'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Introduction
We introduce LOGIC, a practical method for verifying inference in decentralized GPU networks. LOGIC utilizes compressed token-level log-probabilities and statistical testing to detect dishonest GPU operators with high accuracy, while adding minimal overhead and seamlessly integrating with existing inference engines, such as vLLM and SGLang.
The system is resistant to decode-time spoofing attacks, a critical component for permissionless networks where economic incentives might encourage GPU operators to use smaller or quantized models during generation. With payload sizes of only ~250-313 KB per 10k tokens and verification requiring just 10 single-token recomputations, LOGIC provides a production-ready and battle-tested solution for trustless inference.
Crucially, LOGIC requires no modifications to underlying inference engines and integrates naturally with standard OpenAI-style APIs, making it immediately deployable across most production environments.
Contributors: Amarjot Singh, Francesco Virga, Sean Smith, Sam Hogan
Code: https://github.com/context-labs/logic
Paper: [Coming Soon]
Trust in permissionless inference networks
For the last 18 months, Inference.net has operated a globally decentralized AI inference network with up to 10,000 heterogeneous GPUs, ranging from consumer graphics cards in a laptop to datacenter hardware in Tier 3 facilities operated by public companies. The network is permissionless by design: any GPU owner can download our client software and immediately start serving inference requests.
This openness creates a fundamental challenge: How do we verify that GPU operators are indeed running the models they claim to be running?
In a permissionless environment with economic incentives, malicious actors have multiple avenues for dishonest behavior:
- Model substitution: Running a smaller, cheaper model (e.g., swapping a 70B model for an 8B model)
- Quantization spoofing: Using lower-precision quantized models to reduce compute costs
- Speculative decoding attacks: Prefilling with the claimed model but decoding with a smaller one to save on generation costs
- Returning fraudulent text: Simply fabricating responses without running inference at all
Traditional verification mechanisms fall short. Recreating responses verbatim is expensive and often fails due to non-determinism and temperature settings. Cryptographic approaches like zero-knowledge proofs are orders of magnitude too slow and expensive for modern LLM inference. Activation-based methods require heavy instrumentation of inference engines and are sensitive to hardware non-determinism.
Most critically, many existing verification methods only validate the prefill phase. In permissionless networks where participants are economically motivated to minimize costs, decode-time spoofing becomes the primary attack vector. An operator could pre-fill honestly with the correct model but secretly switch to a cheaper model for generation where computational costs are highest.
Verification through log-prob distributions
LOGIC takes a fundamentally different approach: instead of trying to recreate exact activations or token sequences, we verify that the statistical distribution of the model's outputs matches what we expect from the claimed model.
The core insight is that every language model produces a unique "fingerprint" in its token-level log-probability distributions. Different models, quantization schemes, or architectural changes all produce measurably different distributions over the vocabulary at each position.
Here's how it works:
During Inference (Operator Side)
For each generated token, the untrusted GPU computes the top-k token log-probabilities—the most likely next tokens and their probabilities. These are compressed and returned alongside the generated text.
The compression pipeline is carefully designed for efficiency:
- Millilog quantization: Round log-probabilities to the nearest 0.001
- Delta encoding: Store differences between sorted log-probs
- Efficient packing: Token IDs as variable-length integers, deltas as int16
- Gzip compression: Final bytestream compression
This achieves remarkable efficiency: for k=20, we observe only ~25-31 bytes per token after compression, or approximately 250-313 KB for 10,000 tokens.
