'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Apr 22, 2025
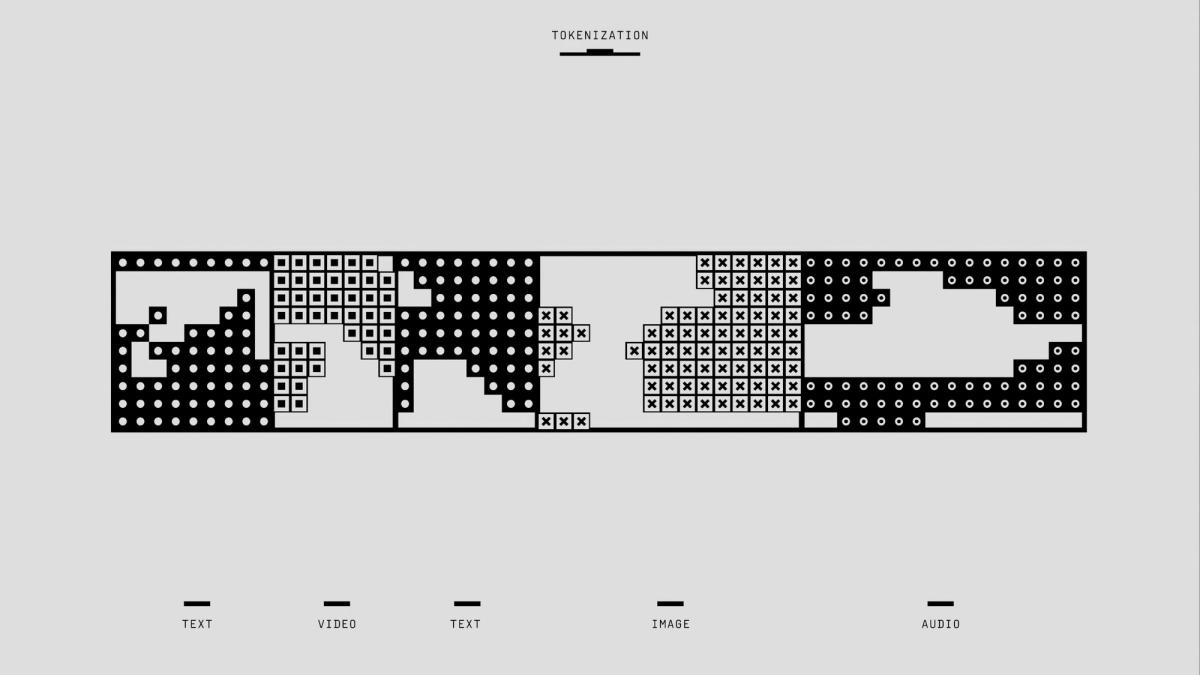
What is Machine Learning Inference? A Guide to Smarter AI Predictions
Inference Research
Training a machine learning model is only half the journey, getting it to make accurate predictions on new data is where real impact happens. This process is known as machine learning inference, which turns a trained model into a functional AI system. Whether you're building AI for healthcare risk assessment, fraud detection, or content recommendations, inference is the key to applying machine learning in the real world. In this article, we’ll explain how machine learning inference works, why it’s essential for AI deployment, and how to optimize it for speed and accuracy. You’ll also learn how AI inference APIs can streamline this process, helping you deploy models that make fast, reliable predictions at scale. Additionally, understanding AI Inference vs Training is crucial to optimizing model performance and ensuring smooth deployment.
AI inference APIs are a valuable tool for achieving your inference objectives. These application programming interfaces can reduce the time and costs of deploying machine learning models and help you get the accurate AI predictions you need faster.
What is Machine Learning Inference?
Machine learning inference involves feeding live data points into a machine learning model (or ML model) to generate an output, such as a numerical score. This process is called "operationalizing an ML model" or "deploying an ML model into production." Once the model is in production, it is often referred to as artificial intelligence (AI) due to its ability to perform tasks that mimic human thinking and analysis.
Machine learning inference typically involves deploying a software application into a production environment. The ML model is a set of code that executes a mathematical algorithm. This algorithm processes data based on specific characteristics, or “features,” critical to making accurate predictions or decisions.
The Two Parts of Machine Learning Inference
An ML lifecycle can be divided into two distinct parts.
- The first is the training phase, in which an ML model is created or “trained” by running a specified subset of data through it.
- ML inference is the second phase, in which the model is put into action on live data to produce actionable output. The data processing by the ML model is often referred to as “scoring,” so one can say that the ML model scores the data, and the output is a score.
