (Groq) | $0.11 | $0.34 |
| Llama 4 Maverick (Groq) | $0.50 | $0.77 |
| Llama 4 Maverick (inference.net) | See inference.net/pricing | See inference.net/pricing |
Llama 4 Maverick via managed API is 2.5× cheaper than GPT-5 on input tokens. On output tokens — where costs accumulate fastest in generation-heavy applications — Maverick at $0.77/M versus GPT-5's $10.00/M is 13× cheaper. GPT-5.2 Pro output at $168/M is roughly 220× the cost of Llama 4 Scout's $0.34/M output rate.
Understanding your llama api cost starts with accurately modeling your input/output ratio. Applications with long outputs — code generation, detailed reports, structured data extraction — see dramatically higher cost differentials than classification or short-answer tasks.
The Self-Hosting Break-Even
Self-hosting Llama 4 Maverick requires H100s or equivalent GPU infrastructure. The economics follow a predictable curve.
Below 5 million tokens per month, managed inference APIs cost less than the amortized GPU time required for self-hosting. In the 5–100 million tokens per day range, self-hosting becomes economically interesting — if you have ML engineering capacity to manage deployments, upgrades, reliability, and security. Above 100 million tokens per day, the savings can reach $1M+ per year at scale.
The hidden costs matter: ML engineering time, infrastructure operations, model updates, monitoring, and security eat into savings for all but the largest, most engineering-mature teams. For most teams, managed Llama inference APIs deliver better unit economics and eliminate operational overhead.
The Output Token Asymmetry
Output tokens cost 3–8× more than input tokens across all providers. A task that generates long outputs — detailed code, analytical reports, structured data — costs significantly more per query than a classification task with a one-word answer. When building your cost model, forecast output length carefully. The majority of teams underestimate output costs when evaluating total inference spend.
The Hybrid Cost Strategy
The most cost-efficient production architecture combines both ecosystems: Llama 4 Maverick via managed inference for high-volume standard tasks, GPT-5.2 reserved specifically for the cases where its frontier reasoning lead is determinative. Most applications don't require doctoral-level reasoning for every request — routing intelligently cuts costs without sacrificing quality where it matters.
---
Privacy and Data Sovereignty
For many teams, the choice between Llama and ChatGPT isn't primarily about performance or even cost — it's about data. The self-hosted llm vs openai question takes on a different character when compliance requirements enter the picture.
ChatGPT's Data Posture
Data sent to the GPT-5 API is processed on OpenAI's infrastructure. OpenAI's API terms include data protection provisions — API inputs are not used to train models by default — but your prompts, completions, and any embedded user data still transit a third-party system. In regulated industries, that transit creates compliance complexity regardless of contractual protections.
Llama Self-Hosted: The Strongest Posture
Running Llama on your own infrastructure means zero data egress. Prompts, completions, and user data never leave your environment. No third-party data processing agreements are needed beyond the cloud provider you already use. For teams operating under strict data governance requirements, this is the only technically adequate solution — and it's one that ChatGPT simply cannot match.
Compliance Scenarios by Industry
Healthcare (HIPAA): A self-hosted Llama deployment can be fully HIPAA-compliant — data never leaves your infrastructure. ChatGPT requires a Business Associate Agreement with OpenAI plus ongoing review of their data handling practices. For healthcare applications processing PHI, self-hosted Llama is the more controllable path.
Finance (PCI DSS, internal data policies): Many financial institutions prohibit sending customer financial data to third-party LLM APIs as a matter of internal policy, regardless of contractual protections. Self-hosted Llama fits naturally within existing cloud security architecture.
Government and Defense (ITAR, CUI): Controlled Unclassified Information and ITAR-regulated technical data typically require air-gapped or FedRAMP-compliant deployments. Only self-hosted Llama in an approved cloud environment qualifies for these scenarios.
IP-Sensitive R&D: Companies protecting trade secrets or proprietary research processes may prefer zero-egress inference even where not legally mandated. The risk of a competitor inferring proprietary methodology from prompt patterns is zero when inference is on-premises.
Managed Inference as a Middle Ground
Using a managed Llama inference provider — such as inference.net or Groq — means your data is processed by that provider, not OpenAI, but it does leave your infrastructure. For many organizations, this is a meaningful improvement: inference providers offer targeted compliance certifications (SOC 2, HIPAA BAA, etc.) and are purpose-built for API inference workloads. Evaluate provider-specific compliance posture against your requirements.
Model Drift: The Hidden Operational Risk
With ChatGPT, OpenAI updates the underlying model periodically — sometimes changing output behavior in ways that affect production systems without advance notice. This is model drift: outputs that were reliable become inconsistent as the base model evolves. Self-hosted Llama uses pinned model weights. The model is fixed; its behavior is reproducible across deployments. For production systems that depend on consistent structured outputs, reproducible behavior is a concrete operational advantage that has nothing to do with benchmark scores.