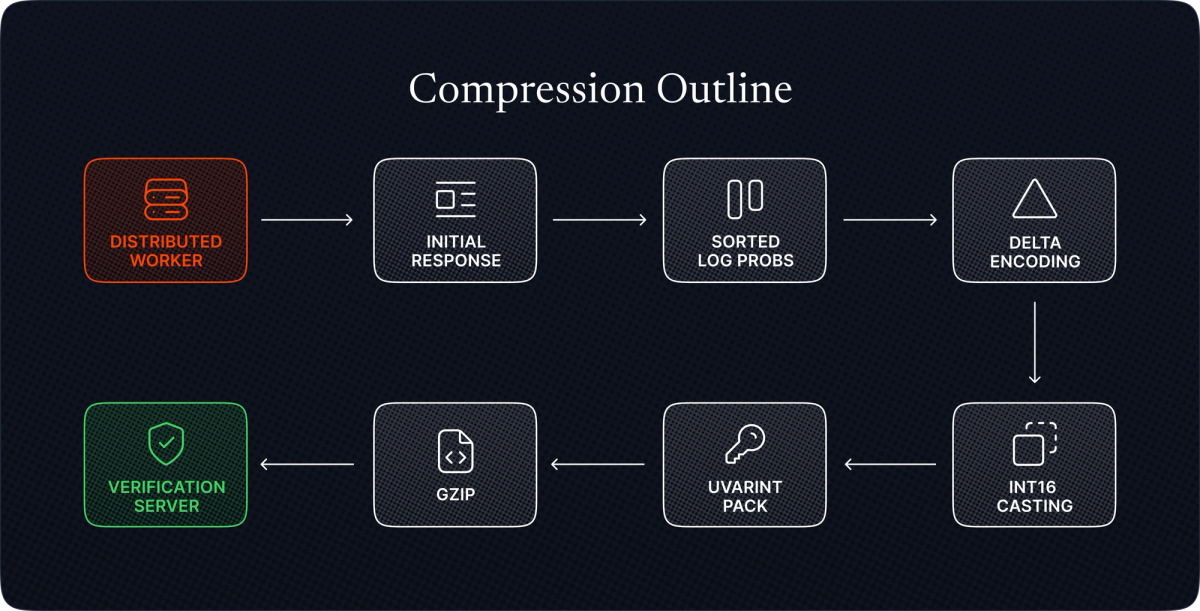
Figure 1: Compression outline showing the flow from top-k logprobs through sorting, quantization, delta encoding, and gzip compression.
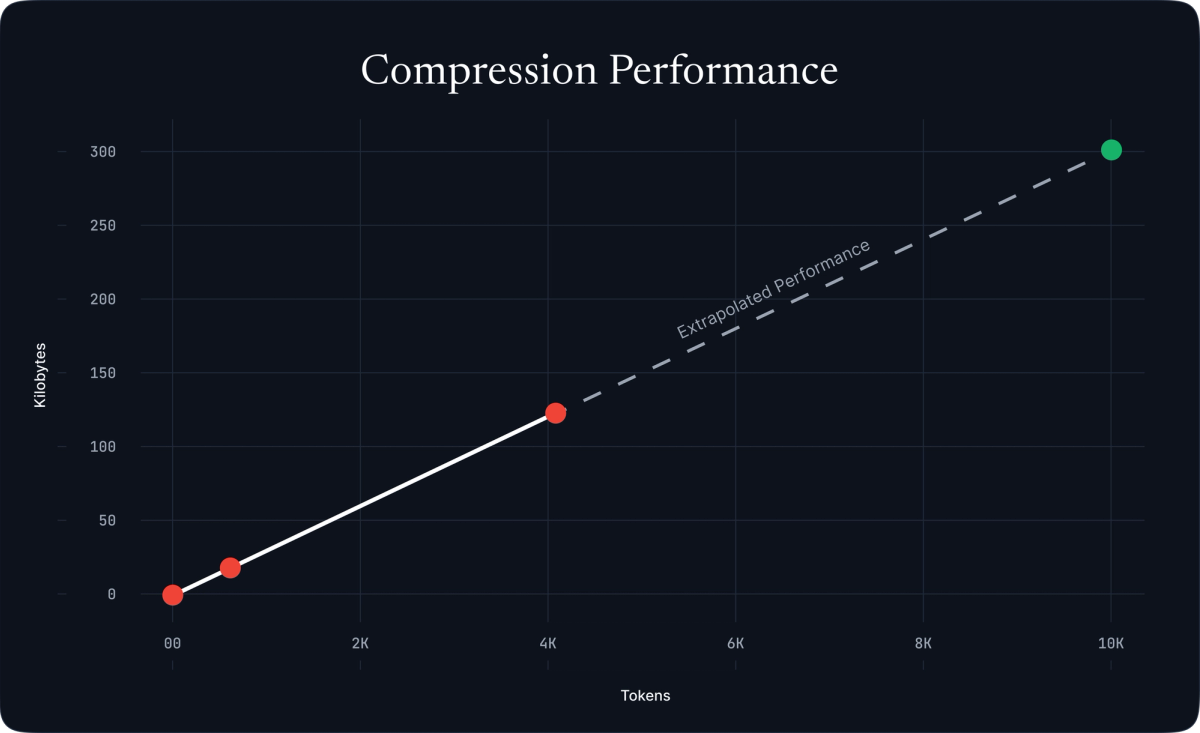
Figure 2: Compression performance across different sequence lengths, extrapolating to ~300 KB for 10k tokens.
