'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Apr 7, 2025
26 Best Machine Learning Frameworks for Fast, Scalable AI Projects
Inference Research
Training a machine learning model is just the first step. Once it’s ready, you’ll need to deploy it to a production environment where it can make accurate predictions on new data. This process can be smooth or extremely challenging. The difference? The machine learning framework you choose. Popular machine learning frameworks, such as TensorFlow, Keras, and PyTorch, simplify the process of building, testing, and deploying AI models. In this article, we’ll explore the best machine learning frameworks to help you quickly build, test, and scale high-performing AI models.
Inference's AI inference APIs can help you achieve your objectives and ease the transition from development to production.
What are Machine Learning Frameworks?

Scrolling through your social media feed, asking a chatbot a question, or translating a piece of text are all examples of machine learning in action. Machine learning is a type of artificial intelligence that enables a computer to learn autonomously without requiring human intervention or explicit programming.
Machine learning utilizes statistics and algorithms to identify patterns and generate responses or solutions accordingly. These algorithms are incredibly complex, making them challenging to work with unless you have a background in data science.
4 Types of Machine Learning
The following are the four types of machine learning. Explore these in more detail:
1. Supervised Learning
You train the model using a labeled dataset. Because the model learns to recognize patterns in the labeled data, it can then make predictions when provided with new data. Tend to utilize supervised learning for risk assessment, image recognition, and fraud detection.
2. Unsupervised Learning
This type of learning involves searching for patterns in unlabeled data. By identifying similar structures in the data, the model can create clusters of data points, which helps with data visualization, particularly in identifying outliers. It is also used for fraud detection, customer segmentation, and customer recommendations.
3. Semi-supervised Learning
You can use both labeled and unlabeled data to train the model, but you typically include more unlabeled data than labeled data. In terms of social media, TikTok, for example, you can use this type of ML for image and speech recognition, web content, and text document classification.
4. Reinforcement Learning
This approach employs a system of rewards and punishments to train the model. Using this system, the algorithm learns how to achieve the best outcome. It is used in the development of video games and the teaching of robots.
What Are Machine Learning Frameworks and Why Do They Matter?
Machine learning (ML) frameworks provide various interfaces, tools, and libraries that simplify these complex algorithms, making them easier to work with, even without a deep understanding of the technology.
Read on to learn more about machine learning frameworks, including some popular Python machine learning frameworks, and how to build a career that involves working with these frameworks.
What are Machine Learning Frameworks Used For?
Machine learning frameworks utilize various machine learning and deep learning functions, including:
- Time series analysis
- Natural language processing
- Computer vision
They can primarily help users deal with complex, challenging algorithms by making them more accessible and easier to use. Ultimately, by contributing to the machine learning lifecycle, machine learning frameworks streamline processes such as:
- Data visualization
- Model development
- Testing
- Logging
- Data engineering
How Do Machine Learning Frameworks Work?
Machine learning frameworks overlay a user interface with complex machine learning algorithms. For many businesses, including yours, the time, expense, and infrastructure requirements of using machine learning make it impractical for your organization to develop it in-house.
Machine learning frameworks eliminate much of this expense by providing a ready-to-use resource that includes tools, libraries, and interfaces, thereby reducing upfront costs and time requirements.
Choosing the Right ML Framework for Your Business
If you’re a business owner, you can choose a machine learning framework that fits your company’s needs and provides the tools for your developers to interact with the machine and deep learning processes without needing to understand the complex algorithms being employed.
This way, your developers have the opportunity to extract the value from the machine learning algorithms without risking compromising them by interacting with the code directly.
Who Uses Machine Learning Frameworks?
Many industry sectors, including finance, cybersecurity, healthcare, insurance, and retail, employ machine learning frameworks. Utilizing these ML frameworks can provide your business with valuable data generated by machine learning models, supporting informed decision-making.
Developers working within these industries utilize various open-source machine learning frameworks to create customized machine learning processes that meet their employers’ goals and needs.
What Benefits Do ML Frameworks Provide to Developers? Pros and Cons
Two pros of machine learning frameworks include simplifying ML algorithms and scalability, while two cons can be selecting the proper framework for your needs and the source(s) from which your ML algorithm obtains its data.
Simplifying and Scaling ML for Business Insights
More specifically, one benefit of using a machine learning framework is that it simplifies machine learning algorithms, making the technology more accessible to businesses across various industries without requiring professionals trained in deep learning programming languages.
