'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Feb 21, 2026
LLM API Pricing Comparison 2026: 30+ Models, Every Provider
Inference Research
Why Your LLM API Bill Is Higher Than It Should Be
The same task can cost $0.04 per million tokens on one provider and $25.00 on another — a 625× price difference. It's the difference between a side project that stays affordable and a production system that quietly drains budget.
This LLM API pricing comparison covers 30+ models across every major provider type as of February 2026, including the category almost every other guide ignores entirely: open-source inference providers. Groq, Together AI, Fireworks AI, and inference.net serve the same powerful open-weight models — Llama 4, Mistral, DeepSeek, Qwen — at 50–90% lower cost than frontier APIs. Yet they're absent from virtually every competitor article on this topic.
That gap is worth closing. Whether you're evaluating GPT-5.2, Claude Opus 4.6 (released February 5, 2026), Gemini 3.1 Pro (released February 19, 2026), or a budget-first Llama variant, this guide gives you the complete picture with current pricing — not a filtered view of the market.
By the end, you'll know which model fits your workload, your quality bar, and your actual budget.
Read time: 18 minutes
---
TL;DR: Best LLM API by Use Case
If you're in a hurry, here's where we'd point you based on use case. Detailed pricing tables and full analysis follow — treat this as a starting point, not the final word.
| Use Case | Best Model | Provider | Input $/1M | Output $/1M | Reason |
|---|---|---|---|---|---|
| Best overall quality | Claude Opus 4.6 | Anthropic | $5.00 | $25.00 | Leads quality benchmarks on reasoning, coding, and long-context comprehension |
| Best budget / high-volume | Schematron-8B | inference.net | $0.04 | $0.10 | Lowest price in this comparison; purpose-built for classification, RAG, extraction |
| Fastest inference | Llama 4 Scout | Groq | $0.11 | $0.34 | Custom LPU hardware; best tokens/second; sub-second UX |
| Best for coding | GPT-5.2 | OpenAI | $1.75 | $14.00 | Tops coding benchmarks; strongest ecosystem (function calling, fine-tuning) |
| Best reasoning / thinking | o3 | OpenAI | $10.00 | $40.00 | Extended chain-of-thought; outperforms all alternatives on complex logic and math |
| Best open-source alternative to GPT-5 | DeepSeek V3.2 | inference.net / Together AI | $0.14 | $0.28 | ~85–90% of GPT-5.2 quality at ~8% of the cost |
No single model wins every situation. Claude Opus 4.6 leads quality benchmarks but costs 35× more on input than DeepSeek V3.2 — and 125× more than inference.net's Schematron-8B. DeepSeek V3.2 is the standout value play — near-frontier reasoning at commodity prices. For anything high-volume and routine, open-source models via inference.net or Groq save serious money without much quality degradation on most tasks.
The sections below back up every recommendation with numbers.
---
Frontier Model Pricing: OpenAI, Anthropic, Google, and Mistral
Frontier models are developed and served directly by the labs. They're where most developers start — and for good reason. OpenAI, Anthropic, Google, and Mistral invest heavily in training, safety, and evaluation infrastructure, and it shows in benchmark results. That investment comes with a price tag that varies more than most developers expect.
The table below covers current pricing for all major frontier models, including the most recent releases as of February 2026.
| Provider | Model | Input $/1M | Output $/1M | Context Window | Best For | Released |
|---|---|---|---|---|---|---|
| OpenAI | GPT-5.2 | $1.75 | $14.00 | 128K | All-around flagship; strongest ecosystem | 2025 |
| OpenAI | GPT-4.1 | $2.00 | $8.00 | 128K | Strong general capability; better output pricing | 2025 |
| OpenAI | GPT-4.1 mini | $0.40 | $1.60 | 128K | Cost-efficient general tasks at scale | 2025 |
| OpenAI | o3 | $10.00 | $40.00 | 128K | Complex reasoning, math, advanced coding | 2025 |
| OpenAI | o3-mini | $1.10 | $4.40 | 128K | Budget reasoning tier; simpler logic tasks | 2025 |
| Anthropic | Claude Opus 4.6 | $5.00 | $25.00 | 200K | Maximum quality; nuanced reasoning, long-context | Feb 5 2026 |
| Anthropic | Claude Sonnet 4.x | $3.00 | $15.00 | 200K | Coding, writing, instruction-following | 2025 |
| Anthropic | Claude Haiku 4.x | $0.80 | $4.00 | 200K | Fast responses; summarization, extraction | 2025 |
| Gemini 3.1 Pro | $2.00 | $12.00 | 1M | Best output price in flagship tier; multimodal | Feb 19 2026 | |
| Gemini Flash 3.1 | $0.35 | $1.05 | 1M | Fast inference; high-volume multimodal workloads | 2025 | |
| Gemini 3.1 Nano | $0.10 | $0.40 | 32K | Ultra-budget; on-device-class tasks | 2025 | |
| Mistral | Mistral Large | $2.00 | $6.00 | 128K | European data residency; strong coding | 2025 |
| Mistral | Mistral Small | $0.20 | $0.60 | 32K | Cost-efficient general tasks | 2025 |
| Mistral | Codestral | $0.30 | $0.90 | 32K | Code completion; in-editor assistants | 2025 |
What the Numbers Tell You
Claude Opus 4.6 is the most expensive frontier model at $5.00 per million input tokens and $25.00 per million output tokens. It leads on quality benchmarks — particularly reasoning, coding, and long-context comprehension. If you need the absolute ceiling of model capability for a mission-critical, customer-facing product, it earns its price. For most other workloads, it's overkill.
