'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Mar 29, 2025
Is Gemma LLM Worth Your Time? Here’s a Close Look at What It Can Do
Inference Research
Large language models can be overwhelmingly complex. You can fine-tune or deploy a lightweight model to boost performance in a real-world application. But how do you choose the right one? With so many options available, picking the model that will work best for your project is no easy feat. In this article, we’ll explore the features, inference engine, and benefits of Gemma LLM to help you quickly determine whether this specific model is the right choice to meet your objectives.
AI inference APIs can help you get up and running with Gemma LLM. These tools simplify the process of evaluating a model's performance, allowing you to optimize your project and gain a competitive edge quickly.
What is Gemma LLM and Its Key Capabilities

Gemma is Google’s open, lightweight language model designed for efficient deployment and fine-tuning across a range of devices. A family of open language models based on Google’s Gemini models, Gemma is trained on up to 6 trillion tokens of text. These models are considered the lighter versions of Gemini. The Gemma family consists of two sizes:
- 7 billion parameter model for efficient deployment on GPU and TPU
- A 2 billion-parameter model for CPU and on-device applications.
Hardware Accessibility and Consistent Context Window
All the variants can run on various consumer hardware, even without quantization, and have a context length of 8,192 tokens. Here’s a breakdown of the variants:
- Gemma-7 b: Base 7B model.
- Gemma-7 b-it: Instruction fine-tuned version of the base 7B model.
- Gemma-2 b: Base 2B model.
- Gemma-2 b-it: Instruction fine-tuned version of the base 2B model.
Post-Release Enhancements to Gemma's Instruction Models
A month after the original release, Google released a new version of the instruction models. This version features:
- Enhanced coding capabilities
- Factual accuracy
- Instruction following
- Multi-turn quality
The model is also less prone to begin with "Sure."
- gemma-1.1-7b-it
- gemma-1.1-2b-it
Gemma's Broad Competence in Text Understanding
Gemma exhibits strong generalist capabilities in text domains and state-of-the-art understanding and reasoning skills at scale. It achieves better performance than other open models of similar or larger scale across various domains, including:
- Question answering
- Commonsense reasoning
- Mathematics
- Science
- Coding
For both models, the pre-trained, fine-tuned checkpoints and open-source codebase for inference and serving are released by the Google Team.
The Technical Specifications of Gemma LLM
Gemma builds upon recent advancements in sequence models, transformers, deep learning, and large-scale training in a distributed manner. It continues Google’s history of releasing open models and ecosystems, following:
- Word2Vec
- Transformer
- BERT
- T5
- T5X
The responsible release of Gemma aims to:
- Improve the safety of frontier models
- Provide equitable access to this technology
- Pave the way to rigorous evaluation and analysis of current techniques
- Foster the development of future innovations
Prioritizing Safety in Gemma's Deployment
Nevertheless, thorough safety testing specific to each use case is crucial before deploying or using Gemma. Gemma follows the architecture of a decoder-only transformer, which was introduced in 2017. Both the Gamma 2B and the 7B models have a vocabulary size of 256k. Both models even have a context length of 8192 tokens.
Advanced Architectural Features in Gemma
The Gemma even includes the recent advancements made in the transformers’ architecture, including:
- Multi-Query Attention: The 7B model uses multi-head attention, while the 2B model implements multi-query attention (with num_kv_heads=1). This choice is based on performance improvements demonstrated at each scale through ablation studies.
- RoPE Embeddings: Instead of absolute positional embeddings, both models employ rotary positional embeddings in each layer. Additionally, embedding sharing across inputs and outputs minimizes model size.
- GeGLU Activations: The regular ReLU activation function is replaced by the GeGLU activation function, giving good performance.
- Normalizer Location: Gemma deviates from the GOTO practice by normalizing both the input and output of each transformer sub-layer, using RMS norm as the normalization method.
How Well Do the Gemma Models Perform?
