'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
May 20, 2025
Is TensorRT the Best LLM Inference Engine? A Head-To-Head Comparison
Inference Research
As deep learning models grow more complex, getting the best performance possible during inference is crucial. Slowdowns during inference can waste time and resources, often negating the benefits of using more advanced models in the first place. This article will explain how TensorRT can help you achieve your goals, like finding the fastest, most efficient LLM inference engine that minimizes cost, maximizes throughput, and seamlessly scales for real-world AI applications. Understanding AI Inference vs Training is essential to optimizing performance and making informed decisions when deploying deep learning models.
One way to think about inference is to think of it as running a race. You train for weeks or months to improve your performance. But when it comes time to run the race, you want to be able to complete it as quickly as possible. In an AI inference APIs, this “race” is the execution of a trained model, which occurs after a user prompts the system for information. TensorRT is designed to make this process as fast as possible.
TensorRT Key Features and Use Cases

Graph Optimization
TensorRT performs graph optimizations by restructuring deep learning models for better efficiency. It fuses compatible layers, eliminates redundant computations, and reorders operations to maximize performance.
For example, two consecutive convolutional layers can be merged into one, reducing computation time. By optimizing the model graph, TensorRT ensures that neural networks run faster without altering their accuracy.
Precision Calibration
TensorRT supports lower-precision numerical formats such as FP16 and INT8. These formats consume less memory and require fewer computational resources, resulting in faster inference speeds.
TensorRT applies quantization techniques to maintain accuracy, ensuring minimal precision loss when converting models from FP32 to FP16 or INT8. This is particularly useful for edge devices with limited computing power.
Dynamic Tensor Memory
TensorRT optimizes memory allocation by dynamically managing tensors during inference. Instead of reserving a fixed amount of memory for all tensors, it allocates only what is needed at a given moment. This reduces overall memory consumption and allows models to run efficiently, even on GPUs with limited resources.
Kernel Auto-Tuning
TensorRT automatically selects the best GPU kernels based on the hardware it runs on. Different NVIDIA GPUs have different architectures, and manually optimizing for each one can be complex. TensorRT simplifies this process by analyzing the model and choosing the most efficient kernel configurations for optimal performance.
Advanced Performance Optimization
The core of it all is the TensorRT LLM performance. Developers can achieve heavy speed-ups while maintaining model accuracy using GPU acceleration and more advanced features such as TensorRT LLM quantization.
Quantization plays a vital role in compressing models, lowering computational needs, and ensuring real-time inference for large-scale applications.
Speculative Decoding
Easily, one of the best improvements over other tools in TensorRT-LLM is TensorRT LLM speculative decoding. Speculative decoding can predict multiple outputs simultaneously, massively lowering latency during inference.
Improving the decoding process ensures users experience faster responses in applications like:
- Chatbots
- Virtual assistants
- Real-time content generation
Retrieval-Augmented Generation (RAG)
One of TensorRT's more advanced features is retrieval-augmented generation, commonly known as RAG. RAG combines language model abilities with external knowledge retrieval, improving the accuracy and relevance of generated replies.
Scalable, Distributed Deployment
TensorRT-LLM makes scaling LLMs across a couple of GPUs or systems easy. NVIDIA is arguably one of the best in the GPU field, and its expertise in distributed computing ensures that even the largest models can be efficiently deployed. TensorRT LLM performance is optimized for scalability, making it an excellent choice for those seeking to use heavy AI tools at scale.
Integration with Deep Learning Frameworks
TensorRT integrates with popular deep learning frameworks like TensorFlow and PyTorch, allowing developers to optimize and deploy models with minimal effort. NVIDIA provides TensorRT parsers that convert trained models into a format compatible with the TensorRT runtime.
Developers can use TensorRT’s standalone API or integrate it directly with TensorFlow (via TensorFlow-TensorRT, or TF-TRT) and PyTorch (via Torch-TensorRT). These integrations make transitioning from training to deployment easier without major code modifications.