This enables your business to uncover valuable insights and make informed, data-driven decisions that would otherwise be inaccessible. To find these insights, machine learning frameworks can process vast amounts of data, also known as scalability, to identify patterns and reach conclusions.
Choosing the Right ML Framework and Data Wisely
One challenge of machine learning frameworks is that you risk spending money and time purchasing one that doesn’t meet your needs. It’s important to consider what exactly you’re hoping to get out of machine learning and then take the time to research the different types of frameworks to ensure you’re choosing the best one for your business.Knowing where your machine learning algorithms are sourcing their information is also essential. Not all data is usable or accurate, and you’ll need to ensure that the sources are transparent, unbiased, and valuable. Otherwise, you risk extrapolating results that aren’t true, which might lead your business astray with inaccurate conclusions.
Related Reading
Top 26 Machine Learning Frameworks for Rapid Prototyping

1. Inference: Fast and Efficient Serverless Inference for LLMs

Inference.net is a serverless machine learning inference platform purpose-built for developers and AI teams looking to scale high-performance language models without the infrastructure headache.
Fully OpenAI-compatible, it offers blazing-fast inference APIs for top open-source LLMs, making it easy to switch or scale without vendor lock-in. With cost-effective pricing and built-in support for complex workflows, Inference.net is ideal for production-grade AI applications, RAG pipelines, and batch AI workloads.
Features:
- OpenAI-Compatible APIs: Seamlessly plug in top-tier open-source LLMs (like LLaMA, Mistral, and others) without rewriting your code.
- Serverless Inference Infrastructure: Scale effortlessly with auto-scaling, no infrastructure to manage, and predictable, low-latency responses.
- Batch Processing for Async Workloads: Process large-scale jobs, documents, or datasets in parallel, perfect for document QA, RAG, and multi-step pipelines.
- RAG-Optimized Document Tools: Built-in document extraction and chunking tailored for Retrieval-Augmented Generation.
- Startup-Friendly Pricing: Start building with $10 in free credits and unlock pay-as-you-go pricing with no hidden costs.
Use cases:
- Power real-time chatbots or AI assistants with open-source LLMs.
- Automate document processing and extraction for enterprise RAG systems.
- Run batch jobs for summarization, classification, or QA at scale.
- Replace OpenAI with an open, cost-efficient, self-serve alternative.
Drawbacks:
- Focused on Inference: Inference.net is not a full-stack ML framework and doesn’t handle training workflows; it's optimized for deploying and scaling already-trained models.
- Requires Familiarity with APIs: While easy to integrate, developers need a basic understanding of HTTP APIs and token-based authentication to get started.
2. H2O

This is a fully open-source and free machine learning framework designed to streamline the organizational procedures of decision support systems. H2O combines with other frameworks for managing actual model development and training. This framework is primarily used in risk and fraud trend analysis, patient analysis in healthcare, insurance customer analysis, customer intelligence, advertising cost analysis, and return on investment (ROI) analysis.
Features:
- It combines H2O with other frameworks, such as:
- Caffe
- TensorFlow
- This combines H2O with Spark (a big data processing platform).
- It is an enterprise edition that authorizes training and deploying machine learning models, making them accessible via APIs and integrating them with applications.
- It authorizes non-technical personnel to create data, modify parameters, and utilize machine learning to optimize the best algorithm for resolving a specific business problem.
- It utilizes programming languages such as R and Python to construct models in H2O.
Drawbacks:
- This program utilizes the software, but the documentation is insufficient, and it is challenging to locate the available documentation.
- It has no feature engineering. It depends on the data size; H2O.AI requires a significant amount of memory.
- H2O lacks management and has no accountability. It is hectic and chaotic to the point where individuals have no clue what they're doing or what they should be doing.
3. PyTorch
PyTorch is an open-source and free machine learning framework built on Torch and Caffe2, making it an ideal choice for designing neural networks. This also supports the Lua language for user interface development. It is combined with Python and is compatible with famous libraries like Cython and Numba. This framework is intuitive and faster for freshers to learn.
Features:
- It supports eager execution and greater flexibility by utilizing native Python code for model development.
- PyTorch quickly switches from development to graph mode, providing high performance and faster growth in C++ runtime environments.
- It uses asynchronous execution and friend-to-friend communication to enhance performance. It is used in both model training and production habitats.
- PyTorch offers an end-to-end workflow that enables the development of models in Python and their deployment on iOS and Android devices. The extensions of this framework API manage common pre-processing and combined tasks required to implement machine learning models on mobile devices.