Here’s an overview of the base models and their performance compared to other open models on the LLM Leaderboard (higher scores are better):
LLama 2 70B Chat (reference)
- License: Llama 2 license
- Commercial use?: ✅
- Pretraining size [tokens]: 2T
- Leaderboard score ⬇️: 67.87
Gemma-7B
- License: Gemma license
- Commercial use?: ✅
- Pretraining size [tokens]: 6T
- Leaderboard score ⬇️: 63.75
DeciLM-7B
- License: Apache 2.0
- Commercial use?: ✅
- Pretraining size [tokens]: unknown
- Leaderboard score ⬇️: 61.55
PHI-2 (2.7B)
- License: MIT
- Commercial use?: ✅
- Pretraining size [tokens]: 1.4T
- Leaderboard score ⬇️: 61.33
Mistral-7B-v0.1
- License: Apache 2.0
- Commercial use?: ✅
- Pretraining size [tokens]: unknown
- Leaderboard score ⬇️: 60.97
Llama 2 7B
- License: Llama 2 license
- Commercial use?: ✅
- Pretraining size [tokens]: 2T
- Leaderboard score ⬇️: 54.32
Gemma 2B
- License: Gemma license
- Commercial use?: ✅
- Pretraining size [tokens]: 2T
- Leaderboard score ⬇️: 46.51
Gemma 7B is a strong model, with performance comparable to the best models in the 7B weight, including Mistral 7B. Gemma 2B is an interesting model for its size, but it doesn’t score as high in the leaderboard as the best capable models with a similar size, such as Phi 2. Feedback from the community about real-world usage will be valuable.
Related Reading
How Was Gemma Trained, and What Are Its Benchmarks and Performance Metrics

Gemma’s pretraining relied on high-quality data curation and preprocessing methods. The team prioritized diverse datasets that were filtered for safety and helpfulness. The pretraining data consisted of 2T and 6T tokens, respectively, for the 2B and 7B models, primarily sourced from mathematics, code, and Web Docs.
Rigorous Data Curation for Safety and Quality
The training data underwent a thorough filtering process to remove unwanted or unsafe content, including sensitive data and personal information. The filtering pipeline employed heuristic methods along with model-based classifiers to ensure the quality and safety of Gemma’s dataset.
The Compute Infrastructure, Model Sizes, and Training Methodology
Gemma's two model sizes include 2B and 7B parameters, which were trained on 2 trillion and 6 trillion tokens of data, respectively. The models underwent supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) to further improve performance. SFT involved a mix of human-generated, English-only synthetic, and text-only prompt-response pairs.
Strategic Data Mixtures and Synthetic Data Filtering in Training
The training pipeline included comprehensive evaluations to select data mixtures that targeted specific capabilities, such as:
- Instruction-following
- Factuality
- Creativity
- Safety
Even synthetic data underwent filtering to remove toxic outputs or examples with personal information. RLHF utilized human preferences to train a reward function optimized to enhance model performance and mitigate potential issues, such as reward hacking.
Key Benchmarks and Performance Metrics for Gemma
Gemma outperforms Mistral on five out of six benchmarks, with the sole exception being HellaSwag, where they achieve similar accuracy. This dominance is evident in tasks like ARC-c and TruthfulQA, where Gemma surpasses Mistral by nearly 2% and 2.5% in accuracy and F1 score, respectively.
Evidence from MMLU Perplexity
Even on MMLU, where perplexity scores are lower is better, Gemma achieves a significantly lower perplexity, indicating a better grip of language patterns. These results solidify Gemma’s position as a powerful language model, capable of handling complex NLP tasks with high accuracy and efficiency.