The Deployment of Machine Learning Inference
DevOps engineers or data engineers typically handle the deployment of ML or AI inference. Sometimes, the data scientists trained the models are asked to manage the inference process. This can create significant challenges, as data scientists may lack expertise in deploying systems.
Successful ML deployments often require close coordination between teams, and newer software technologies are increasingly being used to streamline the process. An emerging field called "MLOps" is helping to bring more structure and resources to the deployment and ongoing maintenance of ML models, ensuring they can be updated and adapted as needed.
The Process of Machine Learning Inference
Machine learning (ML) inference involves applying a machine learning model to a dataset and generating an output or “prediction”. This output might be a numerical score, a text string, an image, or structured or unstructured data.
Generally, a machine learning model is software code implementing a mathematical algorithm. The machine learning inference process deploys this code into a production environment, making it possible to generate predictions for inputs provided by actual end users.
Importance of Inference in the Machine Learning Workflow
Fuels Machine Learning Performance
Inference is a critical component of the machine learning workflow, as it enables the deployment and usage of trained models in real-world scenarios. Once a model has been trained on historical data, its primary purpose during inference is to make predictions or classifications on new data.
This phase is essential for various applications, including:
- Image recognition
- Natural language processing
- Recommendation systems, etc.
Efficient and accurate inference is essential for deploying machine learning models effectively and achieving desired outcomes in practical settings.
Supervised Learning
In supervised learning, inference refers to using a trained model to make predictions or classify new data points. During the training phase, supervised learning models learn patterns and relationships from labeled data, where each data point is associated with a known outcome or label.
Once trained, the model can generalize this knowledge to predict unseen or future data. Inference involves passing new input data through the trained model to obtain predictions or classifications based on the learned patterns and relationships encoded in the model’s parameters. The goal of inference in supervised learning is to accurately predict outcomes or classify input data based on the learned patterns from the training data.
Use Cases and Examples of Supervised Learning Inference
In supervised learning, inference finds extensive applications across various domains, including but not limited to:
- Image Classification: Inference is used to classify images into predefined categories or labels, such as identifying objects in photographs or medical images.
- Sentiment Analysis: Supervised learning models can infer the sentiment of text data, such as customer reviews or social media posts, by predicting whether the sentiment is positive, negative, or neutral.
- Disease Diagnosis: Medical professionals use supervised learning models for inferring disease diagnoses based on patient symptoms, medical history, and diagnostic tests.
- Predictive Maintenance: Supervised learning models can infer the likelihood of equipment failure or maintenance needs based on sensor data and historical maintenance records in industrial settings.
- Financial Forecasting: In finance, supervised learning models are employed to infer future stock prices, market trends, and investment opportunities based on historical market data.
Unsupervised Learning
In unsupervised learning, inference refers to extracting meaningful patterns, structures, or relationships from unlabeled data. Unlike supervised learning, where the data is labeled with known outcomes, unsupervised learning models work with unstructured or unlabeled data. They aim to uncover hidden insights or representations within the data itself.
Inference in unsupervised learning involves clustering similar data points, dimensionality reduction, or anomaly detection without explicit guidance from labeled examples. Unsupervised learning models infer underlying structures or groupings in the data, which can provide valuable insights or serve as a basis for further analysis and decision-making.
Use Cases and Examples of Unsupervised Learning Inference
Unsupervised learning inference finds applications across various domains, enabling exploratory data analysis, pattern discovery, and data-driven decision-making. Some everyday use cases and examples include:
- Customer Segmentation: Unsupervised learning models can infer distinct customer segments or clusters based on demographic, behavioral, or transactional data, allowing businesses to tailor marketing strategies and personalize customer experiences.
- Anomaly Detection: In cybersecurity, unsupervised learning models infer anomalous patterns or unusual behaviors in network traffic, identifying potential security threats or suspicious activities without prior knowledge of specific attack signatures.
- Topic Modeling: Unsupervised learning techniques such as Latent Dirichlet Allocation (LDA) can infer topics or themes within large text corpora, facilitating document clustering, content recommendation, and sentiment analysis in natural language processing tasks.
- Dimensionality Reduction: Methods like Principal Component Analysis (PCA) or t-distributed Stochastic Neighbor Embedding (t-SNE) infer low-dimensional representations of high-dimensional data, enabling visualization and interpretation of complex datasets in fields like bioinformatics, genomics, and image processing.