GPT-5.2 offers the strongest quality-to-cost ratio among flagship models. At $1.75/$14.00 per million tokens, it costs 65% less than Claude Opus 4.6 on input tokens while matching or exceeding it on many popular benchmarks. OpenAI's ecosystem advantages — mature function calling, embeddings, batch mode, fine-tuning pipeline — add practical value beyond raw model quality.
Gemini 3.1 Pro, released February 19, 2026, is the price leader in the flagship tier. At $2.00/$12.00 per million tokens, it's directly competitive with GPT-5.2 on quality metrics and comes in slightly better on output pricing. Google's multimodal capabilities make it a natural choice for workloads that mix text with images, video, or audio.
Sub-tier models are a legitimate optimization, not a compromise. GPT-4.1 mini, Claude Haiku 4.0, and Gemini Flash 3.1 typically cost 8–12× less than their flagship counterparts. For tasks where a flagship scores 95 and a mini scores 88, the mini wins on business logic. The mistake is defaulting to flagship models when a sub-tier would do — not the sub-tier models themselves.
Context window size affects real costs significantly. A 128K context window lets you process longer documents, but it also means a single call can get expensive when your system prompt and conversation history are large. Prompt caching (covered in Section 5) is essential for any workflow that reuses long context repeatedly.
---
Open-Source Inference Providers: Same Models, a Fraction of the Cost
Most LLM API pricing comparisons have the same blind spot: they treat OpenAI, Anthropic, and Google as the entire market.
There's a parallel ecosystem — Groq, Together AI, Fireworks AI, and inference.net — that hosts the same open-weight models at dramatically lower prices. These providers don't bear model R&D costs, so they compete on infrastructure efficiency and pass those savings to developers. The models they serve aren't compromises. Meta's Llama 4, DeepSeek V3.2, Mistral, and Qwen 2.5 are legitimate competitors to frontier models across a wide range of production tasks.
None of the existing guides cover this category — meaning developers who rely on them often pay more than they need to.
The Four Providers
Groq runs on custom LPU (Language Processing Unit) hardware purpose-built for inference throughput. Where Groq wins isn't always cost-per-token — it's speed. For latency-sensitive applications — live user interactions, real-time voice pipelines, streaming interfaces — Groq's hardware advantage delivers response times that GPU-based providers struggle to match. They also offer a generous free tier suited for prototyping and load testing.
Together AI has the broadest model library in this group, with over 100 open models accessible through a single API. Their platform supports batch inference and fine-tuning, making them a natural choice when you're still evaluating which model fits your task before committing to production. Serverless pricing is competitive; reserved-instance pricing goes lower for predictable workloads.
Fireworks AI positions itself as production-grade infrastructure for open-source inference. SLA commitments and uptime guarantees sit closer to enterprise providers than to experimental platforms. Pricing is competitive, particularly for Llama and Mistral variants. A good fit when you want open-source cost savings but can't afford deployment headaches.
inference.net has the most aggressive pricing in this comparison — and it's not close. Schematron-8B at $0.04/$0.10 per million tokens is the lowest-cost model in this guide. Their Llama 4 and DeepSeek pricing undercuts all other providers in the table below. If cost-per-token is the primary constraint, this is the starting point.
