'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
May 18, 2025
A Guide to Machine Learning Optimization Techniques for Smarter Models
Inference Research
Imagine you’ve built a machine learning model to analyze customer behavior and boost sales for your business. The model is accurate and delivers excellent results. But what if you could make it even smarter, faster, and more efficient? That’s the goal of machine learning optimization. By optimizing your model, you can reduce its computational cost and improve its performance. In this article, we’ll explore machine learning optimization: why it matters and how to achieve it. Doing so will help you build better machine learning models that deliver high performance with minimal computational cost.
One of the best ways to optimize machine learning models is by using AI inference APIs, like those offered by Inference. These tools can help your business achieve its objectives by streamlining machine learning model operations to make them more efficient.
What Does Optimization Mean in Machine Learning?

Optimization is adjusting a machine learning model's parameters to minimize errors and improve performance. To illustrate the concept, consider linear regression. Linear regression makes predictions by calculating the weighted average of input features to arrive at an output.
The outcome is linear: It assumes a straight-line relationship between variables.
Optimization in linear regression aims to determine the best weights for the model. An optimization algorithm minimizes a loss function, which measures the gap between the predicted and actual values in the training data. In doing so, the algorithm improves the accuracy of the model’s predictions. The better the model makes these predictions on the training data, the more accurate it will be at predicting values for new data.
Understanding Optimization Algorithms
In machine learning, optimization refers to finding a model's best parameters. This process is achieved through various optimization algorithms that update model parameters during training.
Algorithms differ by how they search for the best parameters and can be broadly categorized into two groups:
- Deterministic: Deterministic algorithms, like gradient descent, use the entire dataset to calculate the loss function and derive the optimal weights.
- Stochastic: Unlike genetic algorithms, stochastic algorithms use a random dataset sample to make calculations. They are more exploratory and can help avoid local minima that deterministic methods may reach.
Why Optimization Matters
Optimization is integral to machine learning. Model training relies on improving accuracy and reducing errors, which is an optimization problem. For example, a data scientist provides labeled training data when training a model.
The model makes predictions about the data, improving its accuracy through optimization with each iteration. Accurate predictions about the training data will help the model perform better on new data.
Optimization and Hyperparameters
When we talk about hyperparameter optimization in machine learning, we refer to the process of tuning a model's configurations to improve performance. Hyperparameters are distinct from model parameters. They are set before the training process and control how a model learns.
Unlike parameters, which are automatically optimized, data scientists must tune hyperparameters manually. The learning rate, number of hidden layers, and the number of clusters in a classification task are all examples of hyperparameters.
Why Hyperparameter Optimization is Important
Hyperparameter optimization is essential for creating accurate machine learning models. The process can be difficult. Selecting the wrong hyperparameters can lead to inaccurate models that either underfit or overfit training data. Underfitting occurs when a model is improperly trained and cannot accurately predict the training set or new data.
Overfitting happens when a model learns the training data too well, capturing noise, outliers, and underlying patterns. Such a model will perform well on the training data but will be inaccurate when predicting new data. Hyperparameter optimization aims to improve a model’s performance on training and unseen datasets.
Related Reading
An Overview of Machine Learning Optimization Techniques

Parameters and hyperparameters are vital components of machine learning models. Parameters are the variables the model uses to make its predictions. Hyperparameters, on the other hand, are the settings for the model that must be configured before training. To understand the difference between these two notions, let’s break them down further. The model “learns” the parameters during training. You can think of them as the internal variables of the model that change based on the input data. For example, in a neural network, these include the weights and biases of the various nodes.
Optimizing Hyperparameters for Better Model Accuracy
Hyperparameters are “not learned” by the machine but are instead set before training begins. They help to configure the model and determine its structure. For instance, they include the number of clusters in a clustering model, the learning rate, and the number of layers in a neural network. Tuning hyperparameters is crucial for improving model accuracy and performance. Since they influence how the model learns the parameters, optimizing their values can significantly reduce error and enhance the machine learning model's predictive capabilities.
Understanding Hyperparameter Tuning
As we said, the hyperparameters are set before training. But you can’t know in advance, for instance, which learning rate (large or small) is best in this or that case. To improve the model’s performance, hyperparameters have to be optimized. After each iteration, you compare the output with expected results, assess the accuracy, and adjust the hyperparameters if necessary. This is a repeated process. You can do that manually or use one of the many optimization techniques that come in handy when working with large amounts of data.
Comparing Optimization Techniques in Machine Learning
Now, let us talk about the techniques you can use to optimize the hyperparameters of your model.