- Market Basket Analysis: Unsupervised learning algorithms like Apriori or FP-growth can infer associations or frequent itemsets from transactional data, revealing patterns of co-occurring items in retail sales data and informing inventory management, product placement, and cross-selling strategies.
Reinforcement Learning
In reinforcement learning (RL), inference refers to making decisions or selecting actions based on learned policies and environmental feedback. Unlike supervised and unsupervised learning, where models learn from labeled or unlabeled data, reinforcement learning agents interact with an environment to learn optimal strategies through trial and error.
Inference in RL involves selecting actions that maximize expected rewards or cumulative return over time, given the current state of the environment and the agent’s learned policy. Reinforcement learning models infer action-selection policies by iteratively exploring the environment, observing rewards, and updating their strategies through techniques like:
- Value iteration
- Policy iteration
- Deep Q-learning
Use Cases and Examples of Reinforcement Learning Inference
Reinforcement learning inference finds applications across various domains, enabling autonomous decision-making, control, and optimization in dynamic environments.
Some everyday use cases and examples include:
- Autonomous Robotics: Reinforcement learning agents control autonomous robots to perform tasks like navigation, object manipulation, or obstacle avoidance in real-world environments. Agents infer optimal actions by learning from sensor inputs, such as camera images or lidar data, and feedback signals, such as collision avoidance or task completion rewards.
- Game Playing: Reinforcement learning algorithms learn to play complex games like chess, Go, or video games by inferring optimal strategies through trial and error. Agents make decisions based on observed game states, available actions, and rewards from winning or achieving game objectives.
- Financial Trading: Reinforcement learning models infer trading strategies for automated trading systems by learning from historical market data and feedback signals, such as profit or loss. Agents make buy/sell decisions based on inferred policies to maximize returns and optimize portfolio performance.
- Healthcare Treatment Planning: Reinforcement learning agents infer personalized treatment plans or dosing regimens for patients with chronic diseases or complex medical conditions. Agents learn from patient data, clinical guidelines, and treatment outcomes to optimize therapy decisions and improve patient outcomes.
- Energy Management: Reinforcement learning models control energy systems, such as smart grids or renewable energy sources, to optimize resource allocation, demand-response actions, and energy storage strategies. Agents infer optimal policies to balance supply and demand, minimize costs, and maximize energy efficiency.
Techniques and Methods for Inference
Inference can be categorized into multiple areas. Each inference can have unique characteristics.
Probabilistic Inference
Probabilistic inference is a fundamental technique in machine learning that involves estimating probability distributions over unknown variables given observed data. It allows models to reason uncertainly about the underlying structure of the data and make predictions based on probabilistic beliefs.
In probabilistic inference, Bayes’ theorem is often used to update prior beliefs with observed evidence, resulting in posterior distributions that capture updated beliefs about the variables of interest. Standard probabilistic inference algorithm methods include:
- Maximum likelihood estimation (MLE)
- Markov chain Monte Carlo (MCMC)
- Expectation-maximization (EM)
Bayesian Inference
Bayesian inference is a principled approach to statistical inference that relies on Bayes’ theorem to update prior beliefs about model parameters with observed data, yielding posterior distributions that quantify updated beliefs.
In Bayesian inference, prior distributions represent:
- Initial beliefs about model parameters before observing any data
- Likelihood functions capture the probability of observing the data given the model parameters
- Posterior distributions combine prior beliefs and observed evidence
Bayesian inference provides a flexible framework for incorporating prior knowledge, handling uncertainty, and making probabilistic predictions.
Variational Inference
Variational inference is a family of methods used to approximate complex posterior distributions, often intractable to compute analytically. It involves approximating the actual posterior distribution with a simpler, tractable distribution by minimizing the Kullback-Leibler (KL) divergence between the two distributions.
Variational inference seeks the best approximation to the true posterior within a predefined family of distributions, such as Gaussian or neural network-based distributions. It is widely used in Bayesian statistics, deep learning, and probabilistic graphical models.
Monte Carlo Methods
Monte Carlo methods are computational techniques for estimating numerical quantities by simulating random sampling from probability distributions. In machine learning, Monte Carlo methods are commonly used for approximating integrals, computing expectations, and sampling from complex probability distributions.
Markov chain Monte Carlo (MCMC) algorithms, such as Metropolis-Hastings and Gibbs sampling, are particularly popular for sampling from posterior distributions in Bayesian inference. Other Monte Carlo techniques, such as importance sampling, rejection sampling, and particle filtering, are used for various inference tasks, including probabilistic modeling and uncertainty estimation.