---
Customization and Fine-Tuning
This is where Llama's open-weight architecture becomes not just cheaper, but genuinely superior for domain-specific applications. A fine-tuned Llama model can outperform generic GPT-5 on specialized tasks — not just on cost, but on accuracy.
What Open Weights Enable
With Llama's weights available, your engineering team can:
- Fine-tune on proprietary data — medical records, legal contracts, your codebase, customer conversation history. The model learns your domain's patterns at the weight level, not just through prompt context.
- Instruction-tune for custom behavior — enforce specific output formats, follow internal schemas, or maintain a persona that's perfectly consistent regardless of user input.
- Use LoRA/QLoRA for efficient adaptation — Low-Rank Adaptation lets you fine-tune large models with a fraction of the GPU hours required for full fine-tuning. Adapting Llama 4 Maverick with QLoRA is achievable on cloud A100s in hours for datasets of thousands of examples.
- Distill smaller, faster models — use Llama as a teacher to train purpose-built student models optimized for specific tasks. Deploy a model that's 5× faster than Maverick on the narrow task it was distilled for.
ChatGPT's Customization Ceiling
OpenAI's customization options are constrained at the weight level. Custom GPTs allow persona and system instruction customization only — no weight-level adaptation. OpenAI's fine-tuning API (available for GPT-4o mini) enables some task-specific adaptation, but base weights remain inaccessible, training occurs on OpenAI's infrastructure, and the process is limited in data volume and training iterations.
There is no way to audit OpenAI's model internals, inspect training data influence, or build custom safety guardrails at the activation level. For teams that need genuine domain adaptation or model transparency, ChatGPT's customization options are not equivalent.
Fine-Tuning Scenarios Where Llama Wins
Medical coding assistant: A Llama model fine-tuned on ICD-10 coding examples achieves higher precision than generic GPT-5 on coding tasks. The model learns the specific patterns required for compliance — nuanced distinctions between similar codes, documentation requirements — that prompt engineering can approximate but not reliably reproduce.
Legal contract review: Fine-tuning on a firm's precedent contracts enables clause extraction and risk flagging that outperforms retrieval-augmented approaches with generic models. Domain-specific weight adaptation captures structural and semantic patterns that even sophisticated RAG pipelines miss.
Enterprise knowledge base chatbot: A Llama model fine-tuned on internal documentation is faster and more consistent than a retrieval-augmented GPT-5 system for high-frequency internal queries — especially where formatting, tone, and specific product terminology must match exactly.
Security and red-team applications: Llama's open weights enable custom safety evaluations and controlled red-teaming that is not possible with black-box models. Meta's companion tools — Llama Guard for content moderation, Prompt Guard for prompt injection protection, and Llama Firewall for deployment security — provide production-ready safety infrastructure on top of the base model without requiring custom development from scratch.
Practical Requirements
LoRA fine-tuning a Llama 4 model requires A100 or H100 GPUs, but is achievable on cloud instances in a matter of hours for datasets with thousands of examples. This is not a multi-month ML research project. For most engineering teams with moderate ML capacity — or access to cloud GPU instances — Llama fine-tuning is operationally tractable and delivers measurable accuracy improvements for domain-specific workloads.
---
When to Use Llama vs ChatGPT
The choice is rarely binary. Most sophisticated production teams use both models, routing tasks based on requirements. The question is which tasks go where.