Drawbacks:
- It lacks model serving in production. This will likely be replaced in the future, and other frameworks are being widely used for real-world production work.
- PyTorch has limited monitoring and visualization interfaces.
- It is not as extensive as TensorFlow.
4. TensorFlow
This machine learning framework was developed by Google and launched as a web-based project. TensorFlow is a versatile and strong machine learning tool with a complete library. Its libraries have large and flexible functions, permitting the creation of classification models, neural networks, regression models, and other types of machine learning models.
This also enables the personalization of machine learning algorithms to meet one's specific requirements and needs. It operates on both GPUs and CPUs. The main obstacle of TensorFlow is that it's not easy to use for freshers.
Features:
- Clarity in Computational Graph: It makes visualizing any part of the computational procedure of an algorithm easier. Prior frameworks, such as Scikit or NumPy, do not support it.
- Modular: This system is highly modular, allowing its components to be used independently without requiring the entire framework.
- Classified Training: It offers robust support for distributed training on both GPUs and CPUs.
- Aligned Neural Network Training: TensorFlow also offers pipelines and lets you train many neural networks and many GPUs in parallel. This makes huge distributed systems efficient.
Drawbacks:
- It does not have any inbuilt contingencies for iterations ending up in symbolic loops
- This has too frequent updates.
- TensorFlow has Homonym inconsistency, which makes understanding and use difficult, as they have similar names but different implementations.
- It has limited GPU support.
- This is low on implementation speed.
5. Sci-Kit Learn
Scikit-learn started as a Google Summer of Code project in 2007. Later, several other developers worked on the project to produce a more comprehensive framework, which was released to the public in 2010.
Scikit-learn builds on several Python libraries like NumPy, matplotlib, Pandas, and SciPy. The machine learning framework offers a range of classification, regression, and clustering algorithms.
Further, it has a comprehensive toolkit for predicting future events based on analyzed data. Companies like Spotify and J.P. Morgan utilize this framework for various machine learning (ML) applications, including:
- Recommender systems
- Predictive models
- Data clustering software
Features:
- Contains an extensive collection of supervised learning algorithms, including models for linear regression and decision trees.
- Features numerous helper functions, including hyperparameter and data preprocessing tools.
- Dimensionality reduction feature allows you to reduce the number of attributes in a dataset using visualization and summarization methods.
Pros:
- Easy to use.
- Can define and compare machine learning algorithms and processes.
- Has extensive documentation that guides users through how to use the library.
- Versatile and relevant for various processes, like creating neuroimages and predicting customer behavior.
- It has a vast community and numerous authors, resulting in frequent updates.
Cons:
- Simple abstraction may tempt beginners to skip ML foundations.
- Not suitable for string processing.
6. Theano
This is a free project which is a Python library which permits manipulating and evaluating mathematical expressions. These libraries specially manage multidimensional arrays.
Theano was created by the Montreal Institute for Learning Algorithms (MILA) at the University of Montreal and was launched in 2007. It also offers integration facilities with NumPy through numpy.ndarray in functions. This can be compiled to run correctly on CPU or GPU architectures.
Features:
- It has high-performance computation.
- Theano can flawlessly switch between CPU and GPU resources.
- It has automatic differentiation.
- This has a symbolic expression.
- Theano has and can be easily integrated with other libraries.
Drawbacks:
- It can be complicated on AWS.
- Theano can operate on a single GPU.
- It requires ample compile time for large and complex models.
- Theano's error messages are complicated, and as a result, debugging is challenging.
7. Caffe
Convolutional Architecture for Fast Feature Embedding (CAFFE) was created at the Berkeley Vision and Learning Center at the University of California and launched in 2017. This is a deep learning framework written in C++ that has an expression architecture. It easily permits switching between the CPU and GPU.
It has a MATLAB and Python interface and Yahoo has also integrated Apache Spark with this machine learning framework for developing CaffeOnSpark. It is a perfect framework for image classification and segmentation. It supports many GPU- and CPU-based libraries like NVIDIA, cuDNN, Intel MKN and more.
Features:
- It is swift and efficient.
- Caffe's modular design allows for the easy addition of new layers and functionalities.
- It is easy to use and is freely accessible.
- This framework supports GPU training.
- It has an expressive architecture.
- This framework also has a robust community of developers and researchers.
Drawbacks:
- Caffe has limited flexibility compared to other frameworks, such as TensorFlow or PyTorch.