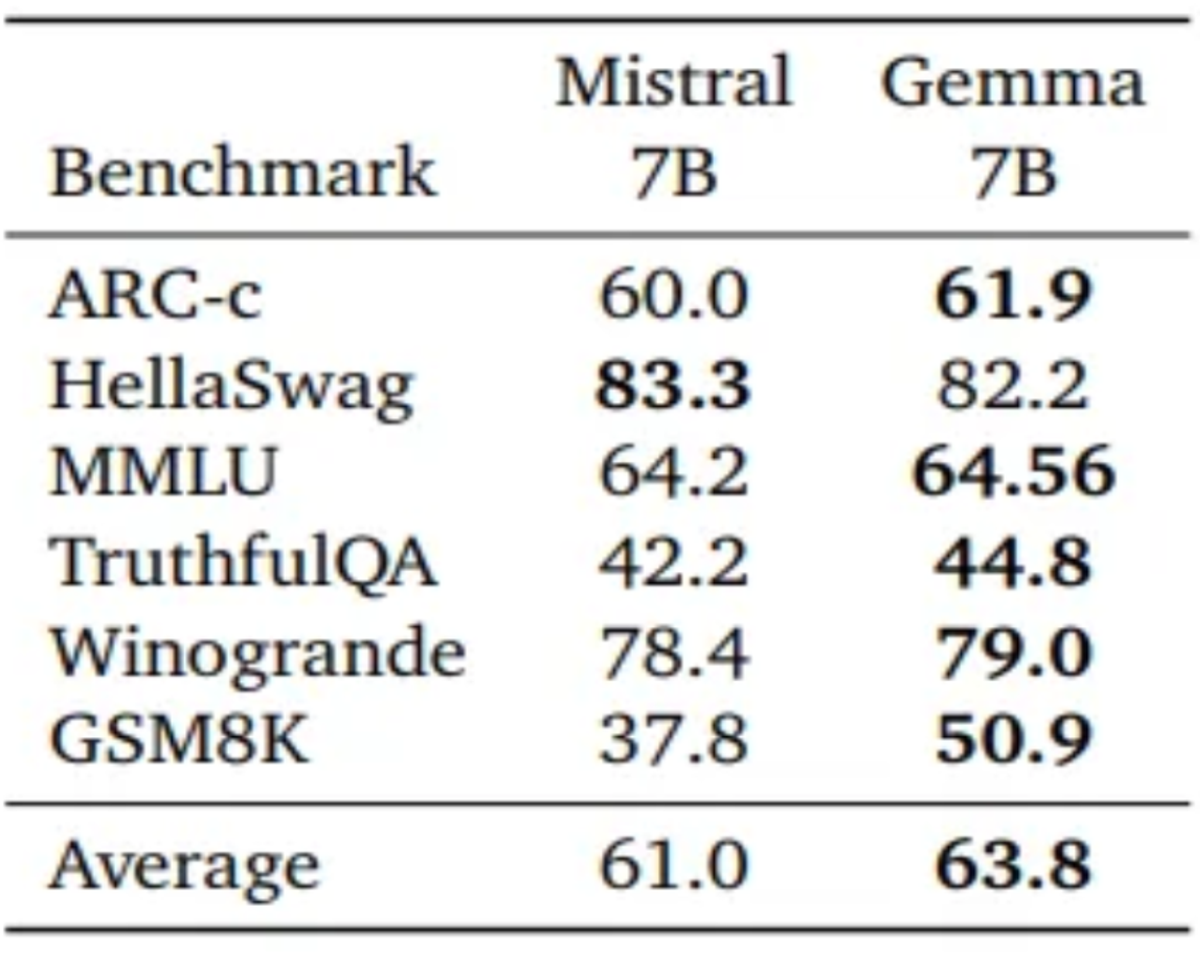
How Does Gemma Compare to Other LLMs?
Looking at the results, Gemma outperforms Mistral on five of six benchmarks, with the sole exception being HellaSwag, where they get similar accuracy. This dominance is evident in tasks like ARC-c and TruthfulQA, where Gemma surpasses Mistral by nearly 2% and 2.5% in accuracy and F1 score, respectively.
Gemma's Superior Language Understanding
Even on MMLU, where perplexity scores are lower, Gemma achieves a significantly lower perplexity, indicating a better grip of language patterns. These results solidify Gemma’s position as a powerful language model, capable of handling complex NLP tasks with good accuracy and efficiency.
Exploring the Variants of Gemma LLM
Google’s Gemma open-source LLM family offers a range of versatile models catering to diverse needs. Let’s look at the different sizes and versions, exploring strengths, use cases, and technical details for developers:
Size Matters: Choosing Your Gemma
- 2B: This lightweight champion excels in resource-constrained environments like CPUs and mobile devices. Its memory footprint of around 1.5GB and fast inference speed make it ideal for tasks like text classification and simple question answering.
- 7B: Striking a balance between power and efficiency, the 7B variant shines on consumer-grade GPUs and TPUs. Its 5GB memory requirement unlocks more complex tasks, such as:
- Summarization
- Code generation
Tuning the Engine: Base vs. Instruction-tuned
- Base: Fresh out of the training process, these models offer a general-purpose foundation for various applications. They require fine-tuning for specific tasks but provide flexibility for customization.
