'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Aug 14, 2025
What Is Model Context Protocol & How It Connects AI to Real-World Data
Inference Research
Have you ever tried to keep an LLM in sync with live data only to hit token limits, rising latency, or security headaches? Model Context Protocol sits at the center of LLM Inference Optimization Techniques, showing how context windows, session memory, retrieval augmented generation, embeddings, metadata, and vector stores work together to surface the right information at the right time. This article lays out practical patterns for context management, prompt engineering, context injection, LLM Inference Optimization, chunking, caching, and session continuity so you can confidently integrate AI with real-world data sources in a secure, efficient way that unlocks practical, high-impact applications.
To do that, Inference offers AI inference APIs that handle secure data connectors, streaming, access control, and context stitching so you can focus on building reliable features that use up-to-date data without extra infrastructure work or compromise on speed and privacy.
What is the Model Context Protocol (MCP)?
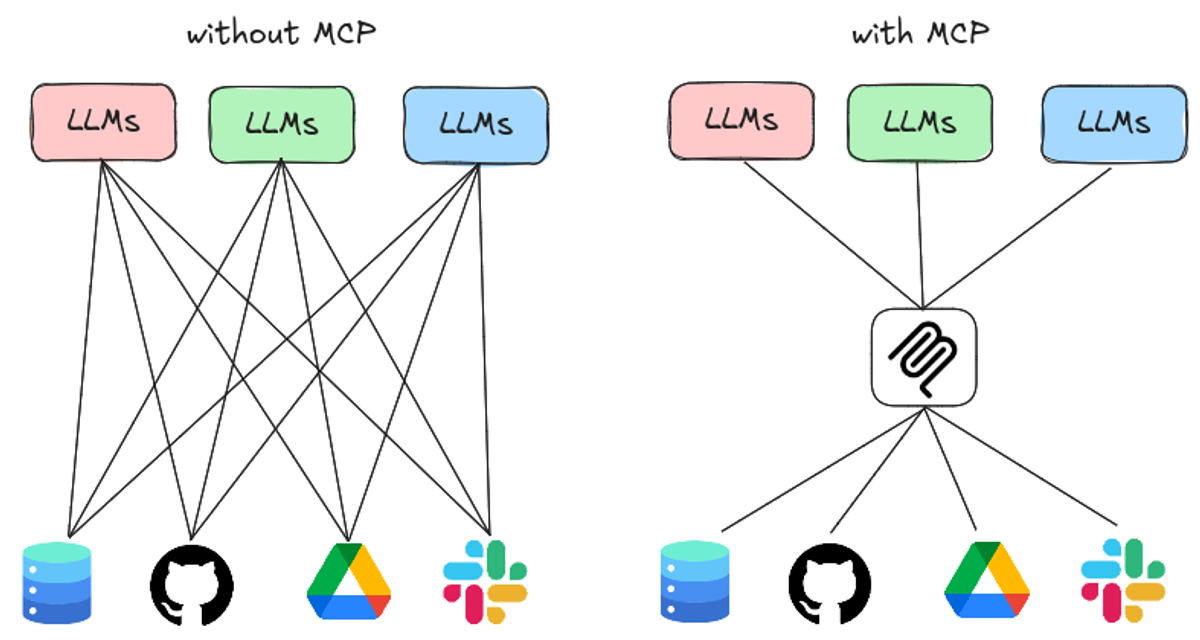
Model Context Protocol, released by Anthropic in November 2024 and developed by Mahesh Murag, standardizes how language models access external context, tools, and resources. It answers a practical engineering question: how many AI clients reliably and securely talk to many data and tool providers without bespoke wiring for each pair.
MCP defines a consistent, machine-readable contract so LLM-driven applications can request and receive context, invoke functions, and coordinate sampling across heterogeneous systems. This reduces duplicated integration work and makes context exchange predictable and auditable.
Which Practical Problems MCP Fixes and How It Changes Integrations
Teams building agents and AI apps faced the N times M problem: each client needed a custom integration to each server or tool. That produced fragmentation, inconsistent prompt logic, and brittle pipelines for retrieval augmented generation, tool use, and orchestration. MCP replaces that web of point-to-point integrations with a single protocol for capability discovery, tool invocation, and resource access. Clients become fungible with servers because both speak the same JSON RPC 2.0-based protocol. The result is faster adoption of new data sources, fewer security mistakes, and more precise separation of responsibilities between app code and integration code.
How MCP Fits Into the Toolkit for Context Management and Retrieval
Context matters for model behavior, whether you run pure prompts, long token windows, RAG, or multimodal inputs. MCP complements those techniques by providing a standard channel for retrieving and streaming external context into a model-driven application.
