






The LLM era has ushered in extreme opportunity. The gold rush following James W. Marshall's discovery at Sutter's Mill in January 1848 pales in comparison to the reallocation of talent and capital triggered by ChatGPT's release in November 2022.
For a while, the AI playbook was exceedingly simple: take the top frontier LLM and wrap it in a thin product or improve your existing one.
That window is of opportunity is closing. Generalist models are now commodity inputs; everyone has them, so they confer no moat and first-mover advantage has mostly evaporated.
Where before users were impressed with simple wrappers, standing out became a process of iterating on the scaffolding around LLMs to squeeze out performance or increasingly sophisticated capabilities. LLMs went from a magical tool that could solve seemingly any problem to becoming just another tool in the toolbox of increasingly ambitious and skilled engineers.
But if the base model is wrong for your domain, no amount of scaffolding will be enough. It’s easy to make the mistake of building around the real issue: your LLM just isn’t good enough for your task, or is too slow or expensive.
When latency or cost becomes an issue, we see far too often engineers switching to a smaller, dumber model—but a quick look at the outputs shows it’s consistently hallucinating or performing poorly. Simply switching to dumber model is a bandaid and doesn’t solve the underlying issue, and users end up noticing the decline in accuracy.
Other times, projects are abandoned because the economics don’t make sense—you do the math and the cost for your project ends up being in the millions of dollars. The trillion token medal from OpenAI is little consolation, despite making a fantastic tweet.
Engineers integrating LLMs typically face four main problems:
- Expensive
- Slow
- Not good enough on your task
- Deployment constraints like reliability requirements or on-prem hosting needs
There’s a pervasive idea that with LLMs you can’t have low latency, low cost, and great quality. For generalist frontier models, that’s often true.
But if your task is constrained, it doesn’t have to be: a model tuned for your workflow can achieve all three—and can be deployed on-prem or serverlessly with far higher reliability than frontier model APIs.
Small models can give you the best outcomes on all fronts:
On cost. Small models are affordable at internet scale—a trillion input tokens on a 3B model often runs under $20k (this would cost you 1.25 mil for GPT-5). 0.5–1B models are substantially cheaper, and quantization can push costs down further.
On latency. Small models are considerably faster. Techniques like KV-cache optimization and speculative decoding turn TTFT (Time to First Token) and TPS (Tokens Per Second) into adjustable dials.
On ability. Tuned small models routinely outperform foundation models on vertical tasks and can also pair with frontier models to extend their capabilities.
On deployment. After two years building reliable LLM infrastructure, our dedicated deployments far exceed the transient reliability of OpenAI and Anthropic serverless APIs. On-prem, hybrid, serverless—wherever you need them.
We're already seeing this work in practice.
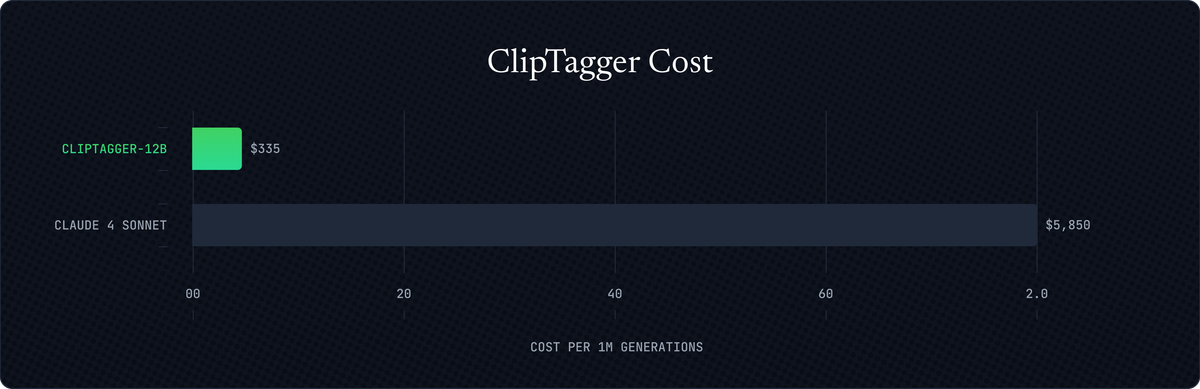
One of our customers needed to process billions of video frames, and estimated the LLM cost costs to be in the multiple millions. We trained them ClipTagger-12B—our specialized model that captions frames more accurately than Claude 4 Sonnet but 17x cheaper—which was the unlock their plan to make hundreds of millions of videos searchable.