Pricing Across Providers: Popular Open-Weight Models
| Model | Params | Groq In/Out | Together AI In/Out | Fireworks AI In/Out | inference.net In/Out | vs GPT-5.2 input |
|---|---|---|---|---|---|---|
| Llama 4 Scout | 17B | $0.11 / $0.34 | $0.18 / $0.18 | $0.16 / $0.16 | $0.08 / $0.15 | ~95% cheaper |
| Llama 4 Maverick | 70B | $0.50 / $0.50 | $0.90 / $0.90 | $0.80 / $0.80 | $0.35 / $0.40 | ~80% cheaper |
| DeepSeek V3.2 | 671B | $0.27 / $0.27 | $0.18 / $0.18 | $0.22 / $0.22 | $0.14 / $0.28 | ~92% cheaper |
| Mistral Small | 22B | $0.20 / $0.20 | $0.20 / $0.60 | $0.16 / $0.16 | $0.10 / $0.20 | ~94% cheaper |
| Schematron-8B | 8B | — | — | — | $0.04 / $0.10 | ~98% cheaper |
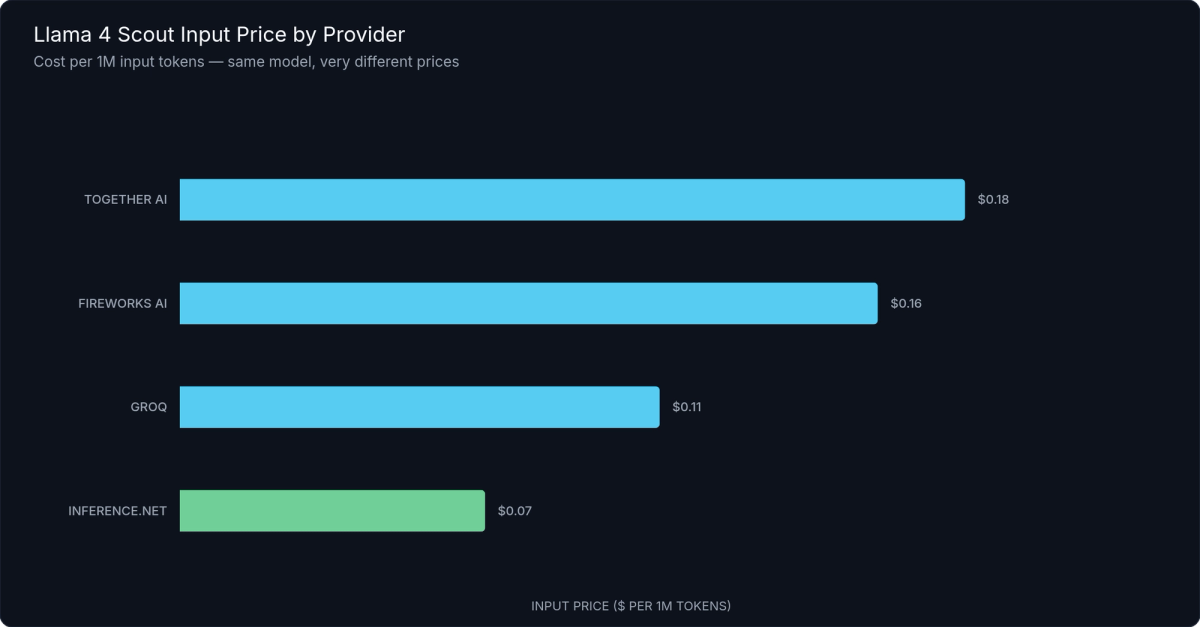
Figure 1: Llama 4 Scout Input Price Across Inference Providers — inference.net leads with the lowest per-token cost at $0.08/1M input tokens
What the Numbers Tell You
DeepSeek V3.2 is approximately 92% cheaper than GPT-5.2 at $0.14/$0.28 per million tokens versus $1.75/$14.00. On benchmark evaluations, DeepSeek V3.2 performs at roughly 85–90% of GPT-5.2 quality on knowledge retrieval, coding, and reasoning tasks. For the majority of production workloads, the quality gap is invisible to end users.
inference.net consistently offers the lowest per-token prices in this comparison, particularly on smaller and quantized models. Schematron-8B at $0.04/$0.10 is purpose-built for high-volume, cost-first workloads: classification, extraction, embedding generation, and RAG retrieval. Llama 4 Scout via inference.net is similarly priced for tasks that need more headroom.
Groq wins on throughput, not necessarily price. For latency-sensitive use cases — live chatbots, voice applications, developer tools with sub-second UX expectations — Groq's LPU advantage is measurable and worth the modest premium over the cheapest per-token options.
Together AI is best for model experimentation. One API key gives you access to over 100 models. Once you've identified your production candidate, you can price-shop Fireworks AI, inference.net, or Groq for the same model. Use Together AI to decide, then optimize on price.
Switching a production workload from GPT-5.2 to an equivalent open-weight model via inference.net can reduce monthly API spend by 80–95%. For a team running $10,000 per month in API costs, that's $8,000–$9,500 back in budget — before any other optimization.
---
How LLM API Pricing Works: Tokens, Context Windows, and Hidden Costs
LLM API pricing is based on the number of tokens processed — both the text you send (input tokens) and the text the model generates (output tokens). Most providers charge separately for input and output, with output typically costing 4–10× more due to higher compute requirements. Understanding the mechanics is what separates teams that accurately forecast AI costs from those that get surprised on their monthly bill.
Tokens: The Unit of Billing
A token is roughly 0.75 words in English — about four characters. A typical page of prose runs around 750 tokens. The ratio shifts for code (more tokens per word due to symbols and whitespace) and non-Latin scripts (often 1–2 characters per token, making them measurably more expensive to process at scale).
You don't pay for the tokens you think you're sending — you pay for the tokens the model actually processes. That distinction becomes significant once conversation history starts accumulating across turns.
Input vs. Output Asymmetry
Output tokens require more GPU compute to generate than input tokens require to process. This is why output pricing is consistently higher: often 4× for standard models, up to 10× for premium tiers. Claude Opus 4.6's $5.00/$25.00 pricing represents a 5× multiplier; GPT-5.2's $1.75/$14.00 is 8×.
This asymmetry has practical consequences. Summarization, extraction, and classification tasks produce short outputs relative to their inputs — they're relatively affordable. Long-form generation, detailed analysis, and agentic workflows with extended responses are where output costs concentrate. Designing for shorter outputs where possible rarely gets the attention it deserves as a cost lever.