Exhaustive Search
An exhaustive or brute-force search looks for the most optimal hyperparameters by checking whether each candidate is a good match. You perform the same thing when you forget the code for your bike’s lock and try all the possible options. We do the same thing in machine learning, but the number of options is quite large. The exhaustive search method is simple. For example, if you work with a k-means algorithm, you will manually search for the correct number of clusters. If there are hundreds and thousands of options that I have to consider, it becomes unbearably heavy and slow. This makes brute-force search inefficient in most real-life cases.
Gradient-Based Optimization Techniques
Gradient descent is the most common algorithm for optimizing models to minimize errors. To perform gradient descent, you iterate over the training dataset while re-adjusting the model.
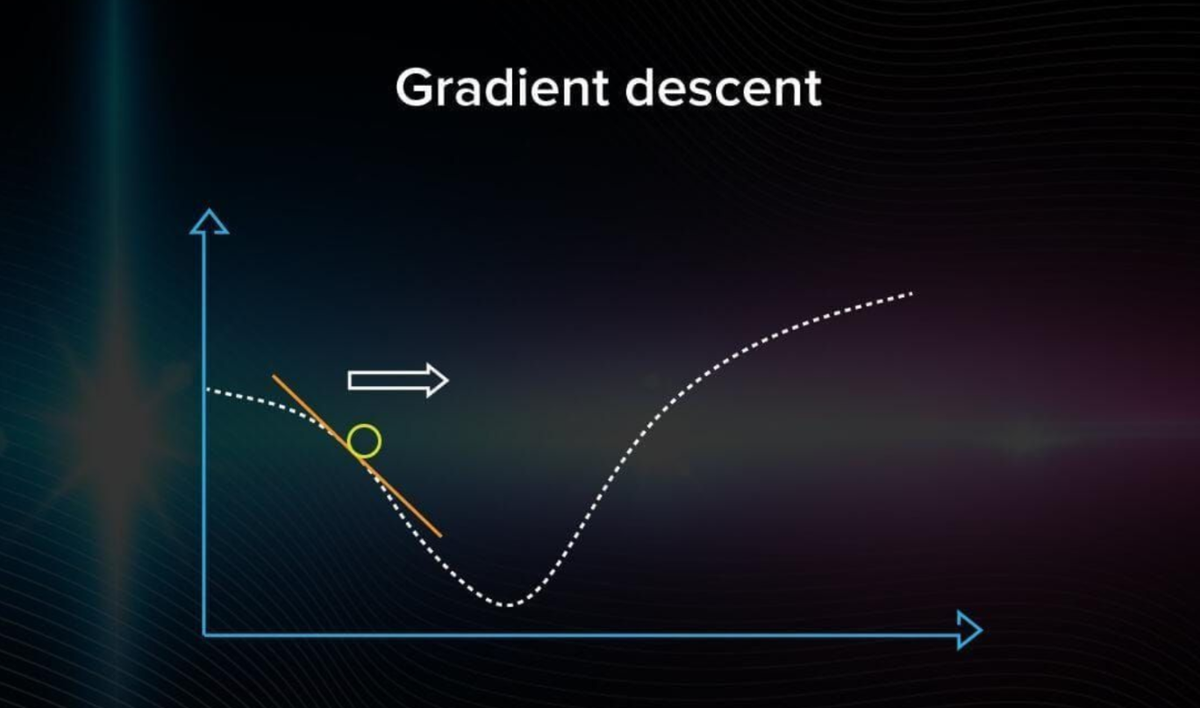
You aim to minimize the cost function because doing so ensures the fewest possible errors and improves the model's accuracy.
The graph shows a graphical representation of how the gradient descent algorithm travels in the variable space. You must take a random point on the graph and arbitrarily choose a direction. If you see that the error is getting larger, that means you chose the wrong direction.
The Impact of Learning Rate on Gradient Descent
When you can no longer improve (decrease the error), the optimization is over, and you have found a local minimum.
Note: In gradient descent, you proceed with steps of the same size. If you choose a learning rate that is too large, the algorithm will jump around without getting closer to the right answer. If it’s too small, the computation will start mimicking an exhaustive search, which is inefficient.