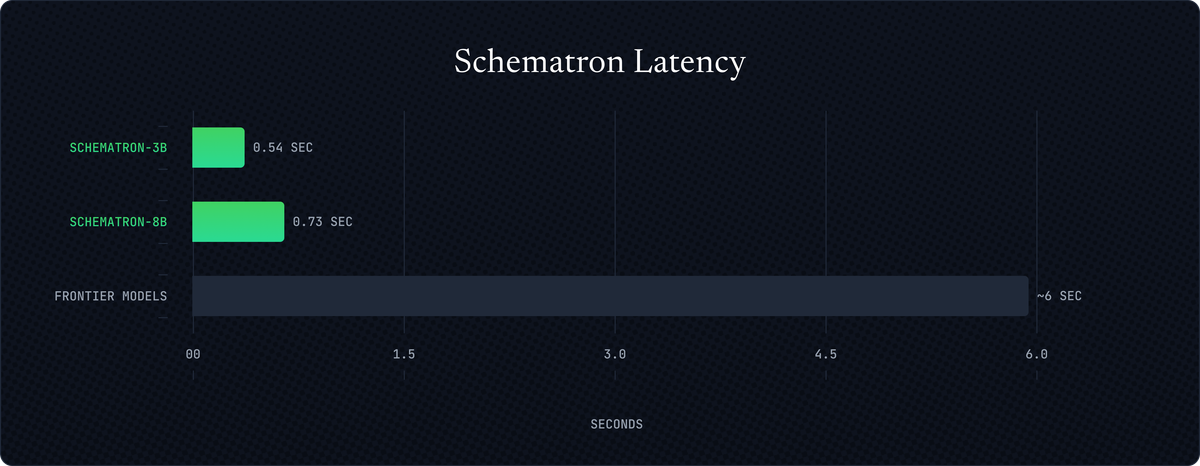
Or take browser agents. Every action requires structured data extraction from HTML. Frontier models handle this accurately but slowly—several seconds per page. Both Schematron models complete it in under a second. Frontier models are also expensive: Gemini 2.5 Flash, one of the most economical frontier options, costs ~$5k per million pages scraped. Schematron-8B does the same task for $480 just as accurately. If you're processing 1M pages per day, that's the difference between an $172k bill and one for $1.8M.
This pattern repeats everywhere. The unglamorous but critical tasks that make products work—extracting invoices, classifying documents, moderating content, captioning images. Frontier models are fundamentally not the right tools for them, bringing massive overhead to problems that need speed and precision.
We call these specialized models workhorses.
They’re not trained to both answer questions about history and solve math problems. They're trained to do one job extremely well, at massive scale, without breaking your infrastructure or budget. And because they're focused, they often outperform frontier models at their specific task.
At Inference, we train custom workhorses for companies that need models optimized for their exact workflows and data. But we've also built pre-trained workhorses for the most common bottlenecks:
ClipTagger-12B: Video frame captioning as good as Claude 4 Sonnet at 17x lower cost.
Schematron-8B: HTML to JSON extraction that beats Gemini 2.5 Flash at 10x lower cost.
Schematron-3B: 99% of Schematron-8B’s extraction capability, but 2x cheaper.
These are running in production today, processing billions of tokens with no rate limits.
The economics are compelling enough, but there's a bigger point here. When everyone's using the same frontier models, nobody has an edge. Your competitive advantage doesn't come from the latest OpenAI model—your competitors have that too. It comes from models trained on your data, optimized for your use case, running on dedicated infrastructure that actually hits your SLAs.
We believe most inference workloads will eventually run on specialized models. Not just because they're cheaper and faster, but because when you own the model, you control the tradeoffs. Lower latency becomes an optimization problem you can solve. Cost reduction becomes a quantization experiment. Quality issues get fixed with your own data. You're not dependent on the next GPT update or hoping Anthropic addresses your edge case.
Moats are built with workhorses, not generalists.
At Inference, we train you your workhorse.
Own your model. Scale with confidence.
Schedule a call with our research team to learn more about custom training. We'll propose a plan that beats your current SLA and unit cost.