Use cases include fetching relevant documents for RAG, exposing business systems like CRM and ticket systems for agent workflows, and offering code or file system access for coding assistants. MCP sits next to other pieces like vector databases, retrieval layers, and model serving, acting as the interoperability layer between those pieces and LLM clients.
Core Technical Stack: JSON-RPC 2.0, Stateful Sessions, and Sampling Coordination
MCP uses JSON RPC 2.0 messages to carry requests, responses, notifications, and subscriptions. It creates stateful sessions so clients and servers can coordinate which pieces of context to expose and when to request sampling from a model.
That sampling coordination helps avoid duplicated rounds of context transfer and gives servers hooks to provide only the slices of data a model needs at inference time. JSON RPC also enables bidirectional messaging, subscriptions, and streaming updates for live resources.
MCP Architecture: Host Client Server Made Concrete
A host process owns its lifecycle and policy. It spawns multiple clients and enforces user:
- Authorization
- Consent
- Runtime policies
Each client owns a one-to-one session with a server. Servers publish capabilities, tools, resources, and prompt templates.
This layout isolates security boundaries:
- The host decides which client can talk to which server and whether the user permits exposure of particular resources.
- The model runs within the client environment and decides when to request server tools or data.
Clients Explained: What They Do and How They Behave
MCP clients are AI applications or agents that want context and capabilities. They handle protocol negotiation, route messages, maintain subscriptions, and enforce client-side policies.
A client presents the model with unified prompt scaffolding, interprets model tool invocation decisions, and performs local interpolation of prompts and results. Once a client is MCP compatible, it can connect to any MCP server and use its exposed resources with minimal extra engineering.
Servers Explained: Exposing Tools, Resources, and Prompts
MCP servers wrap external systems and present them as standardized primitives. A server defines tools as:
- Callable functions with descriptions
- Arguments
- Expected return types
It exposes resources such as document collections, code repositories, or database access. It also ships prompt templates that clients can trigger on behalf of users. Server authors focus on one integration and then distribute that capability to any MCP client without repeated wiring.
MCP Primitives: Prompts, Tools, and Resources In Action
Prompts act like user-invoiced templates. Tools represent functions the model can call, such as:
- Running a query
- Executing a git operation
- Calling an internal API
Resources are pull-style objects: documents, file slices, or live database views. The model within a client chooses when to use a tool or request a resource, and the protocol ensures the request includes metadata for consent, tracing, and sampling control.
Security Consent and Policy Control Baked Into the Flow
The host enforces authorization and consent. Clients and servers exchange capability and permission metadata during session setup so the user or an admin can approve or reject access. Servers must operate within constraints declared by the host, and messages include provenance and audit information for compliance and debugging.
How MCP Reduces Duplicated Effort and Enables Reuse
Build an MCP server once, and many clients can use it. Infrastructure teams can ship integrations to vector stores, CRMs, or enterprise file systems, and product teams can reuse those integrations without reimplementing connectors. That separation of concerns speeds delivery and centralizes sensitive credential handling in infrastructure components.
Who Already Supports MCP and Where You Can Find it
Early ecosystem adopters include Cursor, Windsurf by Codium, Cline for VS Code, Claude desktop, and Claude code, among others. Agents like Goose also integrate as MCP clients.
Anthropic provides both Python SDK and TypeScript SDK implementations to help teams adopt the protocol and to build servers and clients quickly. The complete official documentation and SDK guides are available from Anthropic in their MCP docs and in the MCP GitHub repositories, with full references for the protocol, message types, and sample implementations.
Workshop and Community Learning Resources
Mahesh Murag delivered a workshop titled Building Agents with Model Context Protocol at the AI Engineer Summit, where he presented hands-on examples for authoring MCP servers, wiring clients, and orchestrating sampling sessions. The session walked through common patterns for exposing vector database results, implementing consent flows, and designing tool schemas that LLMs can act on reliably.
A Simple JSON RPC Example So You Can Picture The Exchange
A client might send a request that enumerates server capabilities and requests a resource sample. The server replies with a subscription ID and streams document slices as notifications while the client routes those slices into a model prompt. This pattern keeps the model from receiving unnecessary payloads and allows the server to paginate or filter based on model hints.
Design Principles For Implementing MCP Servers and Clients
Design servers to expose minimal, well-described tools and to include an explicit schema for arguments and results. Keep resources chunkable and indexable for RAG-style access.
From the client side, present contextual signals to the model that guide tool calls and include fallback behavior when a server is unavailable. Instrument every session with tracing IDs so you can audit model decisions and reproduce failures.