- It has a steeper learning curve.
- This framework has fewer frequent updates; it might lack some of the current features and improvements.
- Caffe faces a lot of challenges in deployment and scalability as its not that vastly used in production environments.
8. Apache Mahout
This is a free machine learning framework primarily focused on linear algebra. This was developed by the Apache Software Foundation and launched in 2009. Apache Mahout permits data scientists to apply their mathematical algorithms in an interactive environment.
The algorithms are for clustering, classification and batch-based collaborative filtering in Apache Mahout, which uses Apache Hadoop. It works and is distributed with interactive shells and a library to link the application.
Features:
- It is freely accessible.
- Has flexibility for different algorithms.
- Apache Mahout can manage huge datasets via distributed computing.
Drawbacks:
- It is a complicated programming model.
- Apache Mahout relies on legacy technologies, such as MapReduce.
- This framework lacks inherent security features, which is an obstacle to adopting modern data lakehouse terrains.
9. Amazon SageMaker
Amazon SageMaker is a completely integrated development environment (IDE) for machine learning. It was launched in 2017. Amazon Web Services offers this Machine Learning service for applications like:
- Computer Vision
- Image
- Recommendations and Video Analysis
- Forecasting
- Text analytics and more
One can choose this Machine Learning framework for building, training and deploying machine learning models on the cloud.
Features:
- It has smooth workflows and automated tasks
- Amazon Sagemaker is flexible
- This framework has been integrated with other AWS services, making it easier to build, deploy, and train models
Drawbacks:
- It is expensive and can be complicated to estimate and control costs
- There can be a learning curve for freshers in knowing about the multiple features and services given by SageMaker
- It depends on the internet connection to gain accessibility to the AWS cloud
10. Accord.NET

This machine learning framework is entirely written in C#. Accord.NET was made by Cesar Roberto de Souza and launched in 2010. It offers coverage on many topics like statistics, machine learning, artificial neural networks with many machine learning algorithms.
Algorithms like classification, regression, clustering and more, also with audio and image processing libraries. These libraries are available as source code, executable installers and NuGet packages.
Features:
- It has complete algorithms for classification.
- Regression and clustering.
- It also integrates with other .NET libraries and tools.
- Accord.NET mainly focuses on scientific computing in .NET.
Drawbacks:
- It has limited scalability for massive datasets
- This framework has expensive computational costs
- It has a steeper learning curve compared to other, more straightforward frameworks
11. Microsoft Cognitive Toolkit
It is a machine learning or deep learning framework created by Microsoft Research and initially launched in 2016. One can easily develop famous deep learning models like feed-forward DNNs, convolutional neural networks and recurrent neural networks through Microsoft cognitive Toolkit.
It utilizes multiple GPUs and servers, enabling parallelization throughout the backend. This can be used with metrics, algorithms and networks. This can be used as a library in Python, C++ or C# programs or BrainScript, which is its model description language.
Feature:
- It is easy to use and is easily accessible.
- Microsoft Cognitive Toolkit is flexible and scalable.
- It is well-suited for multiple AI projects, from examination to production.
- This framework has robust community support.
- It supports many languages, like Python and C++.
Drawbacks:
- It can be less intuitive for freshers.
- CNTK's API is usually more complicated.
- It has a dedicated user base and a small community, resulting in fewer available resources and limited third-party integrations.