- Instruction-tuned: Pre-trained on specific instructions, such as “summarize” or “translate,” these variants offer out-of-the-box usability for targeted tasks. They sacrifice some generalizability for improved performance in their designated domain.
Technical Tidbits for Developers
- Memory Footprint: 2B models require around 1.5GB of memory, while 7B models demand approximately 5GB. Fine-tuning can slightly increase this footprint.
- Inference Speed: 2B models excel in speed, making them suitable for real-time applications. 7B models offer faster inference compared to larger LLMs but may not match the speed of their smaller siblings.
- Framework Compatibility: Both sizes are compatible with major frameworks like TensorFlow, PyTorch, and JAX, allowing developers to leverage their preferred environment.
Matching the Right Gemma to Your Needs
The choice between size and tuning depends on your specific requirements. The 2B base model is an excellent starting point for resource-constrained scenarios and straightforward tasks. If you prioritize performance and complexity in particular domains, the 7B instruction-tuned variant could be your champion.
Fine-tuning either size allows for further customization to suit your unique use case. This is just a glimpse into the Gemma variants. With its diverse options and open-source nature, Gemma empowers developers to explore and unleash its potential for various applications.
Getting Started with Gemma
We will get started with Gemma. We will be working with Google Colab because it comes with a free GPU. Before we get started, we need to accept Google’s Terms and Conditions to download the model.
Step 1: Opening Gemma
Click on this [link](https://huggingface.co/google/gemma-7b) to go to Gemma on HuggingFace. You will be presented with something like the following:
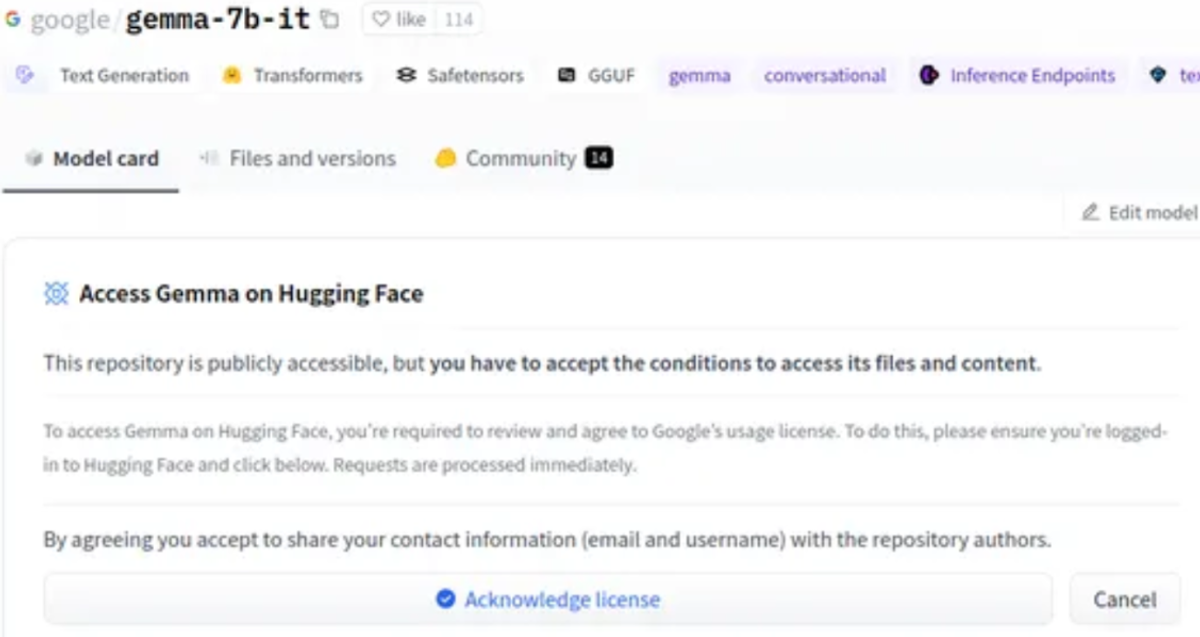
Step 2: Click on Acknowledge License
If you click on "Acknowledge License," you will see a page as shown below.