Use Llama 4 When:
- High-volume API calls (>5M tokens/month) where cost is material — Maverick at $0.50/M input versus GPT-5's $1.25/M; the savings compound at scale
- Privacy-sensitive or regulated data — healthcare (HIPAA), finance (PCI DSS), government (ITAR/CUI), or IP-sensitive workloads where data egress is restricted or prohibited
- Domain-specific fine-tuning required — you need weight-level model adaptation, not just prompt customization or RAG
- Offline or edge deployment — IoT devices, air-gapped environments, or edge infrastructure where cloud API latency or availability is a constraint
- Long-context document processing — Scout's 10M token context window handles full repositories, multi-hundred-page legal documents, or complete codebases in a single context; no other model matches this at launch
- Model transparency and auditability — regulated industries or internal compliance policies requiring full model inspection, versioning, and behavioral reproducibility
Use ChatGPT / GPT-5 When:
- Zero infrastructure tolerance — small teams or early-stage products that need production-ready LLM access without ML engineering overhead
- Frontier reasoning tasks — doctoral-level scientific analysis, complex multi-step agentic workflows where GPT-5.2's 93.2% GPQA Diamond score is the relevant ceiling
- Advanced multimodal workflows — tasks requiring GPT-5's 84.2% MMMU performance on complex image-text reasoning where Maverick's 73.4% is insufficient
- SWE-level software engineering — GPT-5.3-Codex on SWE-bench (74.9%) leads for complex real-world software engineering agent tasks across large codebases
- No ML engineering capacity — when there's no team available to manage deployments, fine-tuning pipelines, or infrastructure monitoring
The Decision Matrix
| Use Case | Llama 4 | GPT-5 / GPT-5.2 | Winner |
|---|---|---|---|
| High-volume production API (>5M tokens/month) | $0.50/M input — cost-efficient at scale | $1.25–$21/M input — scales linearly | ✅ Llama 4 |
| Privacy-critical / regulated data (HIPAA, ITAR, PCI DSS) | Self-hosted = zero data egress | Data transits OpenAI servers | ✅ Llama 4 |
| Domain-specific fine-tuned model | Open weights enable full LoRA/QLoRA fine-tuning | No base-weight access; restricted fine-tune API | ✅ Llama 4 |
| Zero-infra startup or solo dev | Managed API available; requires model selection | ✅ API key, one call, done | ✅ GPT-5 |
| Frontier reasoning (doctoral-level, complex agentic) | 69.8% GPQA Diamond | ✅ 93.2% GPQA Diamond (GPT-5.2) | ✅ GPT-5.2 |
| Complex software engineering (SWE-bench tasks) | 86.4% HumanEval (standard code) | ✅ 74.9% SWE-bench (GPT-5.3-Codex) | ✅ GPT-5 |
| Long-context document processing | ✅ Scout: 10M token context window | 400K tokens (GPT-5) | ✅ Llama 4 Scout |
| Advanced multimodal (complex image + text reasoning) | 73.4% MMMU | ✅ 84.2% MMMU | ✅ GPT-5 |
| Cost-sensitive scaling (output-heavy apps) | ✅ $0.77/M output vs $10/M (GPT-5) — 13× cheaper | Prohibitive at high output volume | ✅ Llama 4 |
| Air-gapped / offline / edge deployment | ✅ Self-hostable, runs on-prem | Cloud-only — no offline deployment | ✅ Llama 4 |
The Hybrid Recommendation
For most mid-to-large engineering teams, the optimal architecture runs both:
- Llama 4 Maverick via managed inference API handles the volume — summarization, QA, classification, customer service, retrieval-augmented generation, and standard generation tasks where cost efficiency matters
- GPT-5.2 handles the cases requiring frontier reasoning depth — complex analytical tasks, advanced agentic workflows, and workloads where the 18-point GPQA Diamond gap is operationally significant
- Fine-tuned Llama handles domain-specific tasks where a purpose-built model outperforms any general-purpose alternative on accuracy, latency, and cost simultaneously
This routing approach is cost-efficient, improves as both model families advance, and avoids vendor lock-in to either OpenAI or any single inference provider.
---
Running Llama Without the Infrastructure
The biggest practical barrier to Llama adoption isn't performance — it's infrastructure. Running Llama 4 Maverick in its full form (400B total parameters) requires H100s or equivalent GPU capacity, hardware most teams don't have available. Managed Llama inference APIs solve this completely.
How Managed Inference Works
A managed Llama inference API exposes the model through an HTTP endpoint with the same interface as the OpenAI API. You send a request; you get a completion. No GPU provisioning, no cluster management, no ML ops, no on-call rotations for GPU failures.
The operational advantages are practical and immediate:
- OpenAI-compatible API format — change your base URL and model name; your existing ChatGPT integration code works without further modification
- Pay per token, not per GPU-hour — you're not paying for idle compute between requests; cost scales exactly with usage
- Serverless scaling — handles traffic spikes without pre-provisioning capacity; scales to zero during off-hours with no idle cost
- No ML engineering burden — model updates, infrastructure reliability, and security are managed by the provider
inference.net: Serverless Llama Access
inference.net offers global serverless Llama inference with sub-second cold starts and up to 90% lower cost compared to major legacy providers. It supports Llama 4 Maverick, Scout, and other frontier open-source models on a fully OpenAI-compatible API.
Getting started takes three steps:
- Sign up at inference.net and generate your API key
- Update your API base URL to the inference.net endpoint — a single line of configuration
- Set your model parameter to
meta-llama/llama-4-maverick
Your existing OpenAI SDK code — whether Python, TypeScript, or any other language — works without further modification. Migration from ChatGPT to Llama takes minutes, not a sprint. For current Llama 4 token rates, see inference.net/pricing.
When Self-Hosting Makes Sense
If you're processing 100M+ tokens per day and have dedicated ML infrastructure engineers, the economics of self-hosting start to work in your favor. For everyone else, managed inference delivers better unit economics and eliminates operational overhead. The right approach is to start with managed inference, validate your architecture, and revisit self-hosting when volume and team capacity make it the right optimization — not before.