Batch discounts from OpenAI and Anthropic cut costs by up to 50% by queuing requests for off-peak processing. If your workload isn't latency-sensitive — background analysis, overnight data enrichment, scheduled jobs — batching is the highest-ROI single configuration change available.
Context Window Costs and Prompt Caching
Every token in your context window — system prompt, conversation history, retrieved documents — is billed as input on every API call. A 10,000-token system prompt at $1.75/1M costs $0.0175 per call. At 100,000 calls per month, that's $1,750 in system prompt costs alone, before any user message or response.
Prompt caching eliminates most of this. Both OpenAI and Anthropic support caching for repeated context segments, reducing cached-token costs by 80–90%. For RAG-heavy applications, customer support bots with static system prompts, or any multi-turn workflow, enabling prompt caching is typically the highest-return change you can make — and it usually takes only a few lines of code.
The Four Hidden Cost Sources Most Teams Miss
- Conversation history grows silently. Each turn in a multi-turn chat appends to the context sent on the next call. A 20-turn conversation sends all 20 prior turns as input every time. Implement context pruning or rolling summarization for long sessions.
- Not enabling prompt caching. Repeated system prompts without caching means paying full input price every call.
- Not batching non-urgent requests. Async jobs don't need real-time responses — batch them for the 40–50% discount.
- Flagship models for routine tasks. Using GPT-5.2 for FAQ responses is paying first-class fares for a 15-minute flight.
---
Thinking Models and Extended Reasoning: What They Actually Cost
Thinking models — OpenAI's o3 and o3-mini, Claude's extended thinking mode, Gemini Flash 3.1 Thinking — generate internal chain-of-thought reasoning before producing a final response. This reasoning process genuinely improves performance on complex logic, mathematics, advanced coding, and multi-step planning.
The catch: thinking tokens are billed, and they're invisible.
The Invisible Token Problem
When you call o3 or enable Claude's extended thinking mode, the model generates thousands of reasoning tokens internally before writing its visible response. Those tokens are billed at the standard output token rate but don't appear in your final output. A short, confident-looking answer can have a 15,000-token reasoning chain behind it that you never see — but always pay for.
This is where developers often get surprised — especially when they've been estimating costs based on response length alone. The billing meter runs on the full reasoning process, not just the response.
| Model | Provider | Input $/1M | Output $/1M | Thinking Tokens Billed As | Max Context | Best For |
|---|---|---|---|---|---|---|
| o3 | OpenAI | $10.00 | $40.00 | Output rate (hidden in response) | 128K | Advanced math, complex code, multi-step logic |
| o3-mini | OpenAI | $1.10 | $4.40 | Output rate (hidden in response) | 128K | Budget reasoning; simpler logical problems |
| Claude Opus 4.6 (extended thinking) | Anthropic | $5.00 | $25.00 | Output rate (hidden in response) | 200K | Long-context reasoning; nuanced complex instructions |
| Gemini Flash 3.1 Thinking | $0.35 | $1.05 | Output rate (hidden in response) | 1M | Fast reasoning at budget price; lighter planning tasks |
When Thinking Models Are Worth It
Thinking models excel at tasks where standard models fail frequently — complex mathematical proofs, multi-constraint planning, advanced code generation, and logical reasoning across long chains of dependencies. The economic case is counterintuitive but real: if a standard model completes a hard task correctly 40% of the time and a thinking model completes it 95% of the time, the thinking model can be cheaper per successful outcome despite costing more per call.
A practical rule of thumb: if you're re-prompting a standard model three or more times to get a reliable answer on a specific task type, evaluate a thinking model. The retry cost often exceeds the thinking token premium — and developer time spent on retry logic has its own cost.
When to Skip Thinking Models
For routine production tasks — customer support Q&A, text summarization, data extraction, intent classification, semantic search — standard models perform at 95%+ quality and thinking models just add cost.
Switching from o3 to GPT-4.1 mini for a high-volume classification pipeline can reduce costs by 50–100×. The goal is matching the model to the task's actual complexity requirements, not to the marketing.
---
Real-World Cost Examples: What You'll Actually Pay
Per-token pricing is abstract until you apply it to actual workloads. Here are five representative production scenarios with cost estimates across model tiers. These numbers use the confirmed pricing from this guide and illustrate why model selection is the dominant cost variable.
| Workload | Volume/mo | Avg Tokens/Call | GPT-5.2/mo | GPT-4.1 mini/mo | inference.net/mo |
|---|---|---|---|---|---|
| Customer support chatbot | 100K conversations | 500 in / 200 out | $368 | $52 | $4 |
| Document summarization | 10K documents | 5,000 in / 500 out | $158 | $28 | $3 |
| Code review assistant | 50K reviews | 2,000 in / 800 out | $735 | $104 | $8 |
| RAG / search augmentation | 1M queries | 1,500 in / 300 out | $6,825 | $1,080 | $90 |
| Reasoning agent | 5K complex tasks | 3,000 in / 2,000 out | $166 | $22 | <$2 |
Breaking Down the Numbers
Customer support chatbot at 100K conversations/month (500 input + 200 output tokens average): GPT-5.2 runs approximately $368/month. Running the same workload on inference.net costs roughly $4/month — a $364/month difference on a single application before any other optimization.