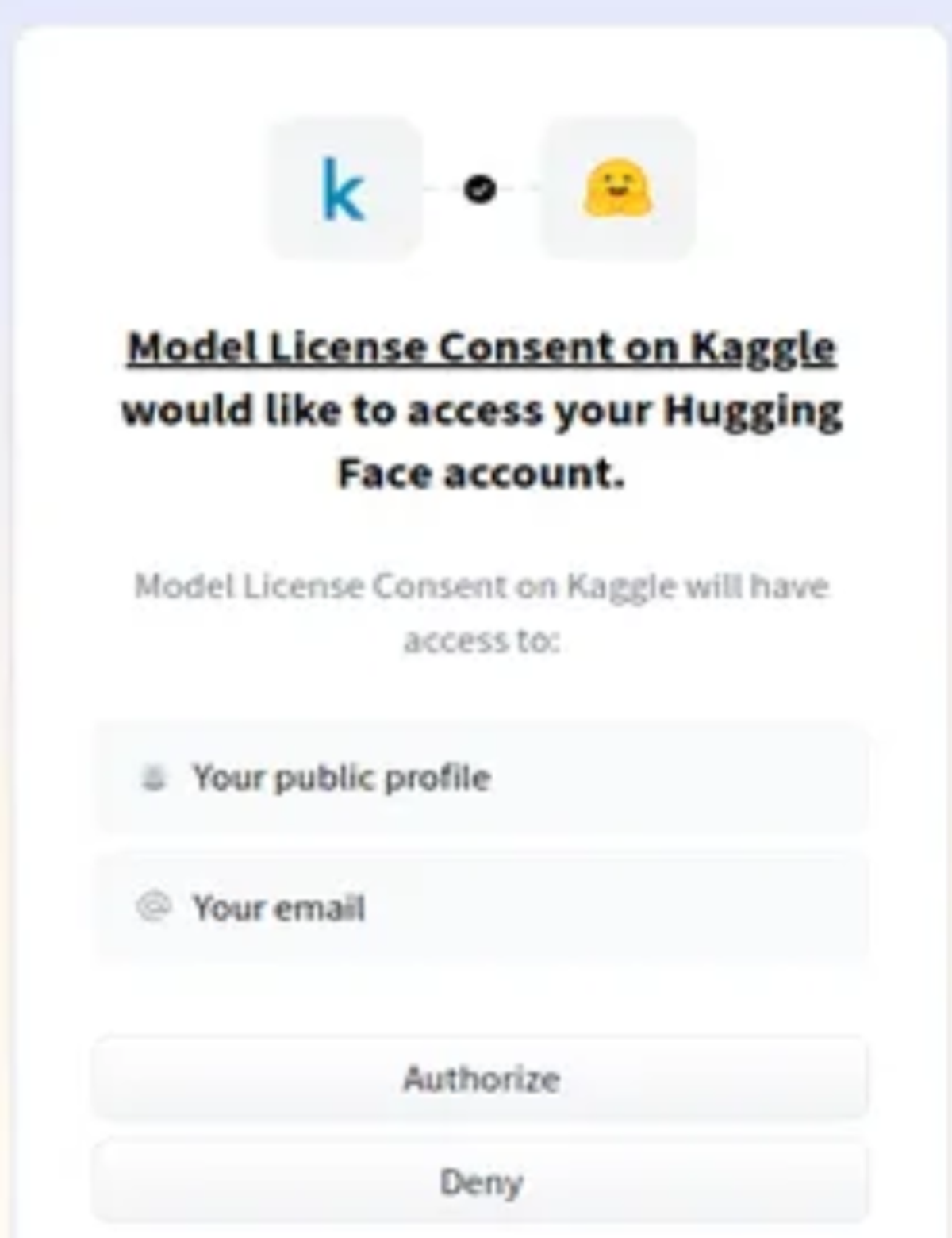
Click on Authorize. Done, we are now ready to download the model. Before, let’s generate a new HuggingFace Token. For this, you can go to the HuggingFace Settings and generate a new Token. This token will be helpful because we need it to authorize inside Google Colab to download the Google Gemma Large Language Model.
Step 3: Installing Libraries
To get started, we first need to install the following libraries.
```python
!pip install -U accelerate bitsandbytes transformers huggingface_hub
```Accelerate
Allows distributed training and mixed-precision training for faster and more efficient model training. The accelerate library even helps with faster inference of the Large Language Models.