During verification (verifier side)
The verifier doesn't need to regenerate the entire sequence. Instead, it randomly samples S positions (default: 10) from the decode phase and recomputes only those single-token distributions using KV-cache optimization.
For each sampled position t, we:
- Recompute the top-k log-probabilities using the exact context
- Align with the operator's top-k by taking the intersection: ℐₜ = Sₜʷ ∩ Sₜᵛ
- Track the overlap size mₜ = |ℐₜ| and Jaccard similarity Jₜ = mₜ/(2k - mₜ)
We then aggregate the aligned log-probabilities:
- Operator set: Lʷ = ⋃ₜ∈𝒯 {ℓₜ,ⱼʷ : j ∈ ℐₜ}
- Verifier set: Lᵛ = ⋃ₜ∈𝒯 {ℓₜ,ⱼᵛ : j ∈ ℐₜ}
Typically, this gives us n₁ = n₂ ≈ S × m samples, where m ≈ 10-20 is the average overlap.
Statistical testing
With two samples of log-probabilities in hand, we apply the Kolmogorov-Smirnov (KS) two-sample test. This non-parametric test compares the cumulative distribution functions:
Dₙ₁,ₙ₂ = sup_x |Fₙ₁(x) - Gₙ₂(x)|
where the effective sample size is nₑff = (n₁ × n₂)/(n₁ + n₂).
The KS test produces a p-value pₖₛ.
When the operator is honest and running the claimed model, the distributions match and pₖₛ ≈ 1.
When the operator is dishonest—using a different model, quantization, or spoofing strategy—the distributions diverge and pₖₛ drops dramatically.
We set a threshold pₘᵢₙ = 0.95: operators with pₖₛ ≥ pₘᵢₙ are accepted as honest.
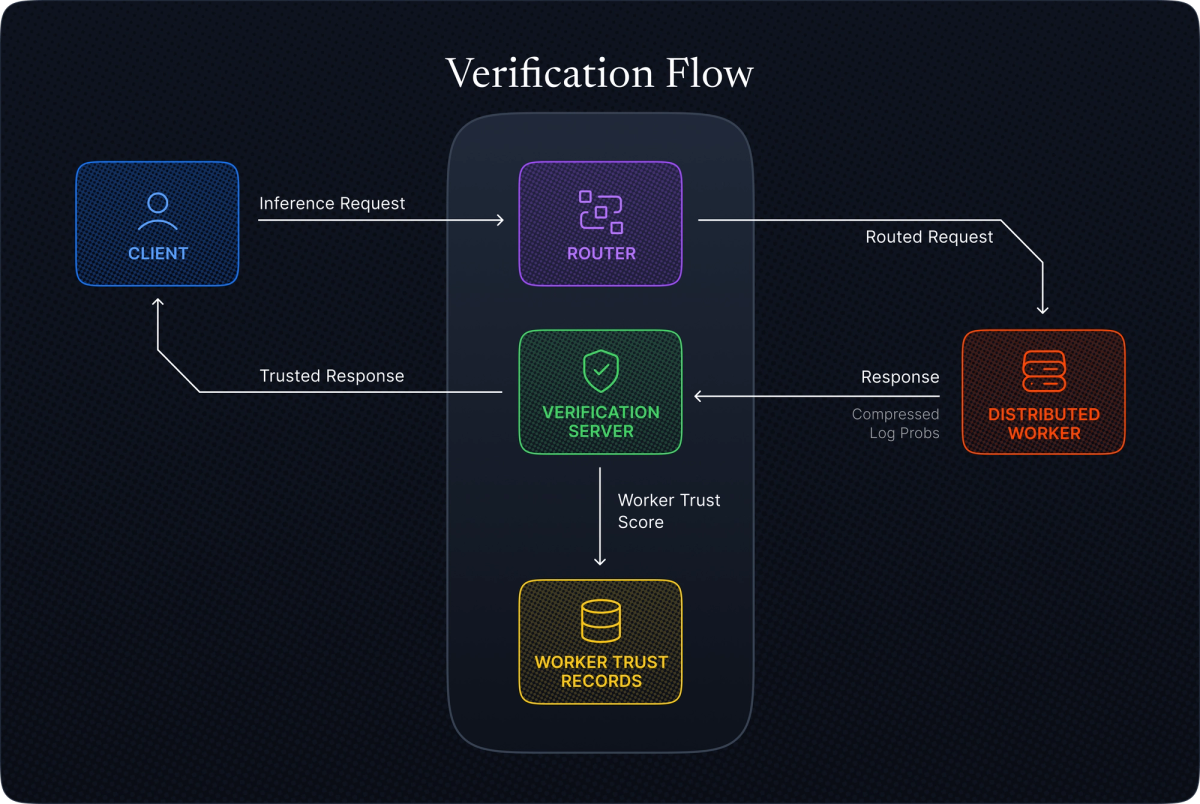
Figure 3: Complete verification flow showing the client request, operator inference with compressed logprobs, verifier sampling and recomputation, and trust record updates.
Decode-spoofing resistance
A critical vulnerability in many verification schemes is speculative decoding attacks: a dishonest operator prefills with the expensive claimed model M but switches to a cheaper model M' during decode to minimize generation costs. Since generation typically accounts for the majority of compute in long sequences, this attack offers substantial economic benefits to malicious actors.