How Inference Techniques Power Smarter Predictions and Data-Driven Decisions
These techniques and methods for inference are essential in various machine learning applications. They can be used to make predictions, estimate uncertainties, and reason about complex probabilistic relationships in data. Whether in probabilistic modeling, Bayesian inference, or deep learning, these techniques provide powerful tools for extracting valuable insights from data and making informed decisions.
Related Reading
- Model Inference
- AI Learning Models
- MLOps Best Practices
- MLOps Architecture
- Machine Learning Best Practices
- AI Infrastructure Ecosystem
How Does Machine Learning Inference Work?

The inference process starts with preprocessing the input data, where it is transformed into a format that matches the model’s requirements. The machine learning model processes the input data to generate outputs.
Preprocessing Input Data
Machine learning models have specific requirements for the data used during inference. For instance, a model may expect a certain number of input features or require the input data to be normalized within a specific range.
A preprocessing phase transforms the input data to meet these requirements before being fed into the model. This process helps to ensure smooth operations during inference and that the model performs accurately.
Generating Outputs
Once the input data is prepared, the machine learning model processes the information to create outputs. Depending on the complexity of the model, this process can take anywhere from milliseconds to several seconds.
For example, if you have a simple linear regression model that predicts house prices, it might take only a few milliseconds to process a new data sample and generate an output. In contrast, a large natural language processing model can create a text output for several seconds.
An Example of ML Inference in Action
Machine learning inference can be illustrated with an example of image recognition. Suppose you have a trained model that can identify different types of animals in photos. First, the model would preprocess the input data, which would be an image file of a cat.
The model would transform the image to meet its requirements, such as a specific size and color format. The model would process the image to generate outputs. In this case, the output might be that there is an 85% chance the image contains a cat.
The Components of Machine Learning Inference
To deploy machine learning inference, you need three main components:
Data Source
A data source captures real-time data from an internal source managed by the organization, external sources, or application users. Common examples of data sources for ML applications are log files, transactions stored in a database, or unstructured data in a data lake.
Host System
The ML model’s host system receives data from data sources and feeds it into the ML model. It provides the infrastructure on which the ML model’s code can run. After the ML model generates outputs (predictions), the host system sends these outputs to the data destination.
Common examples of host systems are an API endpoint accepting inputs through a REST API, a web application receiving inputs from human users, or a stream processing application processing large volumes of log data.
Data Destination
The ML model targets the data destination, which can be any data repository, such as a database, a data lake, or a stream processing system that feeds downstream applications.
For example, a data destination could be the database of a web application, which stores predictions and allows them to be viewed and queried by end users. In other scenarios, the data destination could be a data lake, where predictions are stored for further analysis by big data tools.
What Is a Machine Learning Inference Server?
Machine learning inference servers, or engines, execute your model’s algorithm and return the inference output. These servers accept input data, pass it to a trained ML model, process it, and generate the output.
ML inference servers need model creation tools to export the model in a compatible file format so that it functions correctly.
Ensuring Model Portability
For instance, Apple’s Core ML inference server only reads models stored in the .mlmodel format. If your model is created using TensorFlow, you can convert it to the .mlmodel format using TensorFlow’s conversion tool.
To improve interoperability across different ML inference servers and model training environments, you can use the Open Neural Network Exchange (ONNX) format. ONNX is an open format for representing deep-learning models, enabling better portability between different ML inference servers and supporting tools from various vendors.
Hardware for Deep Learning Inference
The following hardware systems are commonly used to run machine learning and deep learning inference workloads.
Central Processing Unit (CPU)
A CPU can process instructions for performing a sequence of requested operations. It contains billions of transistors and powerful cores to handle massive operations and memory consumption. CPUs can support any operation without customized programs.
Here are the four building blocks of CPUs:
- The Control Unit (CU) directs the processor’s operations and informs other components how to respond to instructions sent to it.
- Arithmetic logic unit (ALU): performs bitwise logical operations and integer arithmetic. Address generation unit (AGU): calculates the addresses used to access the main memory.
- Memory management unit (MMU): any memory component the CPU uses to allocate memory. The universality of CPUs means they include superfluous logic verifications and operations.
CPUs do not fully exploit deep learning’s parallelism opportunities.