Use Cases of TensorRT
- Autonomous Vehicles: Self-driving cars require real-time processing to detect objects, recognize traffic signs, and make navigation decisions. TensorRT enables fast inference for deep learning models used in autonomous systems. Its low-latency optimizations ensure that perception models process sensor data quickly, allowing vehicles to react instantly.
- Medical Imaging: Medical applications use deep learning for disease detection, image segmentation, and anomaly identification. TensorRT speeds up model inference, allowing medical professionals to analyze images faster. In scenarios like tumor detection from MRI scans, reduced inference time means quicker diagnoses and improved patient outcomes.
- Natural Language Processing (NLP): Large language models (LLMs) require high computational power for inference. TensorRT-LLM introduces optimizations like custom attention kernels and quantization techniques to accelerate NLP tasks. This benefits applications like:
- Chatbots
- Automated translation
- Real-time text analysis
TensorRT Benefits
- Increased Inference: Speed TensorRT significantly reduces inference latency, ensuring real-time performance for AI applications. Faster inference enables smoother user experiences in AI-powered applications like:
- Voice assistants
- Autonomous vehicles
- Video analytics
- Reduced Latency: Low latency is critical in applications that require immediate responses. TensorRT optimizes execution time, making AI-driven decisions faster. This is crucial for:
- Fraud detection
- Robotics control
- Stock market predictions
- Optimized Resource Utilization: TensorRT minimizes memory usage and computational requirements by applying techniques like layer fusion and precision calibration. This allows AI models to run efficiently on high-end GPUs and resource-constrained devices.
- Hardware Acceleration: TensorRT is designed to utilize NVIDIA GPUs fully. Its optimizations ensure that deep learning models run as efficiently as possible, making it the preferred choice for AI applications deployed on NVIDIA hardware.
- Deployment Readiness: TensorRT provides a production-ready runtime environment. It enables developers to confidently deploy deep learning models, knowing they will perform efficiently without requiring extensive manual tuning.
TensorRT for RTX

What Are AI PCs and Why Do They Matter?
Artificial intelligence workloads require a lot of power. The more powerful your hardware, the faster AI tasks will run. The emergence of "AI PCs" aims to leverage high-performance consumer PCs, specifically, those with NVIDIA GeForce RTX GPUs, to accelerate AI tasks.
An AI PC can help developers, researchers, and creatives run AI models locally without cloud dependency, significantly improving performance and reducing latency.
A Closer Look at NVIDIA's Modular Software Stack for AI PCs
At Computex 2025, NVIDIA presented its modular software stack for so-called "AI PCs" -- a concept that primarily aims to transform commercially available PC systems with RTX graphics cards into locally deployable AI computing stations.
The presented stack consists of several components that interlock at different levels of the workflow:
- CUDA is a programming interface and base layer for parallel computing on GPUs,
- TensorRT is an optimized inference backend
- OptiX is for ray-tracing-based image calculation
- Maxine is for audio and video AI features
- Riva is for speech and text processing
- Broadcast SDKs are for streaming and communication applications
This stack is complemented by many specialized software development kits (SDKs) aimed at:
- Developers
- Creative professionals
- AI researchers
TensorRT for RTX: What Is It?
With "TensorRT for RTX," NVIDIA presents a further developed inference backend at Computex 2025 specifically tailored to consumer and developer devices with RTX graphics cards. At its core, it is a variant of the TensorRT framework known from the data center sector.
Now, it focuses on local, GPU-accelerated execution of AI models in the end-user area. The special feature lies in the so-called just-in-time optimization: models are not only compiled once, but dynamically adapted to the respective RTX GPU, including:
- Architecture variants
- Memory expansion
- Available computing units
Optimized Performance
The library offers a performance boost of over 50% compared to baseline DirectML, as demonstrated on the GeForce RTX 5090. It also supports native acceleration of FP4 and FP8 computations on NVIDIA Tensor Cores, unlocking higher throughput for AI workloads.