Prefill-only verification methods (including TOPLOC) cannot detect this attack because they only validate the initial context processing. Once validation passes, the operator is free to use any model for generation.
LOGIC specifically samples from decode positions, making this attack immediately detectable. If a operator prefills with M but decodes with M', then at sampled decode positions t:
- Operator's log-probs: ℓₜ,ⱼʷ = log p_M'(iⱼᵗ | context_t)
- Verifier's log-probs: ℓₜ,ⱼᵛ = log p_M(iⱼᵗ | context_t)
These come from different conditional distributions, producing systematic differences that the KS test reliably detects. This property is essential for permissionless networks where economic incentives naturally encourage decode-time spoofing.
Robust across hardware and configurations
Unlike methods that rely on exact activation matching, LOGIC is inherently robust to hardware non-determinism. Different GPUs, CUDA versions, and numerical precision variations all affect the exact values of intermediate activations with only minimal impact on the shape of top-k log-probability distributions.
We validate this robustness by tracking both the KS p-value and Pearson correlation of log-probability pairs. Assuming small numeric drift ε with E[ε] = 0 and Var(ε) = σ², the correlation
r ≈ Var(ℓʷ) / √(Var(ℓʷ)(Var(ℓʷ) + σ²)) → 1
as σ² → 0. This dual-metric approach (KS + correlation) provides robust detection even in the presence of minor numerical variations.
Integration with existing inference engines
One of LOGIC's key advantages is its zero-modification integration with existing inference engines. Because top-k token log-probabilities are already computed by most engines as part of sampling, LOGIC simply captures and compresses this existing data.