Graphical Processing Units (GPU)
GPUs are specialized hardware designed to perform many simple operations simultaneously. While GPUs and CPUs share similar spatial architectures, they differ significantly in structure and function. CPUs typically consist of a few Arithmetic Logic Units (ALUs) optimised for sequential processing, while GPUs feature thousands of ALUs that enable the parallel execution of many tasks simultaneously.
This parallel processing capability makes GPUs particularly well-suited for deep learning applications. GPUs are energy-intensive, which limits their use on edge devices that may not have sufficient power to support them.
Field Programmable Gate Array (FPGA)
FPGAs (Field-Programmable Gate Arrays) are specialized hardware that users can configure after manufacturing.
They consist of:
- An array of programmable logic blocks
- A hierarchy of configurable interconnections that allow for flexible wiring of blocks in different configurations
Challenges in Converting High-Level Programming Languages to FPGA Code
Users can write code in hardware description languages (HDLs) like VHDL or Verilog to define the connections and how digital components are implemented. FPGAs are highly efficient for performing numerous multiply-and-accumulate operations, making them ideal for implementing parallel circuits.
HDLs, which define hardware components like counters and registers, are not traditional programming languages, posing challenges, especially when converting a Python library into FPGA code.
Custom AI Chips (SoC and ASIC)
Custom AI chips provide hardware built especially for artificial intelligence (AI), such as Systems on Chip (SoCs) and application-specific integrated Circuits (ASICs) for deep learning. Companies worldwide are developing custom AI chips, dedicating many resources to creating hardware that can perform deep learning operations faster than existing hardware, like GPUs.
AI chips are designed for different purposes, built for training and customised for inference. Notable solutions include:
- Google’s TPU
- NVIDIA’s NVDLA
- Amazon’s Inferentia
- Intel’s Habana Labs
Optimizing AI Workflows: Leveraging Serverless Inference for High-Performance, Cost-Effective Language Models
Inference delivers OpenAI-compatible serverless inference APIs for top open-source LLM models, offering developers the highest performance at the lowest cost in the market. Beyond standard inference, Inference provides specialized batch processing for large-scale async AI workloads and document extraction capabilities designed explicitly for RAG applications.
Start building with $10 in free API credits and experience state-of-the-art language models that balance cost-efficiency with high performance.
Related Reading
- AI Infrastructure
- MLOps Tools
- AI as a Service
- Artificial Intelligence Cost Estimation
- AutoML Companies
- Edge Inference
- LLM Inference Optimization
Machine Learning Inference vs Training

In machine learning, training and inference are separate phases with distinct objectives. Training focuses on developing a model using data and algorithms like a kitchen preparing a recipe. Inference, resembling a restaurant's dining area, emphasizes delivering accurate and timely predictions to users.
Understanding the difference between these phases is crucial. Cassie Kozyrkov's restaurant analogy effectively illustrates this: a valuable product (pizza) requires a well-defined recipe (model) and quality ingredients (data), prepared with appropriate appliances (algorithms).
Integrating Training and Inference
Just as a restaurant needs a functioning kitchen and a pleasant dining area, machine learning projects require practical training and inference. There is no service without a reliable kitchen (data science team). A kitchen is only valuable if customers appreciate its output.
The training and inference processes must be seamlessly integrated and continuously optimized for optimal customer experience and return on investment.
What Happens in Machine Learning Training?
Training a machine learning model requires the use of training and validation data. The training data is used to develop the model, whereas the validation data is used to fine-tune the model’s parameters and make it as robust as possible. This means that at the end of the training phase, the model should be able to predict new data with fewer errors. We can consider this phase as the kitchen side.Our comprehensive guide, What Is Machine Learning, explains machine learning, how it differs from AI and deep learning, and why it is one of the most exciting fields in data science.
What Happens in Machine Learning Inference?
Dishes can only be served when ready to be consumed, just as the machine learning model needs to be trained and validated before it can be used to make predictions. Machine learning inference is similar to the scenario of a restaurant. Both require attention for better and more accurate results, hence customer and business satisfaction.
Why Understanding the Differences Is Important
Knowing the difference between machine learning inference and training is crucial because it can help better allocate computation resources for training and inference once deployed into the production environment. Model performance usually decreases in the production environment. Proper understanding of this difference can help in adopting the right industrialization strategies for the models and maintaining them over time.
Key Considerations When Choosing Between Inference and Training
Whether an inference model is used or a brand new model is trained depends on the type of problem, the end goal, and the existing resources. The key considerations include, but are not limited to:
- Time to market: It is essential to consider how much is available when choosing between training and using an existing model. Using a pre-trained model requires less time and may give a business team a competitive advantage.