Streamlined Developer Experience
TensorRT for RTX employs just-in-time (JIT) compilation, optimizing neural networks for RTX GPUs within seconds. This process, which occurs during application installation, supports a range of models, including:
- CNNs
- Audio
- Diffusion
- Transformer models
The library's efficient compilation process is designed to enhance developer workflows for PC AI use cases.
Broader Implications and Availability
TensorRT for RTX's introduction coincides with Microsoft's Build conference. The library is currently available in the Windows ML public preview. A standalone version will be available in June from NVIDIA's developer portal.
The library promises to reduce build times and improve runtime performance, offering a leap forward in AI inference capabilities on Windows platforms.
What is NVIDIA TensorRT, and How Does It Perform LLM Optimization?

NVIDIA TensorRT is a high-performance deep learning inference library optimized for NVIDIA GPUs. It enhances LLM (Large Language Model) performance by leveraging techniques like quantization, kernel fusion, and efficient memory management. Specifically, it optimizes transformer-based architectures, improving speed, efficiency, and scalability.
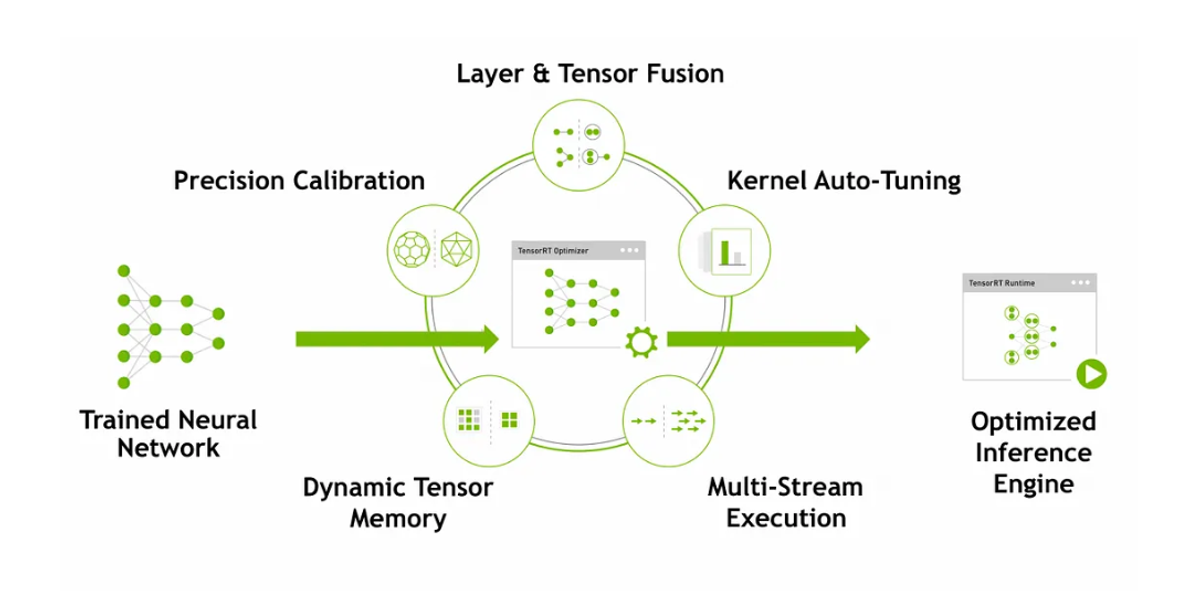
Weight and Activation Precision Calibration
During the training process, parameters and activations are in FP32 (Floating Point 32) precision. To convert them to FP16 or INT8 precision, this optimization reduces latency and model size because FP32 precision is converted into FP16 or INT8.