Where Mcp Helps Most and What to Ask Next
MCP yields immediate benefits when you need: consistent access to enterprise systems, federated tool invocation, composable agent workflows, and safer delegation of data access. Which systems in your stack would benefit from being a reusable MCP server, and which client experiences would improve once those servers exist and interoperate with multiple LLM-driven products?
Related Reading
- Speculative Decoding
- Lora Fine Tuning
- Gradient Checkpointing
- LLM Quantization
- LLM Use Cases
- Post Training Quantization
- vLLM Continuous Batching
What are the Three Key Components to MCP?

MCP splits responsibility cleanly into three parts. Each part has a distinct role, and together they enable applications to safely integrate multiple external capabilities with a single model interface.
MCP Host
The user-facing AI interface. This is the app the end user interacts with, such as a Claude app, an IDE plugin, or a chat product.
How it contributes:
The host is where users send queries and view results. It embeds one MCP client per server and coordinates those clients so output from multiple servers can appear in a single conversation or UI. For example, a developer in an IDE sees code suggestions from a code analysis server and documentation pulled from a docs server at the same time.
MCP Client
The intermediary that manages secure connections between the host and each server. There is one client instance per server to enforce isolation.
How it contributes:
The client handles authentication, encryption, session state, permission boundaries, and enforcement of roots and sampling policy. It mediates every request and response between its host and its paired server.
If a server asks for a model completion, for specific resources, or to run a tool, the client evaluates the request, applies the host policy, and either forwards, modifies, or rejects the request. A client can refuse a request that appears to be data exfiltration or can substitute a different model for cost or privacy reasons.
MCP Server
An external program that exposes capabilities to clients. Servers provide tools, read resources, and offer domain specific prompts.
How it contributes:
Servers connect to external data sources like:
- Google Drive
- Slack
- GitHub
- Databases
- Browsers and present specific capabilities back to clients
They implement domain logic and expose executable operations that an LLM can invoke. A server might test suites, search a code base, or fetch Slack threads depending on the tools it offers. Servers can also request model completions from the client through sampling when they need language reasoning tied to their data.
Why the Model Context Protocol has Traction and Adoption
The protocol encoded the agent design intuition Anthropic articulated in their Building Effective Agents post. That intuition favors clear separation of authority, permissioned resource access, and client control over models and privacy. The Model Context Protocol makes those ideas a working API for connecting many small servers to many hosts.
Community growth:
The server ecosystem has expanded fast. There are more than a thousand community-built open source servers along with official company integrations. Contributors have been improving the protocol and the core infrastructure in public repositories and integrations.
Tools
- Purpose: Enable servers to expose executable functionality to clients.
- Control Type: Model-controlled.
- Control Meaning: Represent dynamic operations exposed from servers to clients that the LLM can invoke to modify state or interact with external systems.
Resources
- Purpose: Allow servers to expose data and content that clients can read and use as context for LLM interactions.
- Control Type: Application-controlled.
- Control Meaning: The client application decides how and when resources are used.
Prompts
- Purpose: Provide predefined templates and workflows for standardized LLM interactions.
- Control Type: User-controlled.
- Control Meaning: Designed to be used directly by the user, exposed from servers to clients.
Server-Side Primitives Every Developer Should Know
Feature set:
- Tools
- Resources
- Prompts
- Tools that servers can run
Function:
Tools let a server expose executable functionality to a client and its LLM.
Control type:
Model-controlled. The LLM may decide to call a tool as part of its
reasoning.
Control meaning:
Tools represent actions that can change state or interact with external systems, such as performing a search, running a database query, or posting to Slack. These actions are surfaced to the client so the client can enforce policy or log activity before execution. Examples include running a unit test, creating an issue, or launching a browser navigation.
Resources: The Data Servers Share
Function:
Resources let a server expose data and content that clients can read and use as context for LLM interactions.
Control type:
Application-controlled. The client application decides when and how those resources are provided.
Control meaning:
The host decides which files, folders, or channels are visible to a server. Read-only data might include documents from Drive, a repository snapshot, database rows, or messages from Slack. These inputs become context for model inference when the client supplies them.
Prompts: Standardized Workflows and Templates
Function:
Prompts are predefined templates and workflows a server can offer for common tasks.
Control type:
User-controlled. The prompts are intended for the user and are surfaceable by the client with user intent.
Control meaning:
Prompts let a server ship domain-specific instruction sets such as a pull request reviewer template or a customer support triage flow that a client can present to the user.
Client Side Primitives Every Integrator Will Use
Roots: Scoped, Auditable Access Points
What a root does:
A root defines an explicit location in the host file system or environment that a server is allowed to interact with.