12. Spark ML
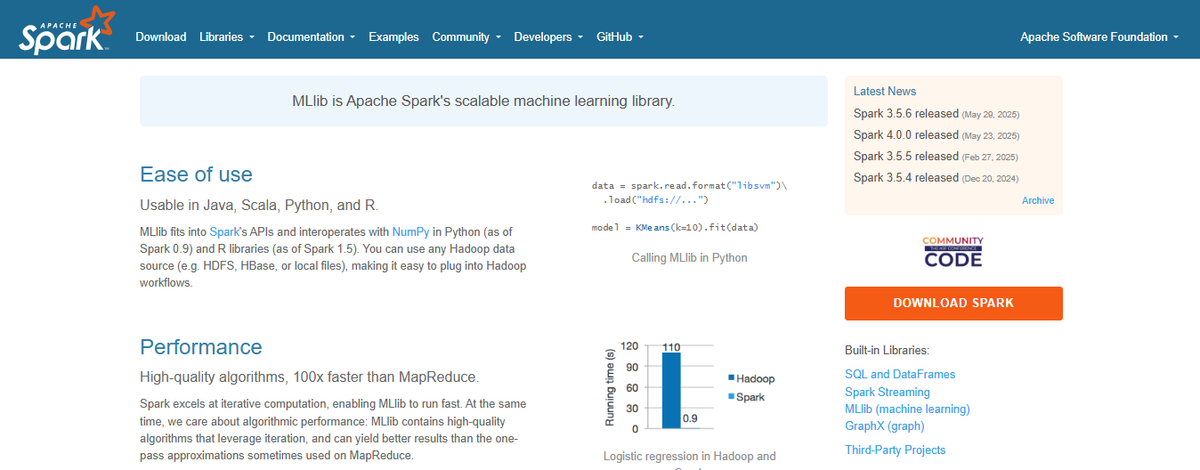
Spark ML can run in clusters. In other words, it can handle enormous matrix multiplication by taking slices of the matrix and running that calculation on different servers. (Matrix multiplication is among the most crucial ML operations.) That requires a distributed architecture, so your computer does not run out of memory or run too long when working with large amounts of data.
Spark ML is complicated, but instead of having to work with NumPy arrays, it lets you work with Spark RDD data structures, which anyone using Spark in its big data role will understand. And you can use Spark ML to work with Spark SQL dataframes, which most Python programmers know. So it creates dense and spark feature-label vectors for you, taking away some complexity of preparing data to feed into the ML algorithms.
Distributed Deep Learning at Scale
In January 2019, Yahoo released TensorFlowOnSpark, a library that “combines salient features from the TensorFlow deep Learning framework with Apache Spark and Apache Hadoop. TensorFlowOnSpark enables distributed deep learning on a cluster of GPU and CPU servers.”
The package integrates big data and machine learning into a good-to-use ML tool for large production use cases. The Spark ML model, written in Scala or Java, looks similar to the TensorFlow code in that it is more declarative.
13. Keras
Keras is a high-level framework that provides an interface for machine learning and deep learning processes. Keras was created to achieve faster experimentation. The framework can simultaneously run models on your system’s CPU) and GPU, accelerating the training process. Since Keras was written in Python, it inherited simple syntax and modular programming, making it beginner-friendly.
Keras is simple, offering numerous easy-to-use APIs that reduce the amount of code required to complete various machine learning tasks. Besides its simple APIs, Keras demonstrates excellent flexibility and can run on top of TensorFlow and other open-source frameworks, such as Microsoft CNTK and Theano. Companies like Uber, Netflix, and Square utilize Keras frameworks to develop deep learning models for their mobile applications.
Features:
- Keras is modular, containing pre-built functions, variables, and modules that make coding easier when building deep learning applications and models.
- Allows you to export models to JavaScript to run them directly in the browser for various Android and iOS devices.
- Has numerous prelabeled datasets, allowing users to access and train more easily.
Pros:
- An excellent choice for projects where researchers want to build, train, and deploy models quickly.
- Great for fast prototyping and can support various operating systems, including:
- Linux
- macOS
- Windows
- When compared to TensorFlow, Keras has more debugging functionalities and toolkits.
- Has a vast community of developers and robust documentation and tutorial materials that allow beginners to soft pedal into deep learning.
Cons:
- Although Keras can provide interfaces for TensorFlow and Theano, it can’t stand alone; it needs a back-end framework to function.
- Relative to TensorFlow, Theano, and PyTorch, Keras is slow and requires more time to process algorithms and train deep learning models.
- Keras often produces errors in low-level environments, such as when handling complex mathematical computations.
14. MXNet

MXNet is a choice for all Deep Learning developers. It supports scalability for a wide range of GPUs and programming languages.
MXNet is customizable and portable, and can utilize algorithms that require long-term and short-term memory networks, as well as convolutional neural networks. Its application extends from transportation to healthcare systems, manufacturing, and various other fields.
Pros of using MXNet:
- It is scalable, efficient, and fast.
- It supports programming languages, such as:
- R
- Scala
- Python
- JavaScript
- C++
Cons of using MXNet:
- MXNet has less open-source community support as compared to TensorFlow.
- Bug fixes and feature updates take longer due to a shortage of community support.
15. WEKA
It is a bundle of data mining and machine learning algorithms that developers can directly implement with datasets. It aids in data classification, pre-processing, clustering, regression, and other related tasks. It has gained popularity in sectors such as healthcare imaging, decision-making projects, and data mining projects, among others.