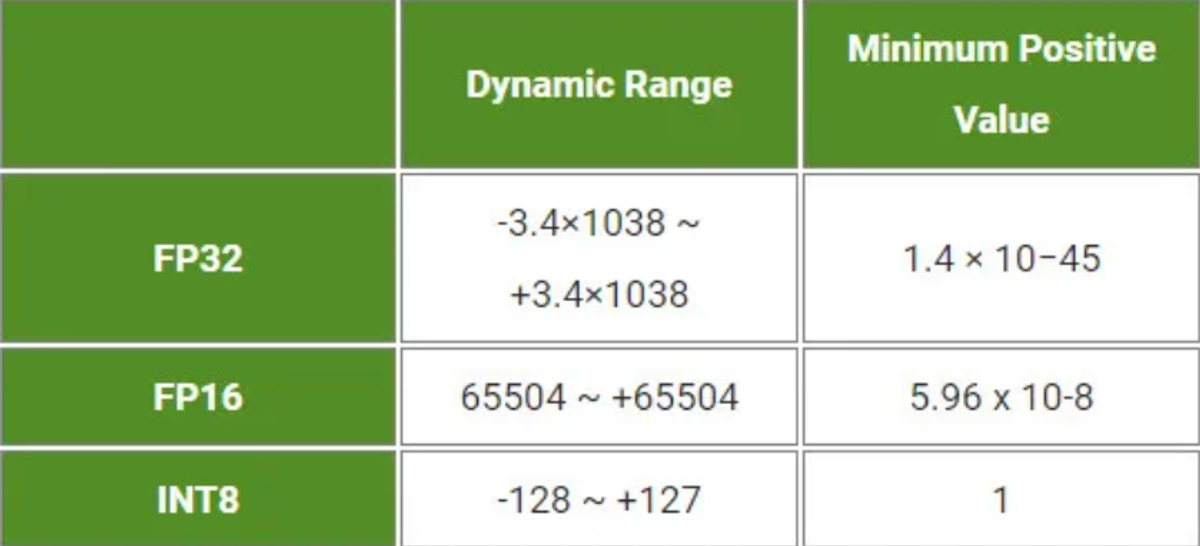
While converting to FP16 (lower precision), some of our weights will be shrunk due to overflow, as the dynamic range of FP16 is lower than that of FP32. But experimentally, this doesn’t affect the accuracy significantly. But how do we justify that? We know FP32 is high precision. Weights and activation values, in general, are resilient to noise. While training, the model tries to preserve the features necessary for inference.
Managing Precision Loss in INT8 Model Conversion
Throwing out unnecessary stuff is a built-in process. While we convert the model to lower precision, we assume that the model throws out noise. This similar technique of clipping overflowing weights won’t work while converting to INT8 precision.
Because INT8 values are minimal, ranging from [-127 to +127], most of our weights will get modified and overflow in lower precision, resulting in a significant drop in our model's accuracy. We map those weights in INT8 precision using scaling and bias terms.
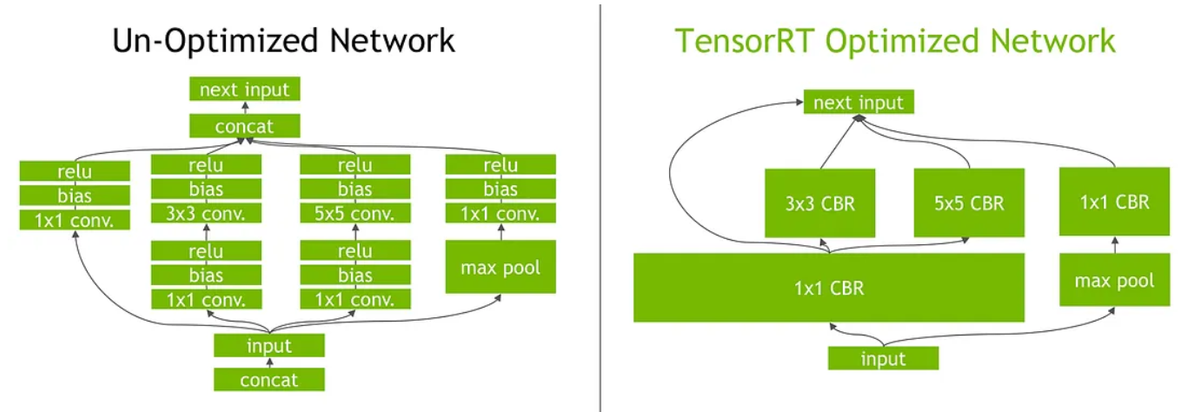
Layers and Tensor Fusion
Any deep learning framework must perform a similar computation routinely while executing a graph. To overcome this, TensorRT uses layer and tensor fusion to optimize the GPU memory and bandwidth by fusing nodes in a kernel vertically or horizontally (or both), which reduces the overhead and cost of reading and writing the tensor data for each layer.