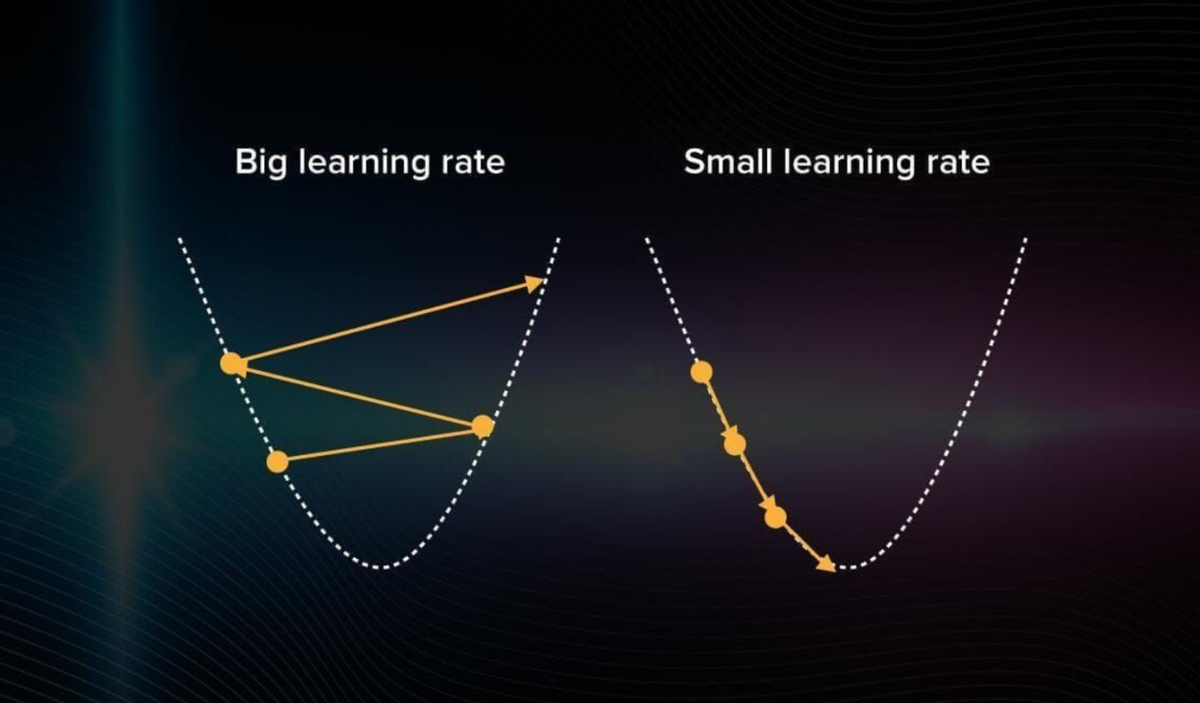
You have to choose the learning rate very carefully. If done right, gradient descent becomes a computation-efficient and quick method of optimizing models.
Stochastic Gradient Descent with Momentum
Stochastic Gradient Descent (SGD) is an optimization algorithm used in machine learning and deep learning for training models. It is an extension of the standard gradient descent algorithm, where instead of computing the gradient of the entire dataset, SGD computes the gradient and updates the model parameters for each training example individually or in small batches. Why use SGD:
- Computational Efficiency: Computing the gradient using the entire dataset can be computationally expensive, especially for large datasets. SGD allows for more frequent updates with lower computational cost.
- Faster Convergence: Since updates are made more frequently, SGD converges faster than traditional gradient descent, especially when dealing with non-convex loss functions.
- Memory Efficiency: Working with individual or mini-batches of data requires less memory than the entire dataset, making SGD suitable for cases where memory is a constraint.
- Escape Local Minima: SGD's stochastic nature introduces randomness into the optimization process, helping the algorithm escape local minima and explore the parameter space more effectively.
It’s an extension of gradient descent where the parameters are updated using a single randomly chosen data point at a time, making it computationally less expensive. The disadvantage of this method is that it requires a lot of updates, and the steps of gradient descent are noisy. Because of this, the gradient can go in the wrong direction and become very computationally expensive. That is why other optimization algorithms are often used.
RMSProp
RMSprop is an optimization algorithm designed to address some of the limitations of traditional gradient descent, especially when dealing with non-convex and poorly conditioned optimization problems. It is beneficial for problems with sparse data and helps to adjust the learning rates for different parameters adaptively. How RMSprop Works:
RMSprop adapts the learning rates of each parameter individually by dividing the learning rate by the root mean square of recent gradients. This allows the algorithm to automatically decrease the learning rate for parameters with steep and rapidly changing gradients and increase the learning rate for parameters with small or slowly changing gradients.
Adam Optimizer
Adam is an optimization algorithm used for training machine learning models. It combines ideas from momentum optimization and RMSprop (Root Mean Square Propagation). Adam adapts the learning rates for each parameter individually based on their historical gradients. Why Adam?
- Adaptive Learning Rates: One of Adam's key advantages is its adaptive learning rate mechanism. It adjusts the learning rates for each parameter based on the historical gradients, allowing it to perform well across different parameters and features.