Document summarization pipeline at 10K documents/month (5,000 input + 500 output tokens): The input-heavy nature of this task concentrates cost on the input side. GPT-5.2 costs around $158/month; inference.net drops it to $3/month. For a team running 100K documents/month, those ratios become $1,580 versus $30.
RAG-augmented search at 1M queries/month (1,500 input + 300 output tokens): This is where scale transforms provider choice into a financial decision. GPT-5.2 totals approximately $6,825/month. inference.net at $0.04/$0.10 per million tokens brings the same query volume to $90/month. At that scale, provider selection outweighs every other cost optimization combined.
Reasoning agent at 5K complex tasks/month (3,000 input + 2,000 output tokens): This is where thinking models enter the comparison. Running o3 on complex reasoning tasks with extended thinking can push costs past $2,000/month for this volume. GPT-5.2 standard handles the same call count for around $166/month. DeepSeek V3.2 via inference.net drops that to under $5/month — appropriate when frontier-level reasoning isn't required for every task in the agent pipeline.
Estimate Before You Build
Before committing to a model for production, estimate your costs using token counts from your actual prompt and response samples:
"""
LLM API Cost Estimator
Estimates monthly API costs across multiple model tiers
using tiktoken for accurate token counting.
"""
import tiktoken
from typing import Dict, Tuple
# Model pricing: (input_price_per_1M, output_price_per_1M)
MODEL_PRICING: Dict[str, Tuple[float, float]] = {
"claude-opus-4.6": (5.00, 25.00),
"gpt-5.2": (1.75, 14.00),
"gemini-3.1-pro": (2.00, 12.00),
"gpt-4.1": (2.00, 8.00),
"gpt-4.1-mini": (0.40, 1.60),
"deepseek-v3.2": (0.14, 0.28),
"mistral-small": (0.20, 0.60),
"llama-4-scout-groq": (0.11, 0.34),
"inference.net-llama4": (0.08, 0.15),
"inference.net-sch8b": (0.04, 0.10),
}
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""Count tokens in text using tiktoken."""
try:
enc = tiktoken.encoding_for_model(model)
except KeyError:
enc = tiktoken.get_encoding("cl100k_base")
return len(enc.encode(text))
def estimate_cost(input_tokens: int, output_tokens: int, model: str) -> float:
"""Calculate cost in USD for a single API call."""
if model not in MODEL_PRICING:
raise ValueError(f"Unknown model: {model}")
input_price, output_price = MODEL_PRICING[model]
return (input_tokens * input_price + output_tokens * output_price) / 1_000_000
def compare_models(sample_input: str, sample_output: str, calls_per_month: int) -> None:
"""Print cost comparison across all models for a given workload."""
input_tokens = count_tokens(sample_input)
output_tokens = count_tokens(sample_output)
print(f"\nToken counts — Input: {input_tokens:,} Output: {output_tokens:,}")
print(f"Monthly volume: {calls_per_month:,} calls\n")
print(f"{'Model':<30} {'Per Call':>10} {'Monthly':>12}")
print("-" * 55)
results = []
for model in MODEL_PRICING:
per_call = estimate_cost(input_tokens, output_tokens, model)
monthly = per_call * calls_per_month
results.append((model, per_call, monthly))
results.sort(key=lambda x: x[2])
for model, per_call, monthly in results:
print(f"{model:<30} ${per_call:>9.4f} ${monthly:>11,.2f}")
if __name__ == "__main__":
# Example: customer support chatbot
SYSTEM_PROMPT = """You are a helpful customer support agent.
Answer questions clearly and concisely."""
SAMPLE_USER_MSG = "How do I upgrade my subscription plan?"
SAMPLE_RESPONSE = """To upgrade your subscription, log in to your account dashboard
and navigate to Settings > Billing > Change Plan. Select your new plan and confirm.
The upgrade takes effect immediately and you'll be prorated for the remainder
of your billing cycle."""
CALLS_PER_MONTH = 100_000
print("=== LLM API Cost Estimator ===")
print("Workload: Customer Support Chatbot (100K calls/month)")
compare_models(SYSTEM_PROMPT + SAMPLE_USER_MSG, SAMPLE_RESPONSE, CALLS_PER_MONTH)The cost estimator uses tiktoken to count tokens from real text samples, calculates monthly projections across multiple model tiers, and outputs a side-by-side comparison. Running it against your actual system prompts and expected response distributions before choosing a provider catches the billing surprises that hit most teams in month two.
---
Cost vs. Performance: Which Models Deliver the Best Value
Cheapest isn't best value. Best value is quality per dollar — the benchmark performance you get for each dollar spent. When you normalize model capability against cost, the ranking changes dramatically from pure benchmark leaderboards.