This is a simple analogy: Instead of buying three items from the market in three trips, we do a single trip and buy all three items. As shown above, TensorRT recognizes all layers with similar input and filter sizes but different weights and combines them to form a 1x1 CBR layer.
Kernel Auto Tuning
While optimizing models, some kernel-specific optimizations can be performed. This selects the best layers, algorithms, and optimal batch size based on the target GPU platform. For example, there are multiple ways of performing convolution operations, but which one is the most optimal on this selected platform? TRT opts for that automatically.
Dynamic Tensor Memory
TensorRT improves memory reuse by allocating memory to a tensor only for the duration of its usage. It helps reduce memory footprints and avoid allocation overhead for fast and efficient execution.
Multiple Stream Execution
TensorRT is designed to process multiple input streams in parallel. This is Nvidia’s CUDA stream.
Related Reading
- Model Inference
- AI Learning Models
- MLOps Best Practices
- MLOps Architecture
- Machine Learning Best Practices
- AI Infrastructure Ecosystem
Is TensorRT the Best LLM Inference Engine? TensorRT vs vLLM vs LMDeploy vs MLC-LLM

TensorRT-LLM is another inference engine that accelerates and optimizes inference performance for the latest LLMs on NVIDIA GPUs. LLMs are compiled into TensorRT Engine and then deployed with a Triton server to leverage inference optimizations such as In-Flight Batching (which reduces wait time and allows higher GPU utilization), paged KV caching, multiGPU-multiNode inference, and FP8 Support.
Usage
We will compare the execution time, ROUGE scores, latency, and throughput across the HF, TensorRT, and TensorRT-INT8 models (quantized).
You need to install Nvidia-container-toolkit for your Linux system, initialize Git LFS (to download HF Models), and download the necessary packages as follows:
```bash
!curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
!apt-get update
!git clone https://github.com/NVIDIA/TensorRT-LLM/
!apt-get update && apt-get -y install python3.10 python3-pip openmpi-bin libopenmpi-dev
!pip3 install tensorrt_llm -U --pre --extra-index-url https://pypi.nvidia.com
!pip install -r TensorRT-LLM/examples/phi/requirements.txt
!pip install flash_attn pytest
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash
!apt-get install git-lfs
```Now Retrieve The Model Weights
```bash
PHI_PATH="TensorRT-LLM/examples/phi"
!rm -rf $PHI_PATH/7B
!mkdir -p $PHI_PATH/7B && git clone https://huggingface.co/microsoft/Phi-3-small-128k-instruct $PHI_PATH/7B
```Convert the model into TensorRT-LLM checkpoint format and and build the TensorRT-LLM from the checkpoint.
```bash
!python3 $PHI_PATH/convert_checkpoint.py --model_dir $PHI_PATH/7B/ \
--dtype bfloat16 \
--output_dir $PHI_PATH/7B/trt_ckpt/bf16/1-gpu/
Build TensorRT-LLM Model From Checkpoint
!trtllm-build --checkpoint_dir $PHI_PATH/7B/trt_ckpt/bf16/1-gpu/ \
--gemm_plugin bfloat16 \
--output_dir $PHI_PATH/7B/trt_engines/bf16/1-gpu/
```INT8 weight-only quantization is now applied to the HF model, and the checkpoint is converted into TensorRT-LLM.