Pros of using WEKA:
- This framework provides all the essential functionalities a student needs to begin working with ML projects.
- For clustering and classifying data, it is a simple and easy-to-use tool.
Cons of using WEKA:
- It has limited learning materials and online support.
16. Spark MLLib
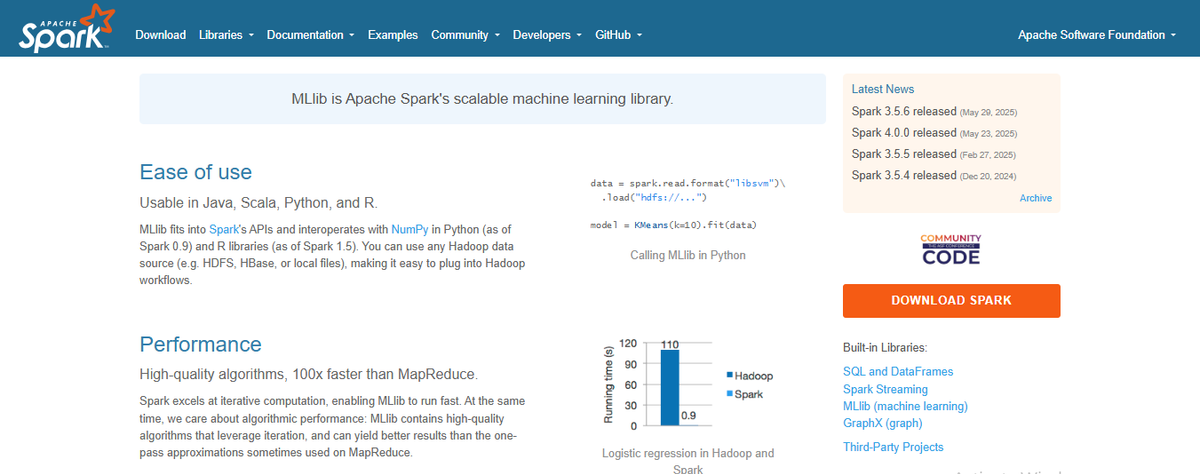
MLLib is Apache Spark's ML library. This open-source framework provides a programming interface that is familiar to all Python-based machine learning developers. It focuses on working with Resilient Distributed Dataset (RDD) data structure rather than NumPy arrays.
It is Spark's fundamental data structure. It comprises various learning algorithms, including regression, classification, collaborative filtering, clustering, and low-level optimization, among others.
Pros of using Spark MLLib:
- It is easy to use.
- It is fast and multilingual.
- It has advanced analytics features.
Cons of using Spark MLLib:
- It does not cater to any automatic optimization process.
- It is not suitable for a multi-user environment.
17. Amazon Machine Learning
It is a cloud-based framework and service that allows developers to build ML algorithms. This service includes various visualization tools and wizards designed for developers with diverse skill levels.
Developers can easily connect to data stored in RDS or Amazon S3 and retrieve that data for developing predictive machine learning models. Its widespread application lies in image classification, binary classification, corporate predictions, stock share forecasting, and more.
Pros of Using Amazon Machine Learning:
- It supports ML projects to leverage cloud infrastructure.
- It has high performance and is cost-effective.
Cons of Using Amazon Machine Learning:
- There is still room for improvement in integrating multiple programming language support.
18. Metaflow
Developed by Netflix and available as an open-source project since 2019, this framework simplifies various challenges related to scaling and versioning machine learning (ML) projects. Metaflow stores code, data, and dependencies in a content-addressed memory, enabling the further development of workflows, the reproduction of existing ones, and the editing of new ones.
By offloading individual steps to separate nodes on AWS, Metaflow simplifies scaling the ML workflow, eliminating the need to manage communication between nodes. The framework is beneficial if you plan to manage and execute your ML workflow in a production environment on AWS.
19. Fast.ai
Developing an ML model prototype is time-consuming. As the name suggests, fast.ai makes it faster. The framework's high-level API offers preconfigured algorithms and a well-structured approach, ensuring the faster development of functioning deep learning model prototypes.
But that doesn't make the framework any less enjoyable for experts. The low-level API can be used to create sophisticated and finely tuned ML models and optimize them down to the smallest detail.
Making Neural Networks Accessible to All
The goal of the framework and the non-profit organization behind it is to “make neural networks uncool again”. This is not intended to belittle the popularity of neural networks, but rather to broaden their accessibility beyond the academic elite and experts.