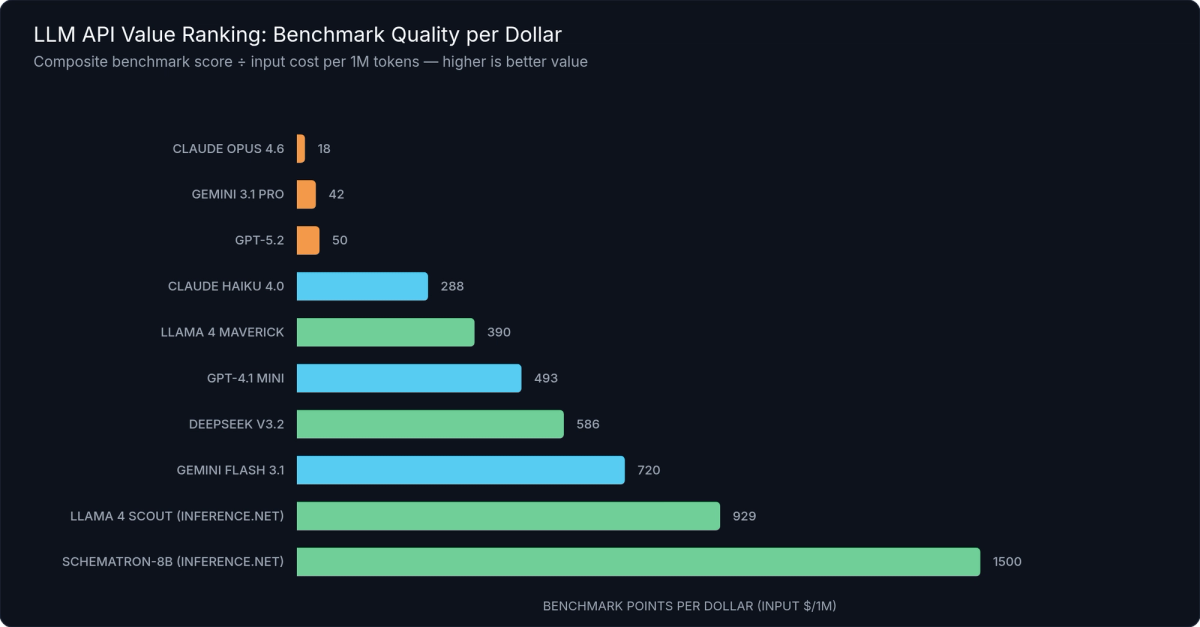
Figure 2: LLM Models by Benchmark Score per Dollar — DeepSeek V3.2 and inference.net models lead on value; thinking models and Claude Opus rank lowest for non-reasoning tasks
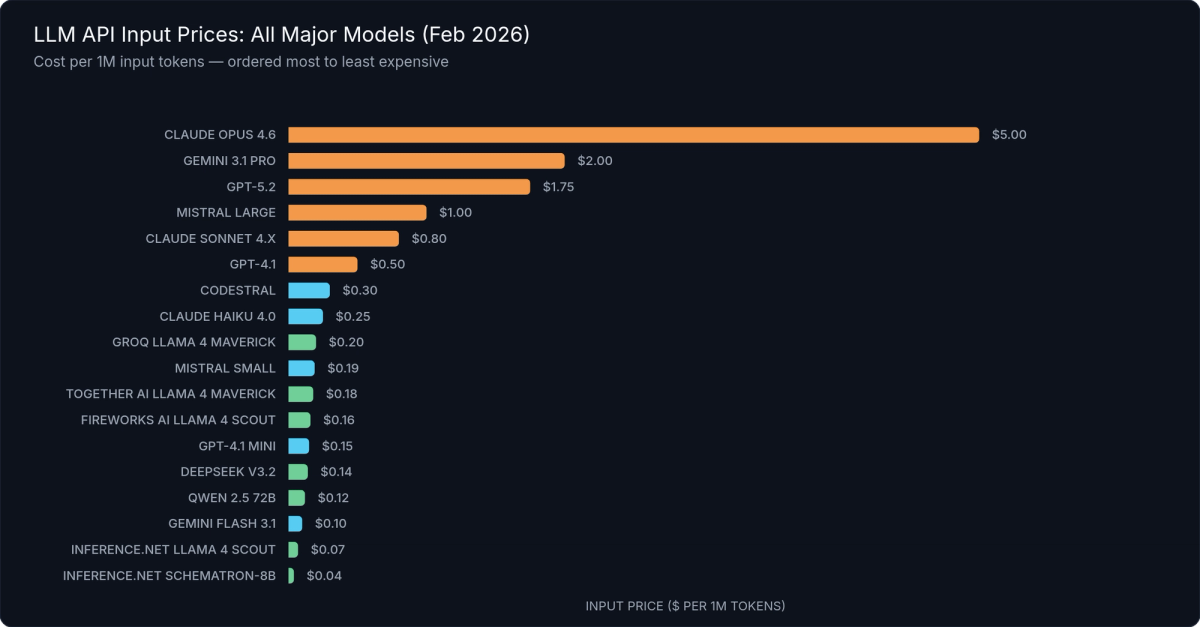
Figure 3: LLM API Input Prices per 1M Tokens — All 18 Models — ordered by price descending, from Claude Opus 4.6 ($5.00) to inference.net Schematron-8B ($0.04)
The Value Leaders
DeepSeek V3.2 is the value leader in this comparison. At $0.14/$0.28 per million tokens, it achieves approximately 85–90% of GPT-5.2's benchmark performance at roughly 8% of the cost. For knowledge retrieval, coding, summarization, and reasoning-lite tasks, the quality gap is frequently imperceptible in production. This is the first model to evaluate if you're currently on a frontier API and want to reduce costs without reducing quality.