- Efficiency in Sparse Gradients: Adam is well-suited for sparse gradients, which are common in tasks like natural language processing. It maintains a separate adaptive learning rate for each parameter, making it less sensitive to the scale of the gradients.
- Combining Momentum and RMSprop: Adam combines the momentum term to accelerate convergence in the parameter space with the RMSprop term to scale the learning rates adaptively. This combination helps handle noisy gradients and navigate through saddle points efficiently.
- Effective in a Wide Range of Applications: Adam has shown effectiveness in a wide range of deep learning applications and is widely used in practice due to its robust performance and ease of use.
Gradient-Free Optimization Techniques
Genetic algorithms represent another approach to ML optimization. The logic behind these algorithms attempts to apply the theory of evolution to machine learning. In the theory of evolution, only those specimens get to survive and reproduce that have the best adaptation mechanisms. How do you know what specimens are and aren’t the best in the case of machine learning models?
Understanding Genetic Algorithms in Model Selection
Imagine you have a bunch of random algorithms at hand. This will be your population. Among multiple models with some predefined hyperparameters, some are better adjusted than the others. Let’s find them!
- You calculate the accuracy of each model.
- You keep only those that worked out best.
- Now, you can generate some descendants with hyperparameters similar to the best models to get a second generation of models.
You can see the logic behind this algorithm in this picture:
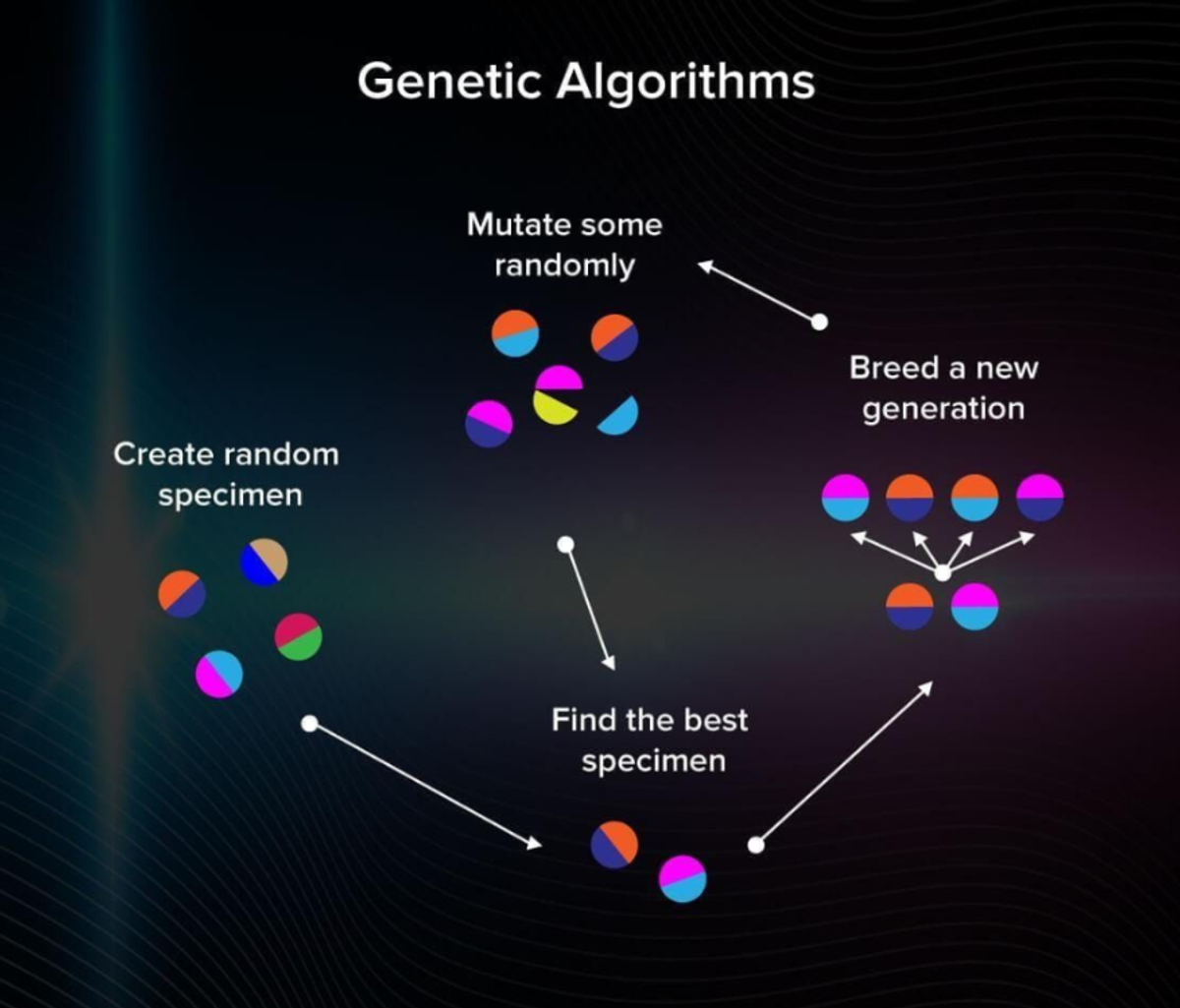
We repeat this process many times, and only the best models will survive. Genetic algorithms help to avoid being stuck at local minima/maxima. They are common in optimizing neural network models.