20. XGBoost
If you work with structured or tabular data, an algorithm based on decision trees should be on your shortlist. XGBoost offers the perfect combination of software and hardware optimization to accelerate the Gradient Boosted Trees algorithm.
With APIs in Python, Java, C++, Scala, and Julia, the framework supports multiple implementation options for Gradient Boosted Trees and runs on CPUs, GPUs, and distributed computing resources.
Fast, Optimized Tree-Based Modeling
The framework has already performed well in many Kaggle competitions and, thanks to its speed, offers shorter calculation times than normal gradient boosting. The combination of hardware optimization, parallelization, and cloud integration makes the framework ideal for accelerating calculations based on decision trees.
21. Azure ML Studio
This ML framework enables Microsoft users to model ML projects with ease. Developers can also create APIs out of these models and extend them to other services. It provides 10 GB of storage (approx.) for a single account to store data models. It has a wide range of algorithms and can operate on Microsoft tools and third-party software as well.
If developers want to execute ML projects anonymously, Azure ML Studio also allows them to run it for 8 hours. Its widespread application lies in predictive modeling, enterprise-grade security, cost management & analysis, etc.
Pros of using Azure ML Studio:
- Developers can connect Azure cloud storage for larger ML models.
- It is scalable.
Cons of using Azure ML Studio:
- It is not the best option if you want to deploy your tools outside of Microsoft Azure.
22. ONNX (Open Neural Network Exchange)
ONNX is an open-source AI tool for developers that facilitates interoperability between many ML models rather than being an ML framework in and of itself. Makes it possible for models developed using PyTorch, TensorFlow, and other frameworks to be effortlessly transported between platforms. Supported by Microsoft, Facebook, and AWS.
Use case: Ideal for organizations that need cross-framework model deployment.
23. LightGBM
If you’re working with structured data and need fast and efficient gradient boosting, LightGBM (Light Gradient Boosting Machine) is your best bet. Developed by Microsoft, it’s known for its lightweight design, fast training speed, and high accuracy in classification and regression tasks.
Key features of LightGBM:
- Lightning-Fast Training: Uses histogram-based learning to train much faster than traditional gradient boosting methods like XGBoost and CatBoost.
- Lower Memory Usage: Optimized to consume less memory, making it efficient for large datasets with high-dimensional features.
- Highly Scalable: Supports parallel computing and GPU acceleration, enabling faster training on large datasets and distributed environments.
- Handles Large Datasets: Works efficiently with millions of data points and thousands of features, making it ideal for real-world applications like finance, healthcare, and e-commerce.
- Great for Kaggle Competitions: A favorite among data scientists and Kaggle competitors, as it consistently outperforms other ML models in predictive accuracy and efficiency.
Pros:
- Faster than XGBoost and other gradient boosting models
- Optimized for large datasets
Cons:
- Can be sensitive to hyperparameter tuning
- Not ideal for deep learning tasks
24. Shogun
Shogun is an open-source machine learning framework that works well with C++. It is free and useful for developers who want to design algorithms and data structures specifically for problems in the fields of education and research.
Shogun can also connect with other ML libraries, including LibLinear, LibSVM, SVMLight, and LibOCAS, among several others. Additionally, Shogun is compatible with other languages and frameworks, such as:
- R
- Python
- Java
- Octave
- C#
- Ruby
- MatLab
- Lua
Other highlights of this machine learning framework include its ability to implement Hidden Markov models, process large volumes of data, and provide several flexible features and functionalities, making it user-friendly.
Key features:
- Written in C++.
- Open-source and free.
- Helpful in designing algorithms and data structures, especially in the fields of education and research.
- Connects with other ML libraries, including LibLinear and LibSVM, and several others.
- Compatible with R, Python, Java, MatLab, C++, and other languages.
25. Apple’s Core ML
Core ML was primarily developed for macOS, iOS, and tvOS applications and is highly beginner-friendly, catering to graduates and self-taught developers. Core ML is very comprehensive and provides a plethora of features, including:
- Image classification
- Sentence classification
- Natural language processing
- Barcode detection
- Gameplay Kit
- Object tracking
With its unique low-level tech stack, it can deliver excellent performance by utilizing both CPUs and GPUs. Concerning security and ease of use, Core ML ensures user privacy and app functionality, even in offline mode.