GPT-5.2 is the best value among frontier flagship models. Despite being the second-most-capable model in this comparison, it costs 65% less than Claude Opus 4.6 on input tokens and outperforms it on many popular benchmarks. If you need frontier-tier capability, GPT-5.2 is the rational default.
inference.net's smaller models punch above their weight for structured output tasks. Schematron-8B at $0.04/$0.10 and comparable compact models score strongly on task-specific benchmarks when prompts are well-engineered — particularly for classification, extraction, and RAG retrieval where precision on a narrow task matters more than general intelligence.
The Value Traps
Thinking models score poorly on the value metric for routine tasks. o3 tops hard reasoning benchmarks but delivers a ruinous cost-per-quality ratio for anything that doesn't require deep chain-of-thought. It's a specialized tool that too many teams use as a general one.
Claude Opus 4.6, for all its capability, struggles to justify its price on tasks where GPT-5.2 performs at 98% quality. Input tokens cost $5.00 versus GPT-5.2's $1.75 — nearly 3× more for input alone, and output is proportionally steeper. Unless your evaluation harness consistently shows Claude Opus outperforming GPT-5.2 on your specific task, that premium rarely pays off.
A Simple Decision Framework
Three questions narrow the field for most workloads:
- Does this task require frontier-level quality? If accuracy on hard reasoning, complex code generation, or nuanced judgment calls is non-negotiable, evaluate GPT-5.2 or Claude Opus 4.6.
- Is this a reasoning-heavy task where standard models fail frequently? Evaluate o3 or Claude extended thinking and measure cost-per-successful-outcome, not cost-per-call.
- Is this a high-volume, routine task? Use inference.net or DeepSeek V3.2. For extraction, classification, RAG, and summarization at scale, the cost savings are hard to argue against.
Most production systems have workloads in all three buckets. Routing tasks to the appropriate model tier — frontier for hard cases, budget for routine — is how cost-efficient AI teams operate.
---
How to Choose the Right LLM API for Your Budget
With 30+ models and six providers, the right choice comes down to three budget tiers matched to workload requirements.
Tier 1 — Enterprise / Quality-First
Target pricing: above $0.50 per 1K output tokens
Use this tier when frontier quality is non-negotiable, the application is customer-facing with brand risk, or the task involves complex multi-step reasoning where model quality directly determines outcomes.
Recommended models:
- Claude Opus 4.6 — highest benchmark quality; best for nuanced reasoning, complex instructions, and long-context tasks
- GPT-5.2 — strong across all domains, best ecosystem support, 65% cheaper on input than Opus 4.6 with comparable performance
- Gemini 3.1 Pro — best input/output pricing in the flagship tier at $2.00/$12.00; strong multimodal support
Cost optimization at this tier: Enable prompt caching to cut repeated context costs by 80–90%. Use batch mode for non-real-time requests to capture the 50% discount. Evaluate whether Claude Sonnet 4.x or GPT-4.1 handles 80% of your requests before defaulting to flagship models for everything.
Tier 2 — Growth / Balanced
Target pricing: $0.05–$0.50 per 1K output tokens
Use this tier when quality matters but volume is scaling, the use case is internal tooling or developer-facing, or moderate reasoning capability is needed without hard frontier requirements.
Recommended models:
- DeepSeek V3.2 ($0.14/$0.28) — the standout choice at this tier; near-frontier quality at budget pricing
- GPT-4.1 — solid general capability and strong OpenAI ecosystem integration
- Claude Sonnet 4.x — excellent for code and long-form writing; fine-tuning available
- Gemini Flash 3.1 — fast inference, competitive pricing, Google ecosystem advantages
DeepSeek V3.2 deserves emphasis: for teams currently paying frontier prices for workloads that don't require frontier quality, switching to V3.2 is typically the highest-impact, lowest-effort cost reduction available.
Tier 3 — High-Volume / Budget
Target pricing: below $0.05 per 1K output tokens
Use this tier when token cost is the primary constraint, tasks are routine (classification, extraction, RAG retrieval, semantic similarity), or volume is high enough that API cost dominates all other engineering expenses.
Recommended models:
- inference.net Schematron-8B ($0.04/$0.10) and Llama 4 Scout — lowest prices in this comparison; purpose-built for cost-first, high-volume workloads
- Groq Llama 4 / Mistral — best inference latency in this tier; choose when response speed matters alongside cost
- Together AI — widest model selection for experimenting with open models at competitive prices
Both inference.net and Groq offer free tiers suitable for initial evaluation and development. Use the free tier to validate model quality on your task before committing to paid usage.