```bash
!python3 $PHI_PATH/convert_checkpoint.py --model_dir $PHI_PATH/7B \
--dtype bfloat16 \
--use_weight_only \
--output_dir $PHI_PATH/7B/trt_ckpt/int8_weight_only/1-gpu/
!trtllm-build --checkpoint_dir $PHI_PATH/7B/trt_ckpt/int8_weight_only/1-gpu/ \
--gemm_plugin bfloat16 \
--output_dir $PHI_PATH/7B/trt_engines/int8_weight_only/1-gpu/
```Test The Base Phi3 And Two Tensorrt Models on the Summarization Task
```bash
%%capture phi_hf_results
Huggingface
!time python3 $PHI_PATH/../summarize.py --test_hf \
--hf_model_dir $PHI_PATH/7B/ \
--data_type bf16 \
--engine_dir $PHI_PATH/7B/trt_engines/bf16/1-gpu/
%%capture phi_trt_results
TensorRT-LLM
!time python3 $PHI_PATH/../summarize.py --test_trt_llm \
--hf_model_dir $PHI_PATH/7B/ \
--data_type bf16 \
--engine_dir $PHI_PATH/7B/trt_engines/bf16/1-gpu/
%%capture phi_int8_results
TensorRT-LLM (INT8)
!time python3 $PHI_PATH/../summarize.py --test_trt_llm \
--hf_model_dir $PHI_PATH/7B/ \
--data_type bf16 \
--engine_dir $PHI_PATH/7B/trt_engines/int8_weight_only/1-gpu/
```After capturing the results, you can parse the output and plot it to compare execution time, ROUGE scores, latency, and throughput across all models.
vLLM: Fast Inference and Serving for LLMs
vLLM offers LLM inferencing and serving with SOTA throughput, Paged Attention, Continuous batching, Quantization (GPTQ, AWQ, FP8), and optimized CUDA kernels.
Usage
Let’s evaluate the throughput and latency of microsoft/Phi3-mini-4k-instruct. Start by setting up dependencies and importing libraries.
```bash
!pip install -q vllm
!git clone https://github.com/vllm-project/vllm.git
!pip install -q datasets
!pip install transformers scipy
from vllm import LLM, SamplingParams
from datasets import load_dataset
import time
from tqdm import tqdm
from transformers import AutoTokenizer
```Let’s Load The Model and Generate its Outputs on a Small Slice of The Dataset.
```python
dataset = load_dataset("akemiH/MedQA-Reason", split="train").select(range(10))
prompts = []
for sample in dataset:
prompts.append(sample)
sampling_params = SamplingParams(max_tokens=524)
llm = LLM(model="microsoft/Phi-3-mini-4k-instruct", trust_remote_code=True)
def generate_with_time(prompt):
start = time.time()
outputs = llm.generate(prompt, sampling_params)
taken = time.time() - start
generated_text = outputs[0].outputs[0].text
return generated_text, taken
generated_text = []
time_taken = 0
for sample in tqdm(prompts):
text, taken = generate_with_time(sample)
time_taken += taken
generated_text.append(text)
Tokenize The Outputs and Calculate The Throughput
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
token = 1
For sample in generated_text:
tokens = tokenizer(sample)
tok = len(tokens.input_ids)
token += tok
print(token)
print("tok/s", token // time_taken)
```Let’s benchmark the model’s performance through vLLM on the ShareGPT dataset.
```bash
!wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
%cd vllm
!python benchmarks/benchmark_throughput.py --backend vllm --dataset ../ShareGPT_V3_unfiltered_cleaned_split.json --model microsoft/Phi-3-mini-4k-instruct --tokenizer microsoft/Phi-3-mini-4k-instruct --num-prompts=1000
```LMDeploy: Efficient Inference and Deployment for LLMs
This package also allows compressing, deploying, and serving LLMs while offering:
- Efficient inference (persistent batching
- Blocked KV cache
- Dynamic split&fuse
- Tensor parallelism
- High-performance CUDA kernels)
- Effective quantization (4-bit inference performance is 2.4x higher than FP16)
- Effortless distribution server (deployment of multi-model services across multiple machines and cards)
- Interactive inference mode (remembers dialogue history and avoids repetitive processing of historical sessions)
It also allows for profiling token latency and throughput, request throughput, API server, and triton inference server performance.