Exhaustive Search
Pros
- All possible options are evaluated.
- The most intuitive one.
Cons
- When there are many solutions, it becomes extremely slow.
Where to Use
- The database is small.
- High accuracy is more important than the cost and speed of computation.
Gradient
Pros
- Computationally efficient.
- Stable.
- Easy and quick to use.
Cons
- Doesn't work if there are multiple local minima.
- You risk skipping the right solution if the learning rate is too large.
Where to Use
- Need to optimize the model fast.
- You can’t calculate the parameters linearly and have to search for them.
Genetic
Pros
- Can find good solutions in a short computation time.
- Wide range of solutions (since it’s random).
Cons
- Can’t guarantee that the solution is optimal.
- Hard to come up with good heuristics.
Where to Use
- Need to avoid getting stuck in local minima.
Random Searches and Grid Searches
Random and grid searches are the most straightforward approaches to hyperparameter machine learning optimization. A different point in a grid represents each hyperparameter configuration. Optimization involves searching these dimensions to identify the most effective hyperparameter configurations.
The process and utility of random searches and grid searches differ. Random searches are used to discover new and effective combinations of hyperparameters, as the sample is randomised. Grid searches are used to assess known hyperparameter values and combinations, as each point in the grid is searched and evaluated.
Balancing Exploration and Evaluation in Model Optimization
Random searches randomly sample different points or hyperparameter configurations in the grid. This helps to identify new combinations of hyperparameter values for the most effective model. The developer will set the number of iterations to be searched to limit the number of hyperparameter combinations. Otherwise, the process can take a long time without being limited. Grid searches as an approach often used to evaluate known hyperparameter values. Different hyperparameter values are plotted as dimensions on a grid. Whereas random searches are usually used to discover new configuration optimizations, grid searches assess the effectiveness of known hyperparameter combinations.
Evolutionary Optimization
Evolutionary optimization algorithms optimize models by mimicking the selection process within the natural world, such as the process of natural selection or genetics. Each iteration of a hyperparameter value is assessed and combined with other high-scoring hyperparameter values to form the next iteration. Hyperparameter values will be altered each interaction as a ‘mutation’ before recombining the most effective choices. Each iteration improves and becomes more effective through each ‘generation’, as it is optimized. Other approaches within evolutionary optimization include genetic algorithms. In this process, different hyperparameters are paired up after being scored as the most valuable or practical. The process continues using the resulting configuration within the next generation of tests and evaluations. Evolutionary optimization techniques are often used to train neural networks or artificial intelligence models.
Bayesian Optimization
Bayesian optimization is an iterative approach to machine learning optimization. Instead of mapping all known hyperparameter configurations on a grid as in random searches and grid searches approach, Bayesian optimization is more focused. Analysis of hyperparameter combinations happens in sequence, with previous results informing the refinements in the next experiment.
As the model concentrates on the most valuable areas of hyperparameters, the focus on the model improves with each step. Each iteration focuses on selecting hyperparameters in light of the target functions, so the model understands which areas of the distribution will bring the most benefit. This focuses resources and time on optimizing hyperparameters to meet specific functions.
Related Reading
Start Building with $10 in Free API Credits Today!
Inference delivers OpenAI-compatible serverless inference APIs for top open-source LLM models, offering developers the highest performance at the lowest cost in the market. Beyond standard inference, Inference provides specialized batch processing for large-scale async AI workloads and document extraction capabilities designed explicitly for RAG applications.
Start building with $10 in free API credits and experience state-of-the-art language models that balance cost-efficiency with high performance.
Related Reading
- Latency vs. Response Time
- Artificial Intelligence Optimization
Meet with our research team
Schedule a call with our research team to learn more about how Specialized Language Models can cut costs and improve performance.