Why it matters:
Roots are the permission boundaries. They prevent a server from wandering across unrelated files or secrets by limiting its operations to a single folder, a virtual file system, or a named resource handle.
How clients enforce them:
The client maps a server to its approved roots and refuses or redacts any server request that references data outside those scopes. A root might map a server to a single project folder or to a virtual file system with only example data.
Sampling: Servers Asking The Client for Model Completions
What sampling is:
Sampling flips the usual client-server call pattern and lets servers request LLM completions from the client rather than the other way around.
Why sampling matters:
Sampling gives the client complete control over model selection, hosting, privacy, and cost while still letting servers use language reasoning. Servers can request specific inference parameters like model preferences, system prompts, temperature, and token limits.
How control works in practice:
The client receives sampling requests and can accept them as is, alter model choice to meet policy or cost goals, throttle the request, or deny it if the server appears malicious. If a server requests a high-temperature run on a large model, the client can swap in a cheaper model or refuse the request.
Typical interaction flow, So You Can Picture It
Question:
How do these pieces move data and decisions?
Flow example:
A user in a host triggers a code search. The host forwards the action to the client assigned to a code analysis server. The client supplies allowed resources from the project root to the server.
The server decides a tool should run a repo search and requests a completion through sampling to summarize matches. The client reviews the sampling request, selects a model consistent with the privacy policy, executes the completion, and then returns the final answer to the host for presentation to the user.
Related Reading
- KV Cache Explained
- LLM Performance Metrics
- LLM Serving
- Pytorch Inference
- Serving Ml Models
- LLM Benchmark Comparison
- Inference Optimization
- Inference Latence
- LLM Performance Benchmarks
How MCP Works and Security Considerations for MCP Servers

1. Initial Connection
The MCP client (for example, Claude Desktop) opens a secure channel to configured MCP servers on the device or network. Transport options include TLS over HTTP with server-sent events for streaming, WebSocket for bidirectional I/O, or local IPC sockets for very low latency. The client authenticates the server endpoint and binds the session to the user context.
2. Capability Discovery
The client requests a capability manifest. Each server replies with a machine-readable catalog that lists tool names, input and output schemas, supported operations, allowed scopes, and metadata like version, cost, and expected latency. Manifests use JSON schemas and can include example prompts and structured response schemas to help the model map outputs into the chat context.
3. Authentication and Session Binding
If a server requires authorization, the client negotiates tokens using an OAuth-style flow with PKCE and short-lived credentials. The exchange binds the token to the client session and to the requested scopes to limit lateral access. Ephemeral tokens, session binding, and audience restrictions reduce token replay risk.
4. Registration and Capability Indexing
The client registers discovered capabilities with the assistant runtime. Registration stores capability descriptors in a capability index the model can consult while generating. The index supports fast lookups and prewarming of hot capabilities before they are invoked.
5. Versioning and integrity checks
Clients verify capability signatures or checksums to ensure manifest integrity. They subscribe to capability updates so changes like added scopes or new endpoints can be surfaced to users and to automated policy checks.
From user request to external data: The Operational Path When Claude Needs Live Facts
1. Intent and Need Recognition
The assistant classifies the user's utterance and marks whether it requires an external tool. It checks the capability index to map the need to specific servers or connectors.
2. Tool Selection and Plan Drafting
The model crafts a short plan that specifies which tool to call, the input schema to use, and how to fuse the tool output into the conversation. The plan includes fallback options and error handling steps.
3. Permission Prompt and Consent
The client shows a clear permission prompt to the user with requested scopes, what data will be sent, and the potential risks. Only after explicit approval does the client proceed to invoke the external capability.
4. Invocation and Request Formatting
The client formats the request per the server schema, often as structured JSON with fields the server expects. Use typed fields instead of free text to reduce ambiguity and token waste. Where possible, the client applies compression and strips unnecessary context to reduce payload size.
5. Efficient Transport and Streaming
The client opens a streaming channel if the server supports it. The server can emit incremental partial results using SSE or WebSocket frames so the assistant can begin composing an answer before the full payload arrives. This reduces perceived latency.
6. External Processing and Safety Checks
The server executes the operation. Servers should run actions with least privilege, enforce sandboxing for any code execution, and return provenance metadata like timestamps and signed digests of results.
7. Result Normalization
Servers return structured outputs with schema tags and optional human-readable summaries. The client validates the server response against the declared schema and performs basic sanitization, type checking, and size checks before exposing the data to the model.