Bitsandbytes
Allows quantization of model weights to 4-bit or 8-bit precision, reducing memory footprint and computation requirements. Because we are dealing with a 7 billion-parameter model, which requires around 30-40 GB of GPU VRAM, we need to quantize it to fit within the Colab GPU's memory.
Transformers
Provide pre-trained language models, tokenizers, and training tools for natural language processing tasks. We work with this library to download the Gemma model and start inferring it.
Huggingface_hub
Facilitates access to the Hugging Face Hub, a platform for sharing and seeing language models and datasets. We need this library to log in to Hugging Face so that we can verify that we are authorized to download the Google Gemma Large Language Model. The -U option after the install indicates that we are fetching the latest updated versions of all the libraries.
Step 4: Typing Important Command
Now, type the following command:
```python
!huggingface-cli login
```Hugging Face Token and Setup
The above command will ask you to provide the HuggingFace Token, which we can get from the HuggingFace website. Give this token and press the Enter button, and you will receive a Login Successful message. Now let’s move on to coding.
- Import necessary classes for model loading and quantization, from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig.
- Configure model quantization to 4-bit for memory and computation efficiency quantization_config = BitsAndBytesConfig(load_in_4bit=True).
- Load the tokenizer for the Gemma 7B Italian model. tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it").
- Load the Gemma 7B Italian model itself, with 4-bit quantization. model = AutoModelForCausalLM.from_pretrained("google/gemma-7b-it", quantization_config=quantization_config).
AutoTokenizer
This class dynamically loads the pre-trained tokenizer associated with the given model, ensuring compatibility and eliminating the need for manual configuration.
AutoModelForCausalLM
Similar to the tokenizer, this class automatically loads the pre-trained Causal Language Model architecture based on the provided model identifier.
quantization_config = BitsAndBytesConfig (load_in_4bit=True)
This line creates a config object for quantization, telling that the model’s weights should be pushed in 4-bit precision instead of the original 32-bit. This, to a great extent, reduces memory consumption and potentially speeds up computations, making the model more efficient for resource-constrained environments.
Tokenizer = AutoTokenizer.from_pretrained(“google/gemma-7b-it”)
This line loads the pre-trained tokenizer specifically designed for the “google/gemma-7b-it” model. This tokenizer knows how to break down text into separate Tokens that the model can understand and process.
model = AutoModelForCausalLM.from_pretrained(“google/gemma-7b-it”, quantization_config=quantization_config)
This line loads the actual “google/gemma-7b-it” model, but with the crucial addition of the quantization_config object. This ensures that the model weights are created in the 4-bit format that we have discussed earlier, adding the benefits of quantization. Our Gemma Large Language Model is downloaded, converted into a 4-bit quantized model, and loaded into the GPU.
Step 5: Inferencing the model
Now let’s try inferring the model.
```python
Define input text
input_text = "List the key points about Responsible AI"
Tokenize the input text
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
Generate text using the model
outputs = model.generate(
**input_ids, # Pass tokenized input as keyword argument
max_length=512, # Limit output length to 512 tokens
)
Decode the generated text
print(tokenizer.decode(outputs[0]))
```
Define Input Text
The code starts by assigning the Prompt “List the key aspects of Responsible AI” to the input_text variable.
Tokenize Input
The tokenizer object associated with the downloaded model is used to convert the text into numerical tokens that the model can understand.
The return_tensors=”pt” line tells about the conversion to a PyTorch tensor for efficient GPU processing. The resulting tensor of token IDs is then moved to the GPU using to (“cuda”) if available.
Generate Text
The model.generate function is called with the tokenized input (input_ids) and a maximum output length of 512 tokens. This instructs the model to generate text based on the provided Prompt, respecting the given length limit.
Decode and Convert
The generated text, represented as a sequence of token IDs, is decoded back into human-readable text using the tokenizer.decode function. Finally, the decoded text is printed out.
Step 6: Response Generation
Running the code has generated the following response

The model has generated a satisfactory response to the provided query. It has highlighted all the key aspects that go into creating a Responsible AI. This is a relevant and accurate answer to the question asked. Let’s let the AI ask a common-sense question.
```python
input_text = "How many eggs can a Whale lay in its lifetime?"