---
Frequently Asked Questions
Is Llama as good as ChatGPT?
Llama 4 Maverick matches or outperforms ChatGPT (powered by GPT-4o) on many standard benchmarks and beats GPT-4o on GPQA Diamond reasoning (69.8% vs 53.6%). It trails GPT-5.2 on the hardest reasoning and complex multimodal tasks. For most production workloads, Llama 4 quality is excellent — and it's available at 2–13× lower cost per token via managed inference APIs.
Can I use Llama for free?
Llama model weights are free to download and run on your own hardware. Hosting requires GPU infrastructure, which carries real costs. Managed inference APIs like inference.net charge per token but with no usage minimums, making experimentation effectively free at low volumes. At production scale, managed Llama inference costs 2–13× less than standard GPT-5 per token — and up to 220× less than GPT-5.2 Pro on output tokens.
Is Llama safe for enterprise use?
Yes. Llama 4 ships with enterprise-grade safety infrastructure: Llama Guard for content moderation, Prompt Guard for prompt injection protection, and Llama Firewall for comprehensive deployment security. Self-hosted deployments give you full data control with no third-party data exposure. Meta's commercial license permits enterprise use without restrictions for companies under 700 million monthly active users — which covers virtually every business deploying LLMs.
What is Llama 4 Behemoth?
Behemoth is Meta's frontier research model — 288 billion active parameters and approximately 2 trillion total parameters. It was announced alongside Scout and Maverick in April 2025 and is currently in limited rollout as of early 2026. Behemoth is positioned to challenge GPT-5.2 on doctoral-level reasoning benchmarks and is expected to reach broader availability later in 2026.
Will open-source LLMs eventually match GPT-5.2?
The trajectory strongly suggests yes. Llama 4 Maverick already beats GPT-4o on GPQA Diamond, and Behemoth targets GPT-5.2 territory. Historically, open-source models have closed the gap with frontier closed-source models within 6–18 months of their release. The more relevant question for 2026 is when Behemoth reaches broad deployment — not whether open-source AI can compete at the frontier.
---
The Verdict: Can Open Source Match GPT-5?
For most production tasks — it already does.
Llama 4 Maverick is a genuine ChatGPT alternative, not a budget substitute. It outperforms GPT-4o on GPQA Diamond reasoning, crosses 1,400 ELO on human preference benchmarks, handles 10 million token contexts that no competitor matches, and runs at 2–13× lower cost per token via managed inference APIs. For cost-sensitive, privacy-conscious, or customization-heavy use cases, Llama isn't just competitive — it's the better choice.
GPT-5.2 still leads at the frontier. The 18-point GPQA Diamond gap between Maverick (69.8%) and GPT-5 (88.4%) is real and matters for doctoral-level scientific analysis, complex multi-step agentic workflows, and SWE-level software engineering tasks. When your application genuinely requires that ceiling, GPT-5.2 earns its premium.
The emerging norm among sophisticated engineering teams is model routing: Llama 4 for volume workloads, GPT-5.2 for frontier reasoning tasks, fine-tuned Llama for domain-specific applications. This isn't a compromise — it's the most cost-efficient and technically sound architecture available today.
If you want to test Llama 4 without touching infrastructure, inference.net offers serverless Llama access on an OpenAI-compatible API. Switch from ChatGPT in minutes and benchmark the model on your actual workload before committing.
The answer to "Can open source match GPT-5?" is increasingly clear: on most tasks, it already does. On cost and data control, it's not even close.
---
References
- Meta AI. "The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation." Meta AI Blog, April 2025.
- Meta AI. Llama 4 official benchmark data. llama.com/models/llama-4.
- OpenAI. "Introducing GPT-5." openai.com, August 2025.
- OpenAI. "Introducing GPT-5.2." openai.com, December 2025.
- OpenAI. "GPT-5.3-Codex." openai.com, February 2026.
- OpenAI. GPT-5 API Pricing. openai.com/api/pricing.
- Groq. Llama 4 Scout and Maverick Pricing. groq.com/pricing.
- inference.net. Pricing and Model Availability. inference.net/pricing.
- Hugging Face. "Llama 4 Release." huggingface.co, April 2025.
- Collabnix. "Deep Technical Analysis of Llama 4 Architecture." collabnix.com, April 2025.
- AI Pricing Master. "Self-Hosting LLMs: Total Cost of Ownership Analysis 2026." aipricingmaster.com.
- Silicon Data. "LLM Cost Guide 2026." silicondata.com.
- LMArena (LMSYS Chatbot Arena). ELO Leaderboard, February 2026. lmarena.ai.
- Keywords AI. "Introducing inference.net." keywordsai.co/blog/introducing-inference-net.
Meet with our research team
Schedule a call with our research team to learn more Specialized Language Models can cut costs and improve performance.