LOGIC works seamlessly with any OpenAI-compatible API that supports returning logprops:
- vLLM: Direct integration through standard API
- SGLang: Native compatibility with existing workflows
This portability means LOGIC can be deployed across heterogeneous GPU networks without requiring operators to run custom-modified inference software. Inference clients simply return an additional compressed payload alongside their usual text responses.
The verification server is equally straightforward: it runs standard single-token inference calls with KV-caching enabled, making verification speed scale linearly with the number of sampled positions.
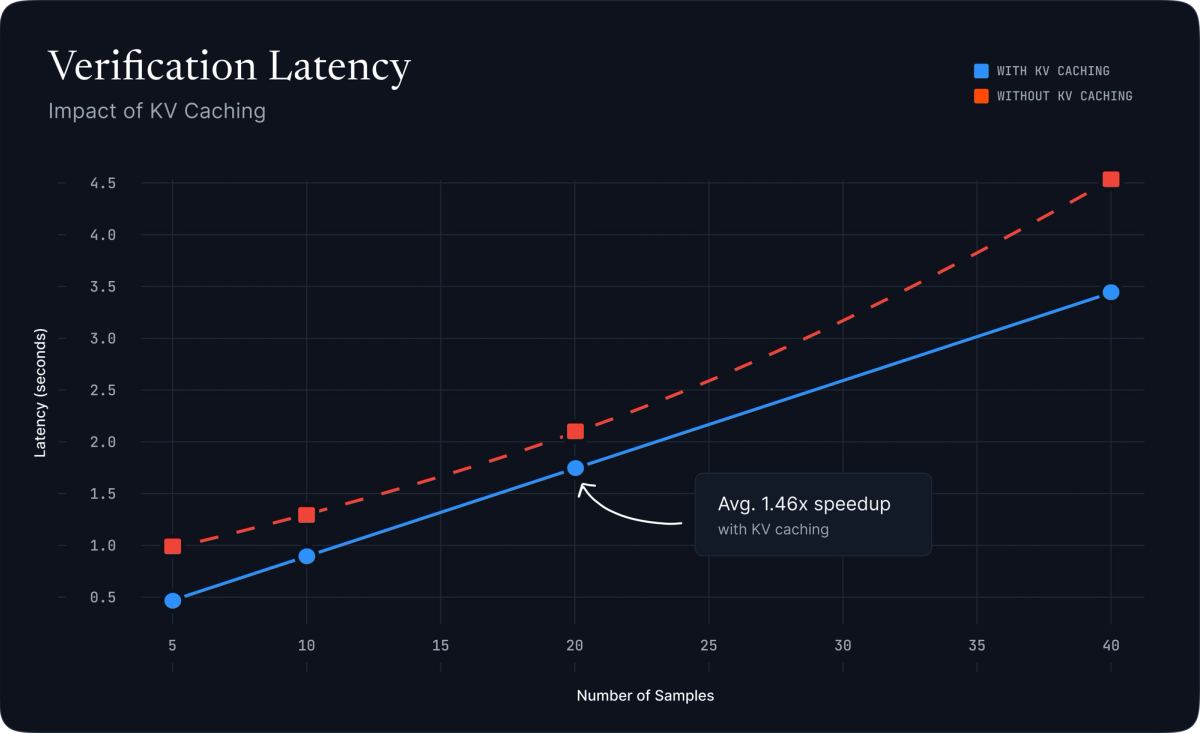
Figure 4: Verification latency vs. number of samples with and without KV caching. KV caching provides a 1.46× average speedup.
Experimental validation
We rigorously tested LOGIC on our deployed decentralized network using 10,000 diverse prompts spanning coding, reasoning, creative writing, and question answering.
Setup
- Base model: Llama-3.2-3B-Instruct (BF16)
- Dishonest baselines:
- Llama-3.2-1B-Instruct (different model size)
- Llama-3.2-3B-Instruct quantized to FP8
- Hardware: H100, RTX 4090
- Settings: k=10, samples S ∈ {5, 10, 20, 40}
Results
Honest operators are reliably accepted: Both H100 and RTX 4090 operators running the correct model yielded pₖₛ > 0.999, well above our threshold of 0.95.