One universal rule across all tiers: Implement prompt caching before switching models. It reduces costs by 20–40% on most workflows with minimal engineering effort. Do this first, then evaluate model tier changes if further savings are needed.
---
Frequently Asked Questions
What is the cheapest LLM API available?
inference.net's Schematron-8B at $0.04/$0.10 per million input/output tokens is the most affordable option in this comparison. For tasks requiring more capable models, DeepSeek V3.2 at $0.14/$0.28 delivers near-frontier reasoning at commodity pricing — making it the best value-per-capability in the budget tier.
How much does the OpenAI API cost in 2026?
OpenAI's flagship GPT-5.2 costs $1.75 per million input tokens and $14.00 per million output tokens. More affordable options include GPT-4.1 mini, which is significantly cheaper and appropriate for many routine production tasks. OpenAI's batch mode offers up to 50% off standard pricing for non-latency-sensitive workloads.
What is the Claude API price?
Claude Opus 4.6, released February 5, 2026, costs $5.00 per million input tokens and $25.00 per million output tokens — the most expensive frontier model in this comparison. Claude Sonnet 4.x and Haiku 4.x offer substantially lower-cost tiers that cover the majority of production workloads at a fraction of Opus pricing.
Is there a free LLM API?
Groq offers a free tier with rate limits well-suited for prototyping and development. Google's Gemini API includes free-tier access with usage quotas. For production workloads, all major providers charge per token — there are no production-grade free APIs without significant rate limits.
How do I calculate LLM API costs?
Multiply your expected input token count by the input rate, and your output token count by the output rate, then sum them. Use OpenAI's tiktoken library or equivalent tokenizers to estimate token counts from your actual text samples. The Python cost estimator in the Real-World Cost Examples section automates this across multiple models simultaneously.
What are thinking tokens and why are they expensive?
Thinking tokens are the internal chain-of-thought reasoning steps generated by models like o3 and Claude with extended thinking enabled. They're billed at the standard output token rate but don't appear in the final response, making them an invisible cost multiplier. A single complex request can generate tens of thousands of thinking tokens you never see but always pay for.
Which LLM API is best for coding?
For high-stakes code generation and complex debugging, Claude Opus 4.6 and GPT-5.2 lead coding benchmarks. For budget-conscious coding tasks, DeepSeek V3.2 and Mistral's Codestral perform exceptionally well at a fraction of the price. Codestral is specifically optimized for code completion and in-editor coding assistance.
What is the difference between input and output token pricing?
Output tokens require significantly more GPU compute to generate than input tokens require to process — hence asymmetric pricing. Output tokens typically cost 4–10× more than input tokens. This makes generative tasks with long responses considerably more expensive than extraction, classification, or retrieval tasks that produce short outputs.
Can I use Llama 4 via API without self-hosting?
Yes. Groq, Together AI, Fireworks AI, and inference.net all offer Llama 4 Scout and Llama 4 Maverick via API. Prices across these providers are far below frontier model rates — typically $0.07–$0.90 per million input tokens depending on model size and provider — with no infrastructure management required.
How does batch processing reduce LLM API costs?
Batch processing queues requests for off-peak processing, allowing providers to optimize GPU utilization and pass savings to users. OpenAI and Anthropic both support batch inference at approximately 40–50% off standard pricing. The trade-off is latency: batch requests complete within hours rather than seconds. Ideal for scheduled analysis, data enrichment pipelines, and any non-real-time workload.
---
Stop Overpaying for LLM API Access
Looking across 30+ models and six providers, a few things stand out: the price range is enormous — 625× from cheapest to most expensive — open-source inference providers represent a real savings opportunity that most teams haven't acted on yet, and model selection is the single largest cost lever ahead of any engineering optimization.
If you're currently using frontier APIs for every workload, the best thing you can do is audit which tasks genuinely require frontier quality — and route everything else to DeepSeek V3.2 or an inference.net model.
inference.net offers the lowest per-token pricing in this comparison across Schematron-8B, Llama 4 Scout, Llama 4 Maverick, and DeepSeek V3.2. Free-tier access is available to get started without commitment. See inference.net/pricing for current rates.
Pricing in this market shifts fast — new models drop, providers reprice, and the value rankings change with each release. Bookmark this guide; it's updated whenever major providers launch new models or adjust their rates.
---
References
- OpenAI API pricing — platform.openai.com/docs/pricing
- Anthropic Claude pricing — anthropic.com/api/pricing
- Google Gemini API pricing — ai.google.dev/pricing
- Mistral AI pricing — mistral.ai/technology/pricing
- Groq API pricing — console.groq.com/docs/pricing
- Together AI pricing — together.ai/pricing
- Fireworks AI pricing — fireworks.ai/pricing
- inference.net pricing — inference.net/pricing
- DeepSeek API pricing — platform.deepseek.com/api-docs/pricing
- OpenAI tiktoken library — github.com/openai/tiktoken
- Anthropic prompt caching documentation — docs.anthropic.com/en/docs/build-with-claude/prompt-caching
- OpenAI batch API documentation — platform.openai.com/docs/guides/batch
Meet with our research team
Schedule a call with our research team to learn more Specialized Language Models can cut costs and improve performance.