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids,max_length=512)
print(tokenizer.decode(outputs[0]))
```
```python
input_text = "How many smartphones can a human eat ?"
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids,max_length=512)
print(tokenizer.decode(outputs[0]))
```
So far, so good. The model possesses good common-sense abilities. It's able to identify what’s wrong in the sentence and output the same, as shown in the pictures above. Let’s try asking some math questions.
```python
input_text = "I have 3 apples and 2 oranges. I ate 2 organes. How many apples do I have?"
input_ids = tokenizer(input_text, return_tensors="pt").to('cuda')
outputs = model.generate(**input_ids,max_new_tokens=512)
print(tokenizer.decode(outputs[0]))
```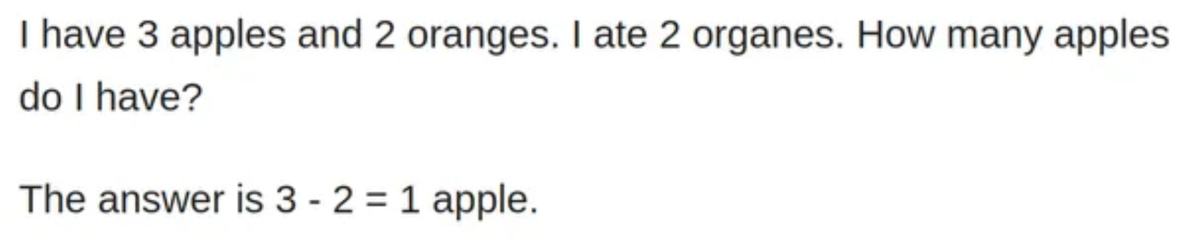
The model struggled to answer this simple, tricky math question. Let’s try do some Prompt Engineering here. Let’s add additional info in the Prompt and run it like below:
```python
input_text = "I have 3 apples and 2 oranges. \ I ate 2 oranges. How many apples do I have? \ Think Step by Step. For each step, re-evaluate your answer."
input_ids = tokenizer(input_text, return_tensors="pt").to('cuda')
outputs = model.generate(**input_ids,max_new_tokens=512) print(tokenizer.decode(outputs[0]))
```Wow, a simple tweak in the Prompt and the model answered correctly. It began thinking incrementally that is step by step. And for each step, it starts re-evaluating its answer, if it’s right or wrong. And finally, it has steered to the correct answer. Let’s try asking the model to write a simple Hello World program in Python.
```python
input_text = "Write a hello world program"
input_ids = tokenizer(input_text, return_tensors="pt").to('cuda')
outputs = model.generate(**input_ids,max_new_tokens=512) print(tokenizer.decode(outputs[0]))
```
Related Reading
Stepwise Guide to Fine-Tune Google’s Gemma LLM

Fine-tuning Gemma on your custom dataset begins with setting up a systematic way to clean and preprocess your data, establishing a training routine, and creating evaluation metrics for quality control. First, install and update all necessary Python packages to avoid errors.
```python
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U peft
%pip install -U accelerate
%pip install -U trl
%pip install -U datasets
```Next, import the packages we will use to load the dataset, model, and tokenizer, and perform supervised fine-tuning (SFT) and inference.
```python
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer
```Define Variables for Fine-Tuning
We need to define names for the base model and dataset, as well as the name of the fine-tuned model, which we will upload to Hugging Face Hub later. These variables will be utilized at various stages, including loading the dataset and model, tokenization, training, and model saving.
```python
base_model = "/kaggle/input/gemma/transformers/7b-it/2"
dataset_name = "hieunguyenminh/roleplay"
new_model = "gemma-7b-it-v2-role-play"
```Load Hugging Face API Key
Next, we will load the Hugging Face API key from Kaggle secrets (environment variables).
```python
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_hf = user_secrets.get_secret("HUGGINGFACE_TOKEN")
```Log in to Hugging Face CLI
Now we can use the API key to log in to Hugging Face CLI. This will allow us to access the model and also save it on Hugging Face Hub.
```python
!huggingface-cli login--token $secret_hf
```Initialize W&B Workspace
We will initiate the weights and biases (W&B) workspace using the W&B API key. We will use this workspace to track model training.