Key features:
- Developed for macOS, iOS, and TVOS applications
- Beginner friendly
- Supports both CPUs and GPUs
26. CatBoost
CatBoost, developed by Yandex, is a gradient boosting library that’s optimized for categorical data processing. Unlike other frameworks, it automatically handles categorical features, reducing the need for manual preprocessing.
Key features of CatBoost:
- Automatic Handling of Categorical Features: Unlike other boosting frameworks, CatBoost natively processes categorical variables without requiring label encoding or one-hot encoding, reducing preprocessing time.
- Fast Training Speed: Optimized for efficiency and scalability, making it well-suited for large datasets without compromising accuracy.
- Works Well with Noisy Data: CatBoost is more robust against noisy data than traditional gradient boosting models, making it an ideal choice for real-world applications.
- Great for Ranking, Classification & Regression: Frequently used in recommendation systems, search ranking, and personalized advertising, as well as general classification and regression tasks.
- GPU Support: Provides built-in GPU acceleration, significantly speeding up training times on large-scale datasets.
Pros:
- Removes the need for manual categorical encoding.
- Performs well even with unbalanced datasets.
Cons:
- Slower training on small datasets.
Related Reading
How to Choose the Right ML Framework for Model Development

Every framework supports different kinds of machine learning tasks. Some are great for deep learning, while others excel at structured data.
- If you’re working with deep learning (CNNs, RNNs, Transformers) → Go for TensorFlow, PyTorch, or MXNet
- If your model is based on structured/tabular data → Use Scikit-Learn, XGBoost, LightGBM, or CatBoost
- If you need fast experimentation with simple models → Keras is an easy choice
Tip: If your project involves text or image processing, deep learning is usually the way to go. If it’s numbers and structured datasets, traditional machine learning (ML) frameworks work best.
How Much Computing Power Do You Have?
Some frameworks demand high-performance GPUs, while others can run on a standard laptop.
- Need heavy GPU/TPU acceleration? → TensorFlow, PyTorch, and MXNet are optimized for that
- Working with a standard CPU-based system? → Scikit-Learn, XGBoost, and LightGBM will be more efficient
- Deploying on mobile or edge devices? → TensorFlow Lite, ONNX, or MLKit will work best
Tip: If you don’t have access to a high-performance machine, choosing a lightweight framework will save you from long training times and slow debugging.
How Scalable Does Your Model Need to Be?
Not every model is meant to stay small. If your ML project is going into production or needs to handle massive data, scalability is key.
- For large-scale production AI models → TensorFlow, MXNet, and H2O.ai work best.
- For research, experimentation, or smaller models → PyTorch, Keras, and Scikit-Learn are better choices.
- For cloud and distributed computing → MXNet, TensorFlow, and ONNX support multi-GPU/cloud environments.
Tip: If you’re just experimenting with ML and don’t need a large-scale deployment, avoid TensorFlow; it’s overkill.
How Easy Do You Want the Development Process to Be?
Some frameworks are user-friendly, while others require deep technical expertise.
- Want something beginner-friendly? → Scikit-Learn, Keras, or CatBoost are easy to pick up.
- Need complete control and flexibility? → PyTorch or TensorFlow lets you tweak every detail.
- Want something automated? → H2O.ai has AutoML features to handle tuning for you.
Tip: If you’re just getting started, Scikit-Learn and Keras are the easiest to learn. If you want more control, PyTorch is an excellent balance between power and usability.
What’s Your Deployment Plan?
Think ahead, how will your model be deployed? Some frameworks are built for quick deployment, while others are harder to integrate.
- Deploying on the web, cloud, or large-scale apps? → TensorFlow, ONNX, and MXNet work well.
- Deploying on mobile/edge devices? → TensorFlow Lite, MLKit, or ONNX are optimized for that.
- Need API integration with enterprise apps? → H2O.ai and TensorFlow Serving are designed for seamless deployment.
Tip: If you don’t plan for deployment early, you might end up retraining your model in a different framework later, which wastes time.
Related Reading
Start Building with $10 in Free API Credits Today!
Inference delivers OpenAI-compatible serverless inference APIs for top open-source large language model (LLM) models, offering developers the highest performance at the lowest cost in the market. Beyond standard inference, Inference provides specialized batch processing for large-scale async AI workloads and document extraction capabilities designed explicitly for RAG applications.
Start building with $10 in free API credits and experience state-of-the-art language models that balance cost-efficiency with high performance.
Meet with our research team
Schedule a call with our research team to learn more about how Specialized Language Models can cut costs and improve performance.