Usage
Install dependencies and import packages.
```bash
!pip install -q lmdeploy
!pip install nest_asyncio
import nest_asyncio
nest_asyncio.apply()
!git clone --depth=1 https://github.com/InternLM/lmdeploy
%cd lmdeploy/benchmark
```LMdeploy has developed two inference engines, TurboMind and PyTorch.
Let’s profile the PyTorch engine on microsoft/Phi3-mini-128k-instruct.
```bash
!python3 profile_generation.py microsoft/Phi-3-mini-128k-instruct --backend pytorch
```It profiles the engine over multiple rounds and reports the token latency & throughput for each round.
MLC-LLM: A High Performance Deployment and Inference Engine
MLC-LLM offers a high performance deployment and inference engine, called MLCEngine.
Usage
Let’s install dependencies which includes setting up dependencies with conda and creating a conda environment. Then clone the git repository and configure.
```bash
conda activate your-environment
python -m pip install --pre -U -f https://mlc.ai/wheels mlc-llm-nightly-cu121 mlc-ai-nightly-cu121
conda env remove -n mlc-chat-venv
conda create -n mlc-chat-venv -c conda-forge \
"cmake>=3.24" \
rust \
git \
python=3.11
conda activate mlc-chat-venv
git clone --recursive https://github.com/mlc-ai/mlc-llm.git && cd mlc-llm/
mkdir -p build && cd build
python ../cmake/gen_cmake_config.py
cmake .. && cmake --build . --parallel $(nproc) && cd ..
set(USE_FLASHINFER ON)
conda activate your-own-env
cd mlc-llm/python
pip install -e .
```We need to convert model weights into MLC format to run a model with MLC LLM. Download the HF model to by Git LFS then convert weights.
```bash
mlc_llm convert_weight ./dist/models/Phi-3-small-128k-instruct/ \
--quantization q0f16 \
--model-type "phi3" \
-o ./dist/Phi-3-small-128k-instruct-q0f16-MLC
```Now load your MLC format model into the MLC engine
```python
from mlc_llm import MLCEngine
Create engine
model = "HF://mlc-ai/Phi-3-mini-128k-instruct-q0f16-MLC"
engine = MLCEngine(model)
Let’s Calculate Throughput
Let’s Calculate Throughput
import time
from transformers import AutoTokenizer
start = time.time()
response = engine.chat.completions.create(
messages=[{"role": "user", "content": "What is the Machine Learning?"}],
model=model,
stream=False,
)
taken = time.time() - start
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-128k-instruct")
print("tok/s", 82 // taken)
```Summary
TensorRT INT8 models outperform HF models and regular TensorRT with respect to inference speed while the regular TensorRT model performed better on the summarization task with the highest ROUGE score among the three models. LMDeploy delivers up to 1.8x higher request throughput than vLLM on an A100.
Related Reading
- AI Infrastructure
- MLOps Tools
- AI as a Service
- Machine Learning Inference
- Artificial Intelligence Cost Estimation
- AutoML Companies
- Edge Inference
- LLM Inference Optimization
Start Building with $10 in Free API Credits Today!
Inference delivers OpenAI-compatible serverless inference APIs for top open-source LLM models, offering developers the highest performance at the lowest cost in the market. Beyond standard inference, Inference provides specialized batch processing for large-scale async AI workloads and document extraction capabilities designed explicitly for RAG applications.
Start building with $10 in free API credits and experience state-of-the-art language models that balance cost-efficiency with high performance.
Related Reading
Meet with our research team
Schedule a call with our research team to learn more about how Specialized Language Models can cut costs and improve performance.