Dishonest operators are reliably rejected:
- Operators running Llama-3.2-1B-Instruct produced pₖₛ ≈ 0.006
- Operators running FP8-quantized variants produced pₖₛ ≈ 0.150
Both dishonest strategies are clearly distinguishable from honest behavior.
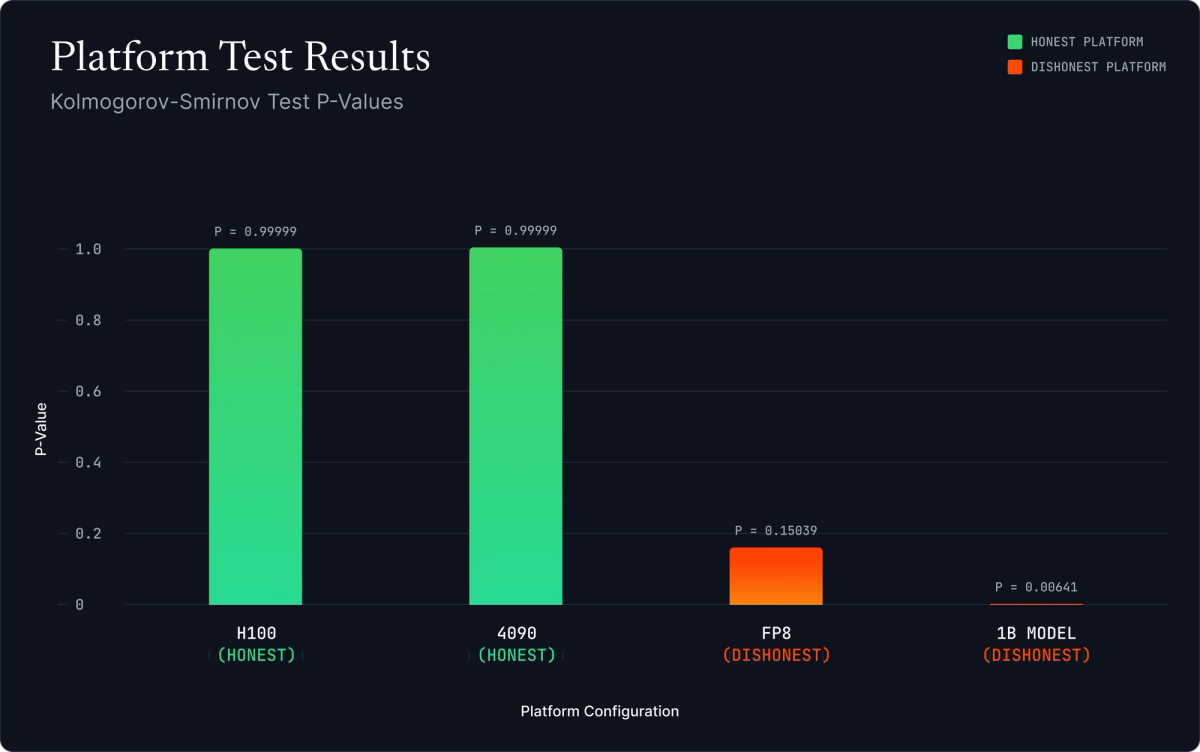
Figure 5: Distribution of KS p-values across honest operators (H100, 4090) and dishonest operators (FP8 quantization, 1B model spoofing). Clear separation enables reliable detection.
Efficiency metrics
- Payload size: 250-313 KB per 10k tokens (with k=20)
- Verification latency: 0.98 seconds for 10 samples with KV caching
- Verification compute: Only S single-token forward passes (negligible vs. full generation)
- Detection accuracy: 100% separation between honest and dishonest operators in our experiments
Comparison to other verification methods
The landscape of inference verification methods reflects different trade-offs between security guarantees, computational overhead, and practical deployability.