- Resources constraints or development cost: Training a model can require significant data and training resources depending on the use case. Using an inference model usually requires fewer resources, which makes it easier to obtain even better performance in a short amount of time.
- Model performance: Training a machine learning model is an iterative process that does not always guarantee a robust model. Using an inference model can provide better performance than an in-house model. Nowadays, model explainability and bias mitigation are crucial, and inference models may need to be updated to consider those capabilities.
- Team expertise: Building a robust machine learning model requires strong expertise for model training and industrialization. It can be challenging to have that expertise already available; hence, relying on inference models can be the best alternative.
Best Practices for Inference
Model Evaluation and Validation
Effective model evaluation and validation are crucial for ensuring the reliability and generalization of inference results. This involves splitting the dataset into training, validation, and testing sets to assess the model’s performance on unseen data. Metrics such as accuracy, precision, recall, F1-score, and area under the curve (AUC) are commonly used to evaluate classification models.
At the same time, these elements are used for regression tasks:
Cross-validation techniques such as k-fold cross-validation and stratified cross-validation can provide more robust estimates of model performance by mitigating the impact of data variability.
Hyperparameter Tuning
Hyperparameters are crucial in determining machine learning models’ performance and generalization ability. Through systematic experimentation and optimization, hyperparameter tuning involves selecting the optimal values for parameters such as:
- Learning rate
- Regularization strength
- Tree depth
- Batch siz
Techniques such as grid search, random search, and Bayesian optimization are commonly used for hyperparameter tuning to find the best configuration that maximizes model performance while avoiding overfitting.
Interpretability and Explainability
Interpretability and explainability are essential to inference, especially in domains where model decisions have significant real-world consequences, such as healthcare, finance, and criminal justice. Interpretability refers to the ability to understand and explain how a model makes predictions or classifications, while explainability involves providing transparent insights into the factors and features that influence model outputs.
Techniques such as feature importance analysis, model-agnostic methods (e.g., SHAP, LIME), and surrogate models can help improve the interpretability and explainability of machine learning models, enabling stakeholders to trust and understand the underlying mechanisms driving inference results.
3 Primary Challenges & Solutions When Setting Up ML Inference

1. Infrastructure Cost: Managing the Cost of Inference
Inference can be costly. Machine learning models require significant computational resources to produce outputs. For this reason, huge models can require thousands of dollars in computing resources to run just once. Organizations pay to run ML inference workloads in data centers or cloud environments that charge for the underlying compute resources.
It’s essential to ensure that inference workloads fully utilize the available hardware infrastructure, minimizing the cost per inference. One way to do this is to run queries concurrently or in batches.
For example, when an ML model is deployed on a server, it can quickly respond to multiple incoming queries simultaneously. Instead of answering each request individually, the model can process the queries together, which reduces the overall latency and cost of inference.
2. Latency: Reducing Inferencing Delay
Like any other software application, machine learning models require time to produce output when called upon. This delay is known as latency, and it can significantly impact the performance of inference systems. A common requirement for inference systems is maximal latency: The lower the latency, the better.
Mission-critical applications often require real-time inference. Examples include autonomous navigation, critical material handling, and medical equipment. Some use cases can tolerate higher latency. For example, some significant data analytics use cases do not require an immediate response. You can run these analyses in batches based on the frequency of inference queries.
3. Interoperability: Simplifying the Model Deployment Process
When developing ML models, teams use frameworks like:
- TensorFlow
- PyTorch
- Keras
Different teams may use various tools to solve their specific problems. When running inference in production, these other models must play well together. Models may need to run in diverse environments, including on client devices, at the edge, or in the cloud. Containerization has become a common practice that can ease the deployment of models to production.
Many organizations use Kubernetes to deploy large-scale models and organize them into clusters. Kubernetes makes it possible to deploy multiple instances of inference servers and scale them up and down as needed across public clouds and local data centers.
Start building with $10 in Free API Credits Today!
Inference, in machine learning, is the process of making predictions on new data using a previously trained model. Inference is crucial because it is how machine learning models create value. For example, a model may predict which customers will likely churn.
It doesn’t do anything until it is deployed and someone runs inference on the model with data about the current customer base. When that process can be completed quickly, the business can act on the results and mitigate churn. Slow inference speeds can hinder the decision-making process and drastically reduce the value of a machine learning model.
Related Reading
Meet with our research team
Schedule a call with our research team to learn more about how Specialized Language Models can cut costs and improve performance.