8. Context Integration and Compression
The assistant ingests the structured tool output into its working context. To conserve model context tokens, the client can summarize or embed the result into a compact vector and attach a short textual summary when appropriate. If the result will be reused later, store it in a local retrieval store for retrieval augmented generation instead of reattaching full text.
9. Response Generation with Provenance
The assistant generates the reply, citing the tool and including provenance metadata when required by policy. If a long operation is still in progress, the assistant can provide an interim answer and signal a follow-up when final data arrives.
Start Building with $10 in Free API Credits Today!
Inference offers OpenAI-compatible serverless inference APIs that run top open source language models at scale. The platform handles autoscaling, GPU allocation, and model versioning, so you call a single endpoint and get predictable latency and throughput.
Under the hood, it uses model quantization, mixed precision, kernel tuning, and memory pooling to cut GPU costs while keeping response quality. How fast can your app respond under load when the model runtime is tuned for throughput, token streaming, and attention memory reuse?
Batch Processing Built for Large Asynchronous AI Workloads
When you need volume rather than single request latency, Inference exposes specialized batch processing for large async jobs. The system groups requests, packs prompts into efficient batch tensors, and schedules execution to maximize GPU utilization.
It supports micro-batching, job priority, and backpressure handling, so throughput scales without blowing up cost. The batch pipeline also preserves context continuity across segments, letting you compact session state and reuse embeddings between jobs instead of recomputing them.
Document Extraction and Retrieval Augmented Generation Ready Tools
Inference includes document extraction workflows tailored to RAG use cases. Chunking and tokenization break documents into retrieval-sized segments. The pipeline builds embeddings, stores vectors in a retrieval index, and links passage-level provenance back to the source.
It supports overlap strategies, chunk size tuning, and context stitching so the assembled prompt fits the model context window without losing source attribution. Do you want document layout parsing, OCR, or plain text extraction as the first step in your retrieval flow?
Start Building Fast with Ten Dollars in Free API Credits
Sign up and get ten dollars in free API credits to prototype quickly. You get OpenAI-compatible endpoints, client libraries, and examples for prompt engineering, streaming, and batched inference.
The SDKs include helpers for context serialization, session state management, and embedding pipelines so you can test retrieval workflows and measure cost per query on real data. Which endpoint would you try first for your use case?
Model Selection and Cost Tradeoffs for Practical Deployments
You pick from a catalog of models that balance latency, token throughput, and quality. Inference supports quantized variants, distilled smaller models, and full precision models for different SLAs.
It also offers model sharding and tensor offload to split memory pressure across devices. Use smaller models for routing and embeddings, and larger models for final answer synthesis. Combine these tactics with context compaction and token budget controls to keep per-request cost predictable.
How the Model Context Protocol and Context Management Cut Waste
Model Context Protocol style practices matter when you manage multi-turn sessions and long documents.
Treat context as a protocol:
- Serialize session state
- Version context fragments
- Store provenance in a context store
Apply sliding window strategies to maintain continuity while trimming older tokens.
Use context caching so repeated prompts reuse the tokenized prefix and reuse the attention key value caches where the runtime supports it. Implement context fragmentation and compaction to reduce token counts for long-running chats while preserving instruction state and user intent.
Practical Techniques for Lower Latency and Lower Cost
Reduce memory footprint with int8 or int4 quantization and combine that with kernel-level optimizations. Use dynamic batching with adaptive batch sizes to match incoming traffic without stalling.
Stream generation to the client to reduce perceived latency and to allow early termination when the response meets a confidence threshold. For retrieval augmented generation, cache embeddings and cache nearest neighbor results so repeated queries avoid vector database hits.
What metric will you optimize first:
- Latency
- Throughput
- Cost per response?
Operational Controls and Observability You Can Trust
Monitor prompt token counts, context window usage, and per-request GPU time. Instrument context provenance so you can trace an output back to the document chunk, embedding version, and prompt template.
Enforce context length limits and provide alerts when compaction or truncation occurs. These controls help you avoid silent quality regressions while keeping costs under control.
Integrations, SDKs, and Migration Paths
OpenAI-compatible endpoints let you bring existing code with minimal changes. SDKs include helpers for prompt templates, context serialization, and session state APIs modeled after a Model Context Protocol approach.
Use the migration tools to test models side by side and to validate that context handling, tokenization, and streaming semantics match your expectations. Would you prefer a drop-in replacement for current OpenAI calls or a phased swap with A/B testing?
Related Reading
- Continuous Batching LLM
- Inference Solutions
- vLLM Multi-GPU
- Distributed Inference
- KV Caching
- Inference Acceleration
- Memory-Efficient Attention
Meet with our research team
Schedule a call with our research team to learn more about how Specialized Language Models can cut costs and improve performance.