```python
secret_wandb = user_secrets.get_secret("wandb")
Monitoring the LLM
wandb.login(key = secret_wandb)
run = wandb.init(
project='Fine tuning Gemma 7B',
job_type="training",
anonymous="allow"
)
```Load the Dataset
Now we can retrieve the first 1000 rows of data from the role-play dataset available on Hugging Face and display a sample of the `text` column.
```python
Loading the dataset
dataset = load_dataset(dataset_name, split="train[0:1000]")
dataset["text"][100]
```Our dataset comprises a continuous conversation between the user and the assistant, focusing on celebrity style. It is role-playing.
Load the Model and Tokenizer
To avoid memory issues, we will load our model in 4-bit precision using BitsAndBytesConfig. It will load the model directly from Kaggle without requiring a download.
```python
# Load base model(Gemma 7B-it)
bnbConfig = BitsAndBytesConfig(
load_in_4bit = True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnbConfig,
device_map="auto"
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
model.config.pretraining_tp = 1
model.gradient_checkpointing_enable()
```Next, load the tokenizer and configure the pad token to fix the issue with fp16.
```python
Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
tokenizer.padding_side = 'right'
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_eos_token = True
tokenizer.add_bos_token, tokenizer.add_eos_token
```Add the Adapter Layer
By adding the adapter layer to our model, we can fine-tune it more efficiently. Instead of training the entire model, we only need to update the parameters of the adapter layers, which will accelerate the training process. Our target modules will be 'o_proj', 'q_proj', 'up_proj', 'v_proj', 'k_proj', 'down_proj', and 'gate_proj'.
```python
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=['o_proj', 'q_proj', 'up_proj', 'v_proj', 'k_proj', 'down_proj', 'gate_proj']
)
model = get_peft_model(model, peft_config)
```Train the Model
In order to begin training, we need to specify the hyperparameters. These parameters are fundamental and can be modified to enhance the training process and improve the performance of the model. If you want to better grasp each hyperparameter, we suggest reading the Fine-Tuning LLaMA 2 tutorial.
To set up the Supervised Fine-tuning (SFT) trainer, we need to provide it with the model, dataset, Lora configuration, tokenizer, and training parameters as arguments.
```python
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length= 512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)
```
We will now run the training process using the `.train` function. The fine-tuning took almost 1 hour and 1 minute. The training loss gradually decreased, and you can even reduce this loss by increasing the number of epochs.
```python
trainer.train()
```
Finish W&B Session
Now we can finish the W&B session and configure the model for inference. ```python
wandb.finish()
model.config.use_cache = True
```
Save the Model
We will now save the model adapter locally and upload it to the Hugging Face Hub. The `push_to_hub` command will create the repo and push the adapter config and adapter weights to the hub.
```python
Save the fine-tuned model
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)
```
Note: This is just an adapter that we are saving. The complete model is around 18 GB.
Model Inference
In order to generate a response using our fine-tuned model, we need to follow a few steps. First, we will create a prompt in the role-play dataset format. Then, we will pass the prompt to the tokenizer and subsequently to the model to generate predictions. To translate the predicted output into readable text, we will decode it using the tokenizer.
```python
prompt = '''<|system|>Harry Potter is a wizard known for his distinctive lightingshaped scar and his remarkable journey through magic and battles against the dark wizard Voldemort.
<|user|> What is the meaning of hate?
<|assistant|>'''
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_length=500, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text)
```Try It Again
Now let’s try it again with a new character: Michel Jordan.
```python
prompt = '''<|system|>Michael Jordan an NBA legend known for his competitive drive six championship wins with the Chicago Bulls.
<|user|> What motivates you in the life?
<|assistant|>'''
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_length=500, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text)
```
We have done a good job fine-tuning the base model to understand the new style of response generation.
Start Building with $10 in Free API Credits Today!
Inference delivers OpenAI-compatible serverless inference APIs for top open-source LLM models, offering developers the highest performance at the lowest cost in the market. Beyond standard inference, Inference provides specialized batch processing for large-scale async AI workloads and document extraction capabilities designed explicitly for RAG applications.
Start building with $10 in free API credits and experience state-of-the-art language models that balance cost-efficiency with high performance.
Related Reading
Meet with our research team
Schedule a call with our research team to learn more about how Specialized Language Models can cut costs and improve performance.