TOPLOC
TOPLOC compresses top-k last-layer activations with polynomial encoding, achieving impressive 1000× memory efficiency and 100× faster validation. However, in permissionless settings:
- Prefill-only validation leaves the system vulnerable to speculative decoding attacks
- GPU operators can honestly prefill with the claimed model but decode with cheaper alternatives
- In economically-motivated networks, this represents the primary attack vector
- Typically requires modifications to the underlying inference engine
I/O Fingerprint
Methods that hash intermediate activations offer strong detection capabilities but face several challenges:
- Require heavy instrumentation of inference engines with GPU-to-CPU data movement
- Sensitive to hardware non-determinism across different GPUs and CUDA versions
- Typically validate prefill only, missing decode-time spoofing attacks
- Limited native support in production inference frameworks
Zero-Knowledge Proofs
Cryptographic methods like zkSNARKs provide the strongest theoretical guarantees but remain orders of magnitude too slow and expensive for modern LLM inference. Even optimistic projections suggest ZK proof generation would cost 100× more than the original inference, making them impractical for production deployment.
LOGIC
LOGIC prioritizes practical deployability in permissionless environments:
- Decode-spoofing resistant: Samples from generation phase where economic incentives for cheating are highest
- Zero-modification integration: Works with all major inference engines out-of-the-box
- Hardware agnostic: Robust across GPU types, CUDA versions, and numerical precision
- Minimal overhead: ~250-313 KB per 10k tokens, negligible verification compute
- Statistical guarantees: Extremely close student models may require higher k, larger S, or multi-prompt challenges
For systems where participants have strong economic incentives to minimize costs decode-time verification is not optional. LOGIC's design directly addresses this threat model while maintaining practical efficiency.
Challenges and future directions
While LOGIC provides a production-ready solution for decentralized inference verification, several areas warrant further development:
Distinguishing close student models
Extremely well-distilled student models that closely mirror the teacher's log-probability distributions may be harder to distinguish. However, if a student model produces statistically indistinguishable distributions on the evaluated slice, it is effectively equivalent in behavior for those contexts. Mitigation strategies include:
- Increasing k (more tokens per position)
- Increasing S (more sampled positions)
- Multi-prompt challenges with diverse contexts
- Adaptive sampling based on operator history
Quantization and compression variants
Different quantization schemes (INT8, FP8, W8A8, etc.) and KV-cache compression methods may require empirical tuning of thresholds. Our current experiments cover FP8 quantization, but the ecosystem of optimization techniques continues to evolve.
Adaptive sampling and reverification
Network patterns, CUDA version differences, GPU defects, or other environmental factors may occasionally cause legitimate numerical drift. An adaptive sampling strategy could:
- Increase sampling density for operators with borderline p-values
- Reverify suspicious samples before making final trust decisions
- Build longitudinal trust profiles rather than single-request verdicts
Extension to other modalities
While LOGIC currently focuses on text-based LLM inference, the underlying principle (verifying output distributions rather than exact values) could extend to other domains. Multi-modal language models and diffusion-based image generation both produce output distributions that could be similarly verified.
Moving forward
LOGIC provides a production-ready path to verifiable decentralized inference. By leveraging log-probability distributions that inference engines already compute, we achieve strong verification guarantees with minimal compute and network overhead, and no engine modifications.
The method's resistance to decode-time spoofing makes it particularly well-suited for permissionless networks where economic incentives naturally encourage cost-cutting attacks.
As AI inference increasingly moves toward decentralized architectures, practical verification methods like LOGIC become essential infrastructure. We hope this work helps standardize trust mechanisms in open inference networks and enables the next generation of permissionless compute protocols.
Contributors: Amarjot Singh, Francesco Virga, Sean Smith, Sam Hogan
Code: https://github.com/context-labs/logic
Paper: [Coming Soon]
Meet with our research team
Schedule a call with our research team to learn more Specialized Language Models can cut costs and improve performance.